前言
我,一个天天起床,睡前必刷B站的菜鸡程序猿,昨天看到一位关注的程序猿up主发布的动态,心里很不好受,所以才想着做这次的内容
到底程序猿up主做什么类型的视频才会受大众喜欢呢?
不想看文字就点击图片去看B站我的视频吧,之前好像可以直接导入视频的,现在iframe不知道为什么失效了

开始动手
1.首先需要去采集数据
选择到搜索去搜程序猿,然后选择视频,弹幕最多(也就是真实观看的人比较多),去得到每一个视频的链接。
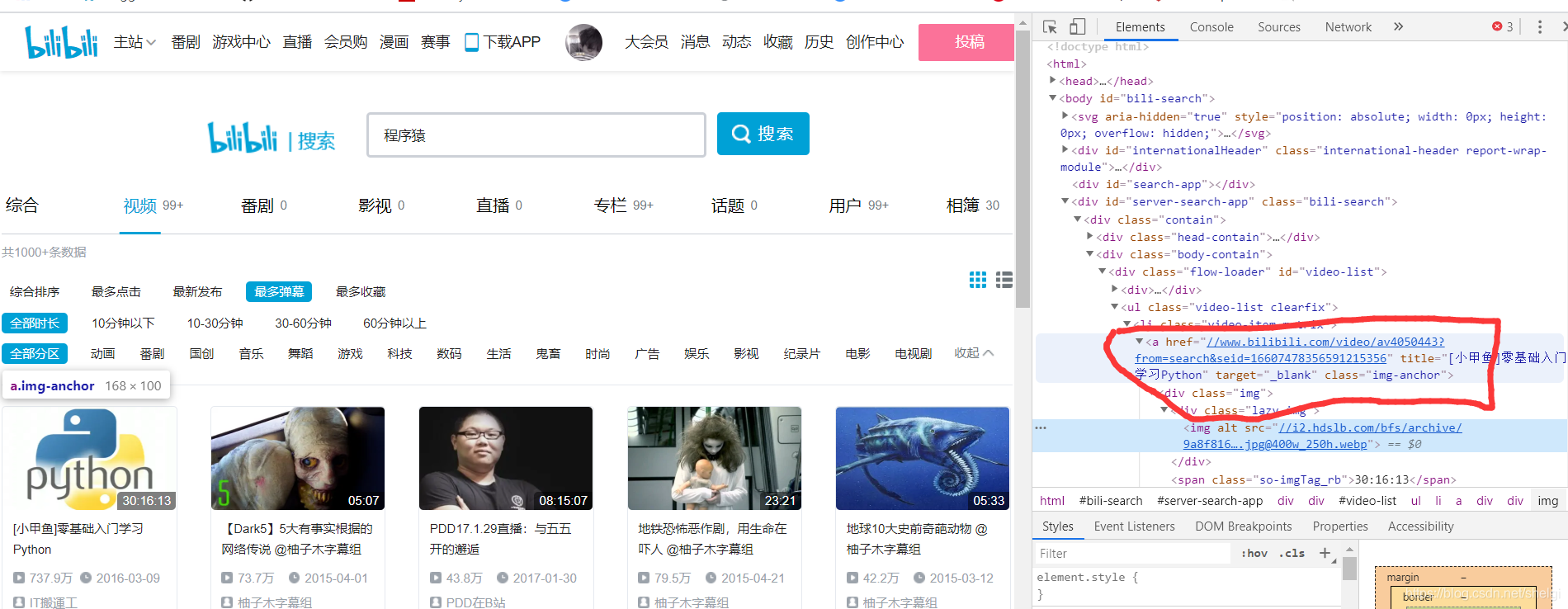
这样我们就先得到每个视频对应的详情页链接,然后再从详情页用xpath去得到标题,up名,up主页等信息(在这个页面直接得到视频点赞数和播放数最后保存的结果是异常值),点赞数和播放数用api去得到。

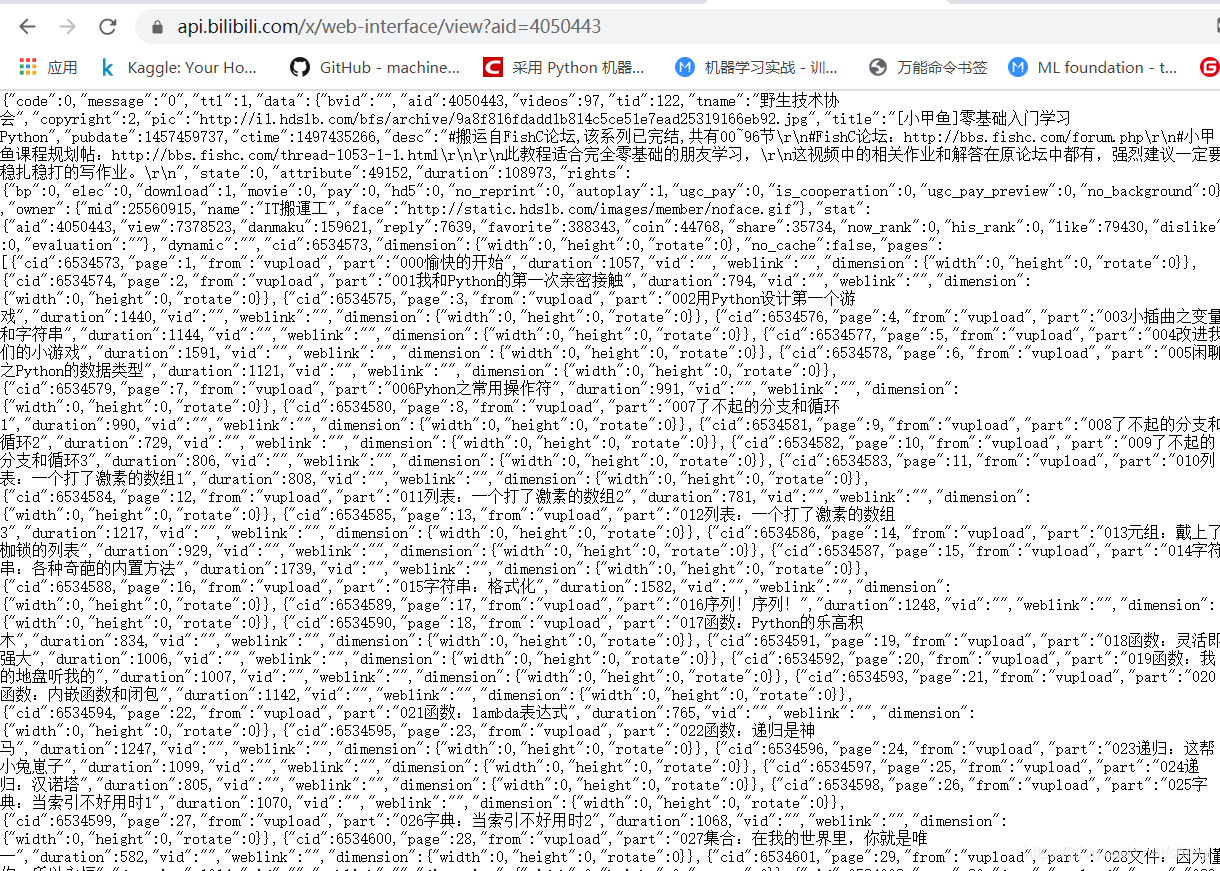
api只需要视频的id就可以返回相应的json结果,所以得到也是比较方便的,最后保存到csv文件。
爬虫代码:
import requests
from lxml import etree
import time
import pandas as pd
import re
import json
#https://search.bilibili.com/video?keyword=%E7%A8%8B%E5%BA%8F%E7%8C%BF&order=dm&duration=0&tids_1=36&tids_2=122&page=32
def get_html(url,header):
html=requests.get(url,headers=header).text
return html
def get_all_page(n):
urls=[]
for i in range(1,n+1):
