基础知识了解
http 协议(应用层的协议):
常用端口:http(80)/https(443) ssh(22)
http两种常用请求方式
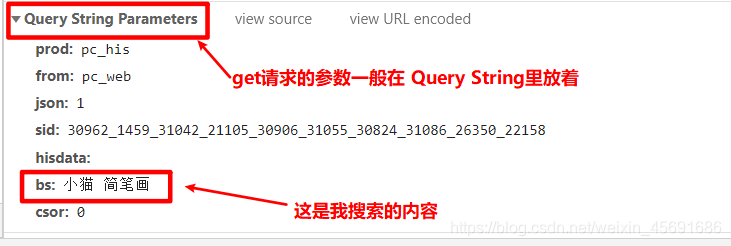
- get
优点:比较便捷,
缺点:不安全-明文,参数的长度有限
按F12 可以看一下请求,具体后面再讲


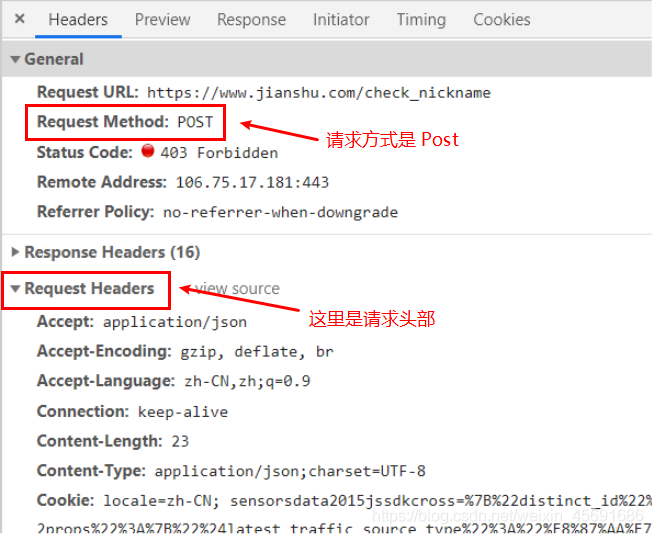
- post
优点:比较安全,数据整体没有限制,上传文件
缺点:复杂
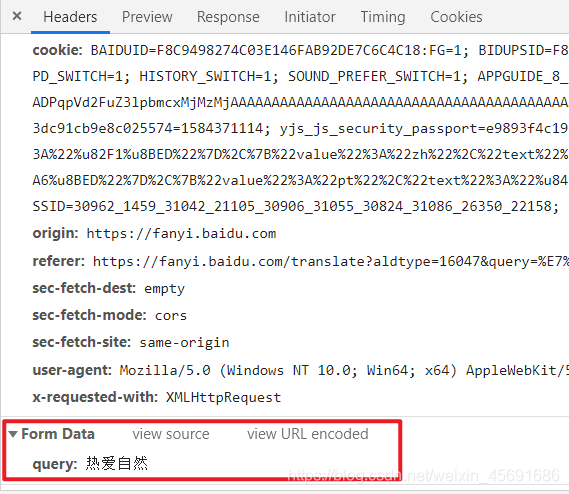
Post 请求的参数一般再Formdata中存放
http 请求:
包括:请求行,请求头,一个空行
请求行 : 用于描述客户端的请求方式 , 请求的资源名称及使用的 http 协议版本号
请求头 : 用于描述客户端请求哪台主机,以及客户端的一些环境信息
常见请求头
| 消息头 | 含义 |
|---|---|
| accept | 浏览器通过这个头告诉服务器,它所支持的数据类型 |
| Accept-Charset | 浏览器通过这个头告诉服务器,它支持哪种字符集 |
| Accept-Encoding | 浏览器通过这个头告诉服务器,支持的压缩格式 |
| Accept-Language | 浏览器通过这个头告诉服务器,它的语言环境 |
| Host | 浏览器通过这个头告诉服务器,想访问哪台主机(域名) |
| If-Modified-Since | 浏览器通过这个头告诉服务器,缓存数据的时间 |
| Referer | 浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链 |
| Connection | 浏览器通过这个头告诉服务器,请求完后是断开链接还是保持链接 |
| X-Request-With | XMLHttpRequest 代表通过 ajax 方式访问 |
| cookie | 保存一些数据,验证用到 |
| User-Agent | 浏览器和用户的信息 |
常见响应头
| 信息 | 含义 |
|---|---|
| Location | 服务器通过这个头,来告诉浏览器跳转到哪里 |
| Server | 服务器通过这个头,告诉浏览器,服务器的型号 |
| Content-Encoding | 服务器通过这个头,告诉浏览器,数据的压缩格式 |
| Content-Length | 服务器通过这个头,告诉浏览器回送数据的长度 |
| Content-Language | 服务器通过这个头,告诉浏览器语言环境 |
| Content-Type | 服务器通过这个头,告诉浏览器回送数据的类型 |
| Refresh | 服务器通过这个头,告诉浏览器定时刷新 |
| Content-Disposition | 服务器通过这个头,告诉浏览器以下载方式打数据 |
| Transfer-Encoding | 服务器通过这个头,告诉浏览器数据是以分块方式回送的 |
| Expires | -1 控制浏览器不要缓存 |
| Cache-Control | no-cache |
| Pragma | no-cache |
更多有关HTTP协议的内容请看:HTTP 协议详解
爬虫概念:
什么是爬虫:写程序,用代码模拟用户批量去互联网上抓取数据
url: 互联网有好多的链接,网的节点就是一个链接 url(统一资源定位符)
爬虫价值
1.买卖数据(高端领域的价格特别高)
2.数据分析:分析报告
3.流量
4.指数:阿里指数,百度指数
合法性:灰色产业
政府没有法律规定爬虫式违法的,也没有法律规定爬虫式合法的
公司概念:公司让你爬取数据库(窃取机密)责任在公司
爬虫可以爬所有东西????
