一、什么是Hadoop?
- Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,
为用户提供了系统底层细节透明的分布式基础架构 - Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且
可以部署在廉价的计算机集群中 - Hadoop被公认为行业大数据标准开源软件,在分布式环境下提
供了海量数据的处理能力 - 几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商
业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,
都支持Hadoop
二、hadoop的特征
- 高可靠性
- 高效性
- 高可扩展性
- 成本低
- 运行在linux系统上,支持多种编程语言:java,python,scala
- 可迁移性强
三、hadoop框架架构
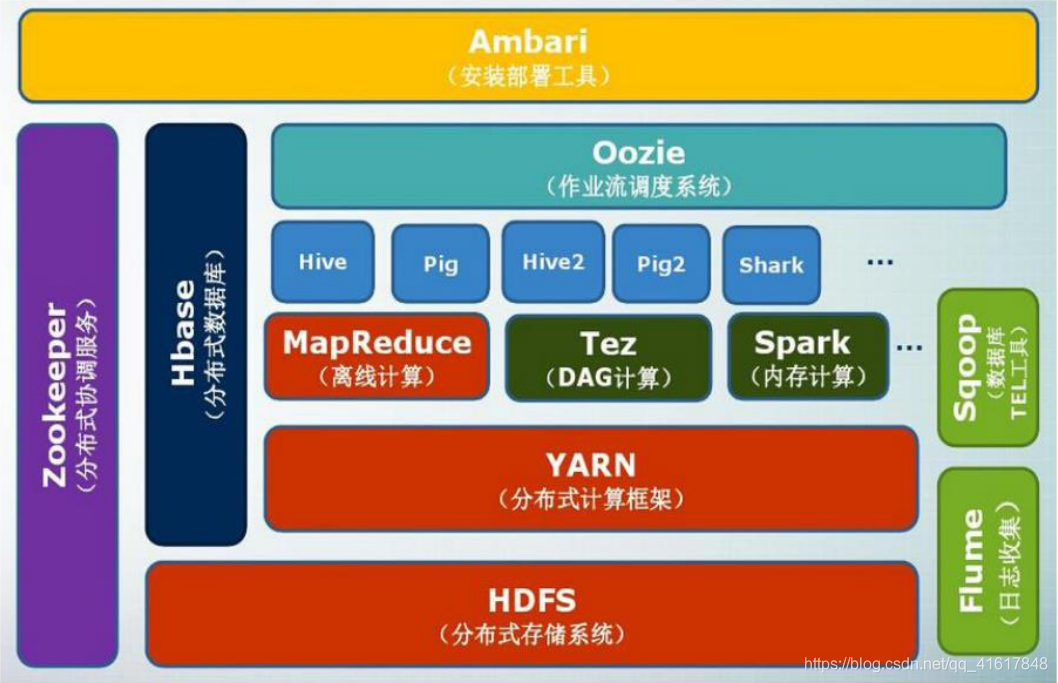
底层由hdfs作为分布式的文件管理系统,使用yarn进行资源调度管理,计算框架包含MapReduce、Spark等,数据库多用于Hbase,整个框架也可以用在Flume和其他平台上进行综合开发。
hadoop官方网站:hadoop
在官方网站上可以直接下载hadoop平台。
四、Hadoop的安装和使用
1.hadoop的安装方式:
- 单机模式:Hadoop 默认模式为非分布式模式(本地模式),无需
进行其他配置即可运行,非分布式即单 Java 进程,方便进行调试运行。 - 伪分布模式:hadoop可以在单节点上以伪分布式的方式运行,hadoop进程以分离的java进程来运行,节点既作为NameNode也作为DataNode,同时读取的也是hdfs上的文件。
- 分布式模式:使用多个节点构成集群环境来运行hadoop,可以使用多个虚拟机在一台电脑上模拟分布式模式,也可以用多台电脑组成一个物理上的集群运行hadoop。
2.hadoop的安装步骤
- 安装Virtural Box
- 安装Ubuntu
- 创建Hadoop用户
- SSH登录权限设置
- 安装Java环境
- 单机安装配置
- 伪分布式安装配置
下面给出各种方式下的搭建步骤:
- 单机安装配置:
(1) 首先下载hadoop的.gz文件到/usr/local中
(2) 解压该文件到该文件夹,并给这个文件夹赋予权限:
$ sudo tar -zxvf ~/下载/hadoop-x.x.x.tar.gz -C /usr/local
$cd /usr/local/
$sudo mv ./hadoop-x.x.x/ ./hadoop # 将文件夹名改为hadoop
$sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
hadoop解压后查看是否能够使用
$ cd /usr/local/hadoop
$./bin/hadoop version
如果可以使用,则会显示hadoop的版本信息,因为hadoop的默认运行就是为非分布式模式(本地模式),无需配置就可以运行。
- 伪分布式安装配置:
(1)Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分
离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,
同时,读取的是 HDFS 中的文件。
(2)Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式
需要修改2个配置文件 core-site.xml 和 hdfs-site.xml
(3)Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name
和 value 的方式来实现。
1.修改配置文件 core-site.xml:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories. </description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hadoop.tmp.dir 是表示临时存储的数据目录,即包括NameNode的数据和DataNode的数据。注意:一定要存在这个文件
name为fs.defaultFs的值表示hdfs的逻辑位置,就是hdfs的url。
2.修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
dfs.replication表示副本的数量,伪分布式就设为1就可以了,因为只有一台主机;
dfs.namenode.name.dir表示本地磁盘的目录,是存储fsimage文件的地方;
dfs.datanode.data.dir表示本地磁盘目录,HDFS存储block块的地方。

五、hadoop集群的节点类型
1.hadoop中最核心的设计是为海量数据提供存储的hdfs和对数据进行计算的MapReduce;
2.MapReduce的作业主要包含:
(1)从磁盘或从网络中读取数据;
(2)计算数据
3.hadoop的整体性能取决于cpu、内存、网络以及存储之间的性能平衡。
4.主要的节点类型:
- NameNode:负责协调集群中的数据存储;
- DataNode:存储被拆分的数据块;
- JobTracker:协调数据计算任务;
- TaskTracher:负责执行JobTracker指派的任务;
- SecondaryNameNode:帮助NameNode收集文件系统运行的状态,类似于班级的班长,为老师分担压力。
好了,今天的hadoop学习就到这里!
当你的才华还撑不起你的野心的时候,
你就应该静下心来学习;
当你的能力还驾驭不了你的目标时,
就应该沉下心来,历练.