url=f"https://search.bilibili.com/video?keyword=%E7%A8%8B%E5%BA%8F%E7%8C%BF&order=dm&duration=0&tids_1=36&tids_2=122&page={i}"
html=get_html(url,headers)
selector = etree.HTML(html)
li_list=selector.xpath("//ul[@class='video-list clearfix']")
for li in li_list:
urls.extend(li.xpath("//li[@class='video-item matrix']/a/@href"))
return urls
def get_information(urls,avid):
space_url=[]
name_list=[]
views_list=[]
dz_list=[]
video_names=[]
count=0
for url in urls:
count+=1
if count==10:
time.sleep(1)
url=url.replace('//','https://')
print("正在爬取:",url)
html=get_html(url,headers1)
selector = etree.HTML(html)
space_url.append(selector.xpath("//div[@class='name']/a[1]/@href")[0])
name_list.append(selector.xpath("//div[@class='name']/a[1]/text()")[0])
video_names.append(selector.xpath("//h1/@title")[0])
# views_list.append(selector.xpath("//div[@class='video-data']/span[1]/text()")[0])
# dz_list.append(selector.xpath("//div[@class='ops']/span[1]/text()")[0])
for id in avid:
base_url="https://api.bilibili.com/x/web-interface/view?aid="
html=get_html(base_url+id,headers2)
res=json.loads(html)
video_info = res['data']
views_list.append(video_info["stat"]["view"])
dz_list.append(video_info["stat"]["like"])
return space_url,name_list,views_list,dz_list,video_names
def save(n):
urls=get_all_page(n)
avid=[]
for i in urls:
avid.append(re.findall("\d+",i)[0])
space_url,name_list,views_list,dz_list,video_names=get_information(urls,avid)
data=pd.DataFrame({"空间链接":space_url,"up主":name_list,"视频名":video_names,"视频播放次数":views_list,"视频点赞数":dz_list})
data.to_csv('./B站程序猿up主视频信息.csv',encoding='utf8')
print("所有数据爬取完毕")
if __name__ == '__main__':
headers = {
'Host': 'search.bilibili.com',
