前言
anchor-based的目标检测方法存在几个缺点:(1) anchor会引入额外的超参数,比如anchor的个数、尺度和长宽比;(2) anchor的存在降低了模型的泛化能力。比如,人脸检测需要的anchor一般都是方形居多,而检测行人需要一些瘦高的anchor;(3) 正负样本之间存在极端的不平衡。
也有一些方法对anchor做出了一些改进:
- MetaAnchor通过任意的自定义的prior box动态地生成anchor function;
- Guided-Anchoring同时预测目标中心点可能存在的位置,以及不同位置上anchor的尺度和长宽比
- 在《Anchor box op- timization for object detection》一文中提出动态地学习anchor的形状。
但是,这些工作依然依赖于可能的anchor尺度和长宽比的列举,来优化模型。
我们人类的视觉系统在辨别视野中的目标时,是不需要任何事先定义好的候选框的。基于这一点,本文提出了FoveaBox。FoveaBox是受到人眼的中央凹的启发:视野(目标)的中心具有最高的视敏度。FoveaBox预测目标的中心区域可能存在的位置,以及在该位置上的bbox。作者将FPN和本文中提出的detection head结合起来,形成FoveaBox的框架,其中能达到最好效果的模型是基于ResNeXt-101-fpn这一主干网络,它在COCO上达到了42.1的AP。
FoveaBox对于bbox的分布具有更强的鲁棒性。也就是说,当输入图像中的目标尺度变化很大时,预测的bbox依然很准确。为了验证这一点,作者手动拉长输入图像以及验证集的注释,将FoveaBox的鲁棒性与anchor-based的模型进行比较,FoveaBox表现得更好。
FoveaBox
FoveaBox包括一个主干网络和两个任务不同的子网。主干网络负责从输入图像上计算出卷积特征图,用的是现成的网络。第一个子网在主干网络输出的特征图上进行逐像素分类,第二个子网在相应的位置上进行bbox预测。FoveaBox的设计参考了RetinaNet。

1. FPN主干网络
FoveaBox采用FPN作为主干网络。对于一个单一尺度的输入图像,FPN通过top-down通路和横向连接构建了一个特征金字塔,可以对不同尺度的目标进行检测。本文构建的特征金字塔层级是从
到
,每个层级
对输入图像做
的降采样。所有层级的通道数都是
。

2. 尺度划分
对于多尺度物体的检测,FoveaBox将目标的尺度划分为几个范围。首先对于
到
,每层都有一个基础尺度
,让
,那么
计算为:

然后,为了使每一层负责检测特定尺度的目标,对每个特征层级
计算一个目标的有效尺度范围:

其中
用来控制每层的有效尺度范围。在训练时如果一个目标的尺度不在对应的尺度范围内,就忽略这个目标。当
时,每个尺度范围不会重叠;当
增大时,尺度范围会发生重叠,此时一个目标将会在多个特征图上进行检测。作者通过实验发现,
时的检测性能最好,如下表所示:

2. 正负样本的选择
在anchor-based的检测器中,会出现位置定义模糊问题。也就是说,特征图的每个位置上都有 个anchor,它们中有的是正样本,有的是负样本,那么分类器在工作的时候不仅要区分不同位置的样本,还要区分同一位置上的正负样本。在FoveaBox中,在每个位置明确地预测一个分类结果,这就避免了anchor中的模糊问题。
如果单纯的将gt box内的点作为正样本,一些在gt box边框附近的点是远离目标中心的,甚至与背景像素更为接近,如果将这些点也作为正样本,会对模型的训练造成困难;如果将其作为负样本,依然会出现上述的模糊问题。因此FoveaBox采用以下方式确定正负样本,增加正负样本之间的判别度。
设一个gt box为 ,分别表示左上和右下的坐标。首先将gt box用步长为 映射到目标所在的特征层级 中,其中 和 表示映射后的gt box的中心点坐标。
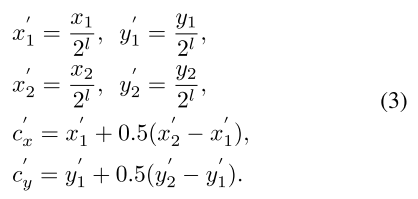
正样本的选择:用一个缩放因子
调节映射后的gt box的宽和高,使其向目标中心收缩一点,收缩后的gt box内部的每一个点都作为正样本。在训练时每个点的类别标签与gt box中目标的类别标签相同。
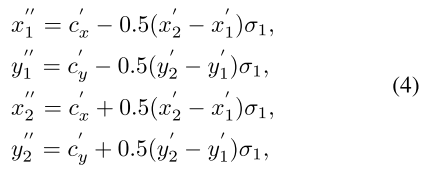
负样本的选择:用另一个缩放因子 根据式(4)再次调节映射后的gt box的宽和高,使其向外扩展一点,将扩展到gt box边框外部的点作为负样本。
通过 和 缩放后的两个边框之间的点,在训练时被忽略掉。由于正样本只占整个特征图的一小部分,为了处理正负样本间的不平衡,用focal loss作为分类分支的损失函数。
通过对分类分支进行修改,可以使其生成候选区域,并且实验证明,以这种方式生成的候选区域比RPN的AR(averagr recall)更高,作者认为这或许可以在未来提高two-stage检测器的性能。
3. 边界框预测
在训练时,首先将特征图上属于正样本的点的坐标映射到原始输入图像上,然后得到它与gt box之间的偏移值,对偏移值进行归一化处理后,最后用log空间函数进行正则化处理得到最终的结果:

其中
是归一化因子,最后得到的结果其实是预测的box与gt box之间的一个映射关系。FoveaBox采用Smooth
loss作为回归分支的损失函数。经过训练可以为每个特征图上的正样本点生成边界框。
Inference
- 首先,用阈值为0.05的置信度过滤掉低置信度的bbox;
- 然后,在每个特征层级中选择前1000个bbox;
- 接着,分别对每个类别进行阈值为0.5的NMS处理;
- 最后每个图像得到100个预测结果。