不是的,爬虫只能爬取用户能访问到的数据
比如:爱奇艺的视频 (VIP和非vip)
1.普通用户 只能看非VIP 爬取非 VIP的视频
2.VIP 可以爬取vip 的视频
3.普通用户爬取vip视频(黑客)
爬虫种类:
通用爬虫、聚焦爬虫
通用爬虫
使用搜索引擎:百度,360,搜狐。。。
优势:开放性,速度快
劣势:目标不明确,返回的内容%90是用户不需要的,不清楚用户的需求在哪里
原理:
1、抓取网页
2、采集数据
3、数据处理
4、提供检索服务
利用的爬虫:baiduspider
通用爬虫如何抓取新网站:
1、主动提交 url
2、设置友情链接
3、百度和 DNS 服务商合作,抓取
聚焦爬虫
根据特定的需求,抓取指定的数据
优点
- 目标明确,对用户的需求非常精准,返回的内容固
- 增量式,翻页,从第一页请求到最后
- Deep 深度爬虫,静态数据:html,css
- 动态的数据 js
思路:代替浏览器上网
抓取步骤:
1、给一个 url
2、写程序模拟访问 url
3、解析内容,提取数据
网页的特点:
- 都有自己唯一的 url
- 网页的内容都是 html 结构
- 使用 http、https 协议
tobots.txt 可以限制哪些可以爬,那些不能爬,就编写 robots.txt,
这个是个口头的协议,自己写的爬虫不需要遵守,下面这个可以看看京东的tobots.txt

urllib库初学
urllib库是什么:
python 里面提供的模拟浏览器发送请求的库
python2 : urllib urllib2
python3 : urllib.request urllib.parse
首先要安装urllib库
pip install urllib.request
pip install urllib.parse
第一天简单的尝试一下
urllib.request.urlopen(); 这个主要是请求url
使用方法:urllib.request.urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False,context=None)
urllib.request.urlretrieve 这个是根据url 下载资源到本地
使用方法:urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None)
import urllib.reques
url = 'http://www.baidu.com'
# 完整的url
#http://www.baidu.com:80/index.html?name=goudan&password=123#lala
#协议://主机域名 IP地址:端口/ 文件 ?参数 #锚点
response = urllib.request.urlopen(url=url)
print(response)# 这里可以打印出这个response 发现是 object(对象)
## <http.client.HTTPResponse object at 0x0000028694396F28>
print(response.read())
#还可以用response的read方打印一下,得到发送请求后得到的响应信息
print(response.read().decode())
# 这里得到的是二进制类型(字节)可以用 decode 来转化为字符串类型
with open('baidu.html','w',encoding='utf8') as fp:
fp.write(response.read().decode())
## 把得到的写入文件,打开就是百度 的样子。
print(dict(response.getheaders()))
## 用字典的形式存放响应头
#下载图片
image_url = 'https://dss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1367815368,2392275175&fm=26&gp=0.jpg'
response = urllib.request.urlopen(image_url)
#这个返回回来就是个图片,不能直接print
## 作为图片,我们就要用 字节的形式来写入文件中保存
with open('jide.jpg','wb') as fp:
fp.write(response.read())
# 用另一种方法下载图片
image_url2 = 'https://ss1.bdstatic.com/70cFuXSh_Q1YnxGkpoWK1HF6hhy/it/u=1388212479,1974245426&fm=26&gp=0.jpg'
urllib.request.urlretrieve(image_url2,'jide1.jpg')
明天我们主要学习urllib库——get请求,手写原生代码