'Referer': 'https//www.bilibili.com/',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
headers1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Host': 'www.bilibili.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
headers2={
'Host': 'api.bilibili.com',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 79.0.3945 .130Safari / 537.36'
}
n=int(input("请输入想要爬取的页数:"))
save(n)
我爬取了十页,一共200条数据
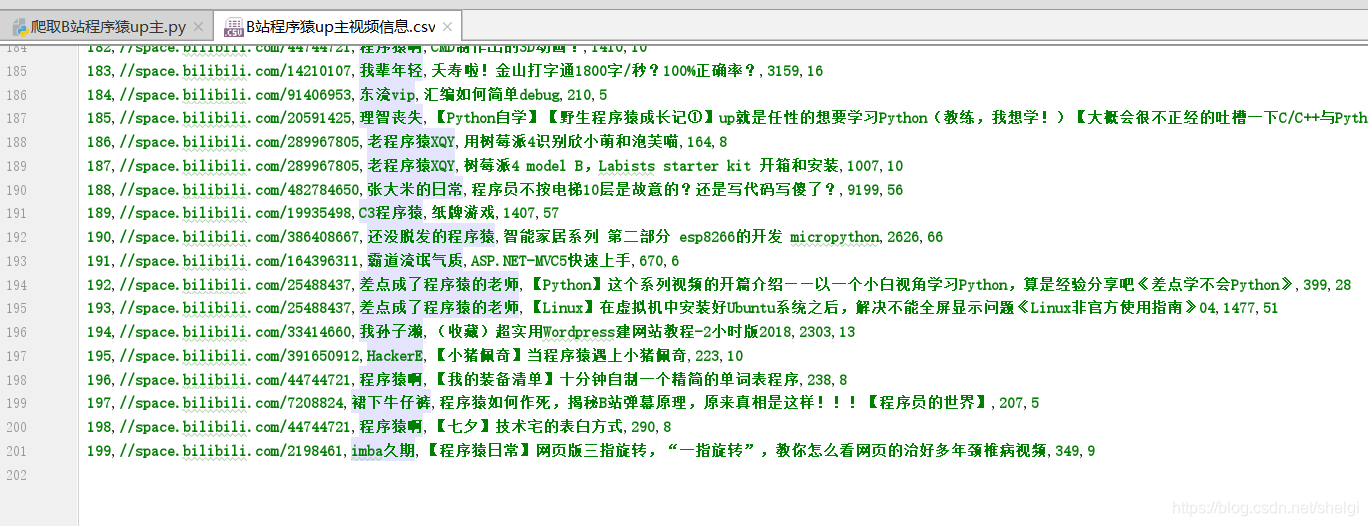
2.开始数据分析
基本的导库和导入数据,并且重命名列名
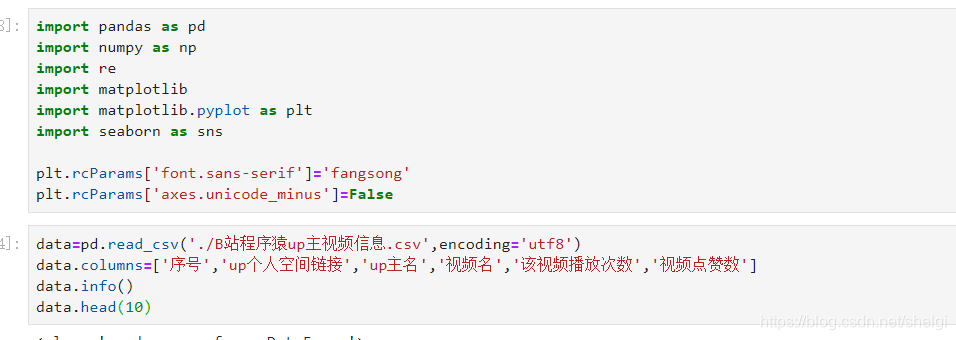
然后对数据清洗和预处理,查看缺失值异常值。但是由于B站数据比较友好,没有异常缺失值。
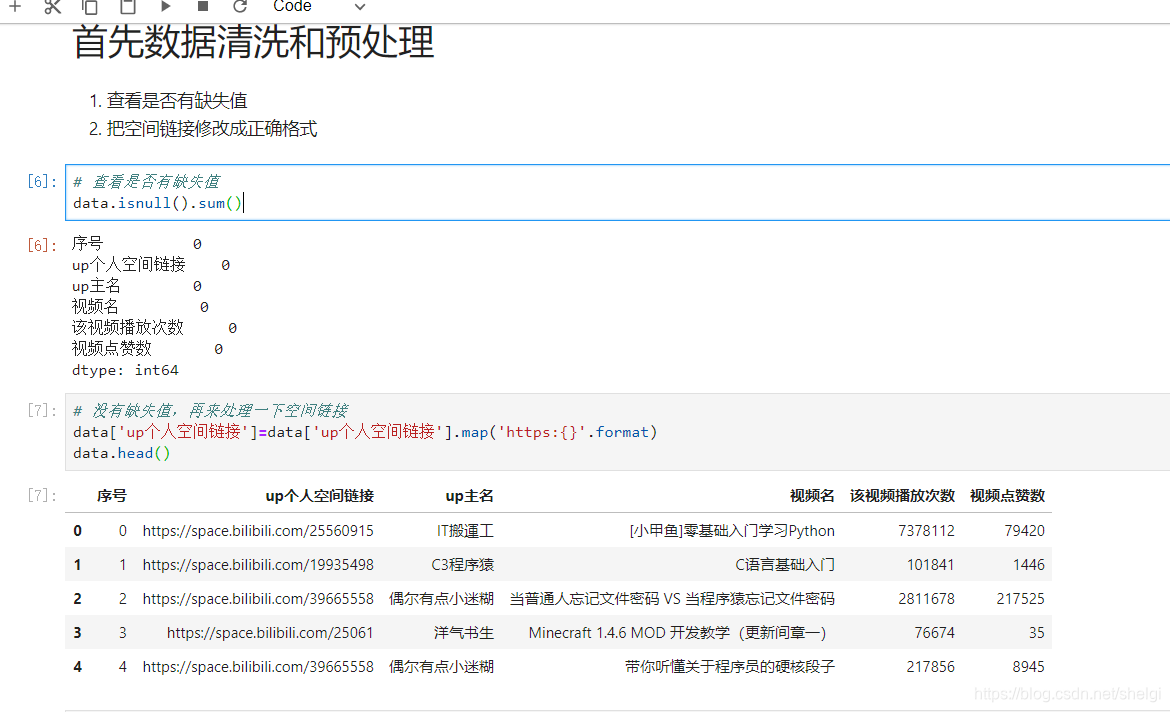
然后分组分析点赞数多的up和播放数多的up
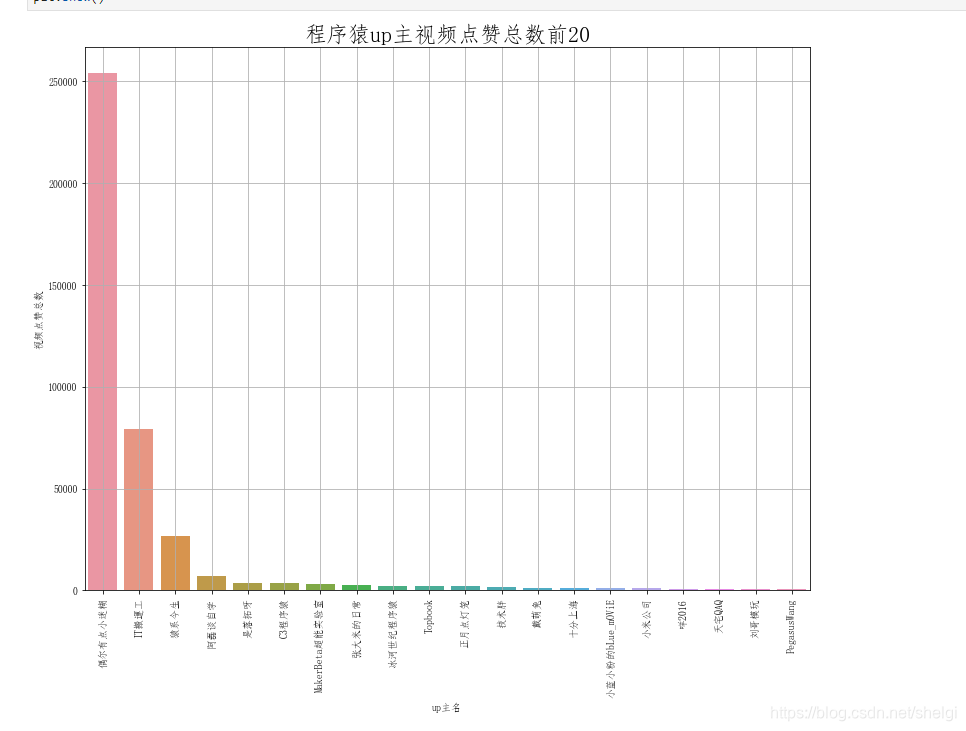
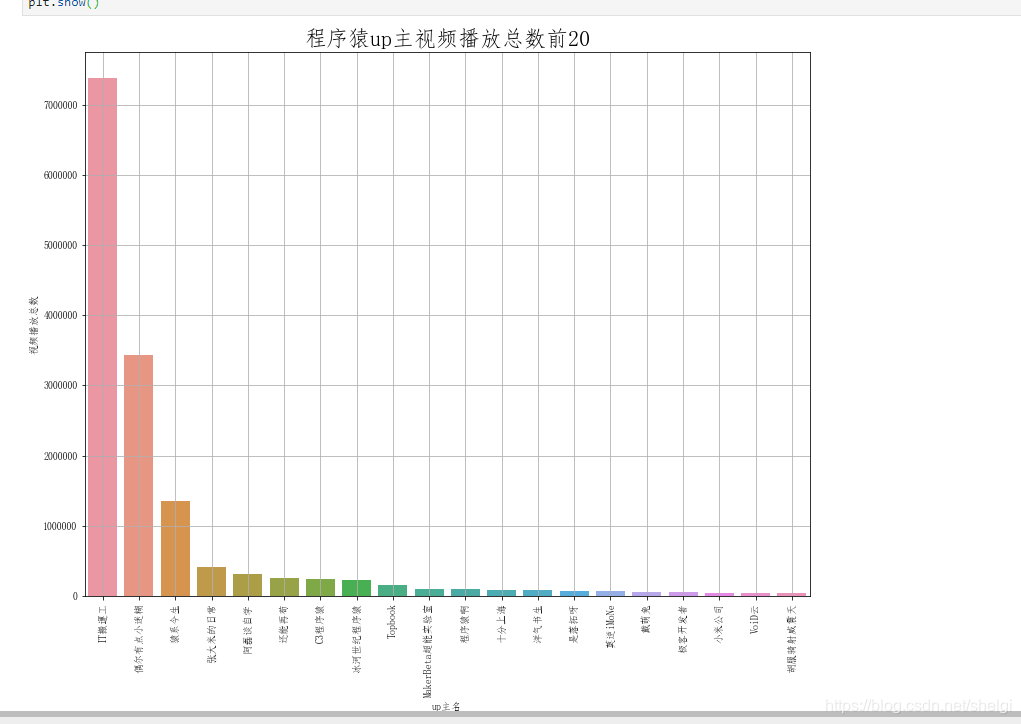
这一部分用groupby很简单就实现了,所以只上对点赞的分析绘图代码
# 找到视频点赞数最多的up主
most_dz=data.groupby(by=data['up主名'],as_index=False)['视频点赞数'].sum()
most_dz.columns=['up主名','视频点赞总数']
most_dz.head()
#降序排序
most_dz=most_dz.sort_values(by=['视频点赞总数'],ascending=False)
most_dz.head(10)
# 可视化点赞数前20的up主
plt.figure(figsize=(13,10))
sns.barplot(most_dz['up主名'][:20],most_dz['视频点赞总数'][:20])
plt.title('程序猿up主视频点赞总数前20', fontsize=22)
plt.grid()
plt.xticks(rotation=90)
plt.show()
3.查看各图中第一的视频类型

我发现迷糊老师出的视频涉及到编程的比较少,大多是涉及到日常电脑使用高阶操作的视频。看来我以后要是想点赞数多应该少出点涉及到编程的,多出点能让观众日常使用到的视频 毕竟编程类教学视频都是被埋在收藏夹里了,我的收藏夹里都有一大堆

纳尼,就只有一个视频就737万+的播放数,这也太强了吧。同时也说明还是有很多人还是愿意在B站学习编程的,特别是python相关的视频好像特别火
4.做个总结
总结:
-
在B站教学类视频有很大概率会被放进收藏夹吃灰,所以程序猿up主们要抓住观众们的喜好来创作视频,比如python系列的教学视频就很受欢迎(原因也是python生态好,学起来简单),或者是一些日常电脑高阶操作的教学的视频,这些都是比较容易吸引到观众的。
-
从亲爱的程序羊不能进入前20更能发现这个问题:程序羊的视频质量是很高的,但是受用群体不大,因为他的视频几乎都是讲程序猿的修炼,没太多简单易学的,相反大多都是程序猿们觉得很有意义,但是圈外人听着一脸懵,根本就像听天书一样的。哈哈,不过对于我们这些程序猿来说这样的up主简直就是宝藏up,也正是因为他选择讲对程序猿最有益的一些内容,放弃一些其他利益,这也才能让我们学到更多更好的知识。
-
再来看看一些出发点不同的程序猿up,比如张大米的日常。他能有这么高观看数和点赞数的原因就是他的视频既兼顾了程序猿,利用程序猿的梗可以给我们带来欢乐,同时也照顾了其他群体,从一些不那么深奥的计算机知识出发,可以让观众更了解程序猿的生活,而且每个视频长度很短,符合现在短视频的趋势。
-
从这些榜单中不难发现我们熟悉的up,落拓、技术胖……其实这些up主们都在和我们分享自己的知识和一些想法感受。还有一些没上榜,但是我想提到的up,七米老师、你脚下有坑、菜菜、棋子、哲的王、很久很久之前的.net大神Anduin……他们有的也许还没有很火,也许有的因为环境、评论各种因素导致离开,但是他们的视频我觉得是用心制作的。七米老师和哲的王讲go语言相关的视频、菜菜的数据分析,机器学习、棋子之前每天一更的python知识短视频、还有讲算法的踩坑大师,上面这些up们能让我收获越来越多的知识,所以这也是我爱刷B站的重要原因。虽然不知道为什么棋子断更这么久,但是还是希望他能早点回来更新python一分钟小知识的。
最后
通过上面的分析我们知道吸引人的视频大多有几个特点:
1.受众面广
2.搞笑轻松
3.主要是以短视频为主
4.热门且简单易学的技术类视频也很受欢迎(比如python)
但是我们也需要那些发布有意义视频或者教学视频的up,这些才更有助于我们提高。
当然,这些分析只是表面,我们可以更加深挖,比如再去爬取得到受欢迎up主们视频的长度、所在分区、简介、视频弹幕……,从视频时间长短、文本情感分析等更多角度出发分析,去找到那些影响力最大的因素。
注意,这些数据和图标不能反映最真实的信息,因为我只爬取了前十页,并且其中还有一些与程序猿无关的内容也会被搜索到导致数据有干扰,所以只是用数据以及加上我对这些up主一直以来的关注做出的分析总结,不能完全符合事实,只是提出一些想法和建议。
