由于程序运行时间测量的不准确性,虽然测量时间时已经采取了运行多次取中位值的方法,我不保证能够重现结果。
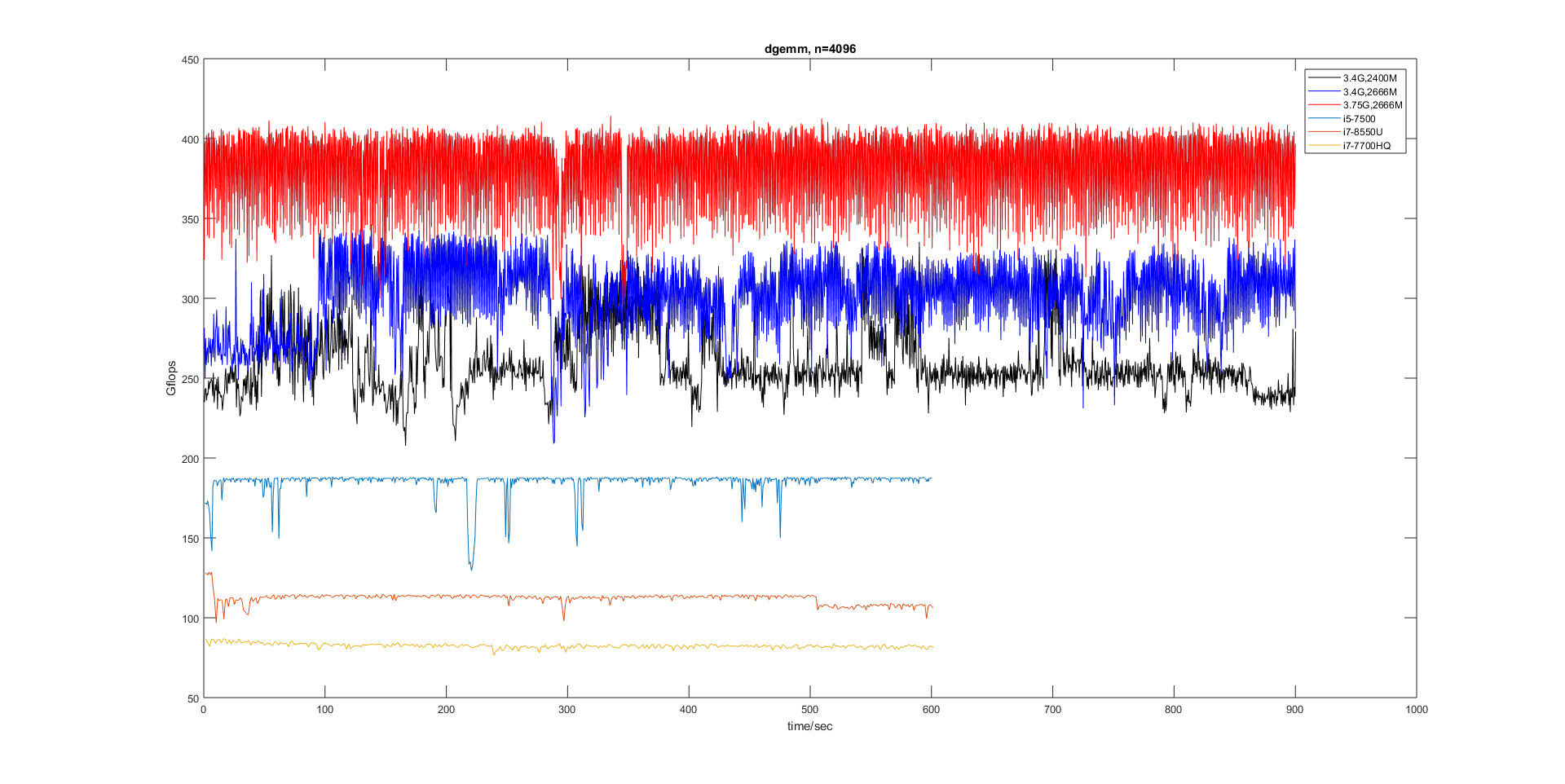
下图是使用dgemm()矩阵乘法用时计算所得CPU浮点计算能力(Gflops,y轴,越大越好)随运行时间(x轴)变化的曲线。可见其波动是非常剧烈的,偶尔还会来个尖峰或者波谷。最底下的红线是笔记本低压U i7-8550U(外接电源),睿频结束后很快就稳定到110Gflops的位置。
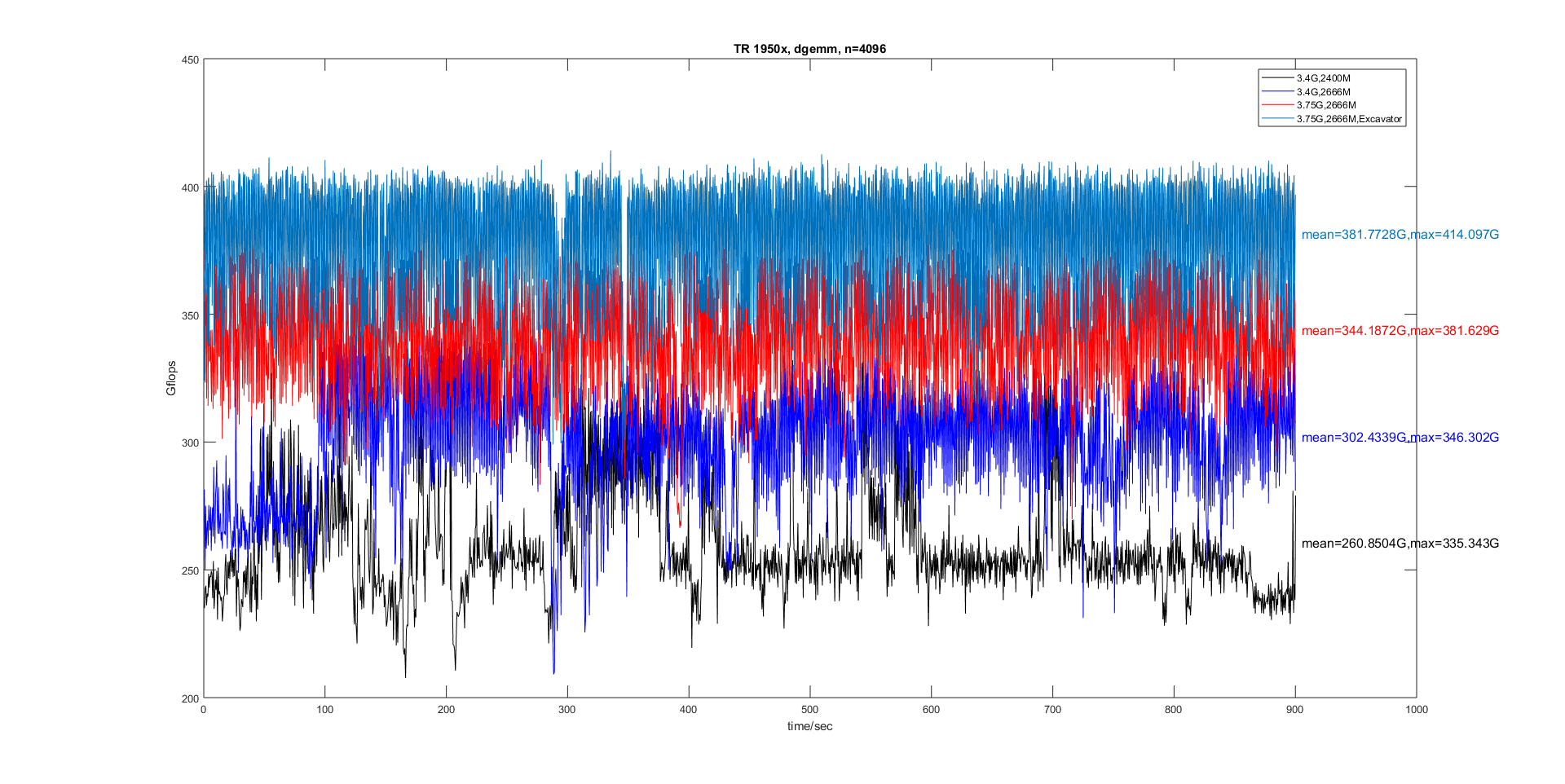
下图是AMD Thread Ripper 1950x(后面简写为TR 1950x)在不同配置下的Gflops结果,可见正确的配置是很重要的,并且TR 1950x的波动明显大于上面的i5 7500或i7 8550U。后面的测试中由于失误OpenBLAS在TR 1950x下运行的是HASWELL代码,这会导致运行时间变长。
所有文章都告诉我们要对齐,struct要对齐 padding,栈要对齐,数据要对齐。但没人告诉你过度的对齐会带来性能损失,严格的说不是对齐,而是2整数次幂强迫症。为充分利用cache大量数值算法采用的分块的方法,分块内部的kernel经常会同时对相差若干lda的数据进行操作(SSE,AVX指令),如果lda恰好为某个2的整数次幂左右(这与cache有关),那么会映射到同一个cache地址,当分块内映射到同一cache地址的数据超过了ways大小就会起冲突。当然严格的验证需要使用vtune等工具检测cache miss。
对了,如果不知道lda,可以去了解下blas,lapack的函数接口。lda=leading dimension of A
下图是若干矩阵乘法函数的性能比较。primitive那个是我手写的,按A*B为A的列向量组合的思路+FMA指令,并不真的是单纯for循环的那种primitive。在i5-7500上除了primitive不受lda,ldc设置影响外其他函数包括openblas和mkl都受ldc影响,nopacking(做了分块但没做packing)受ldc和lda影响特别大,或者说,packing后内层for循环的运算都在固定的一个小工作内存区域内,减弱了lda的影响,但ldc依然对dgemm的性能,哪怕是mkl版本有可观的影响。
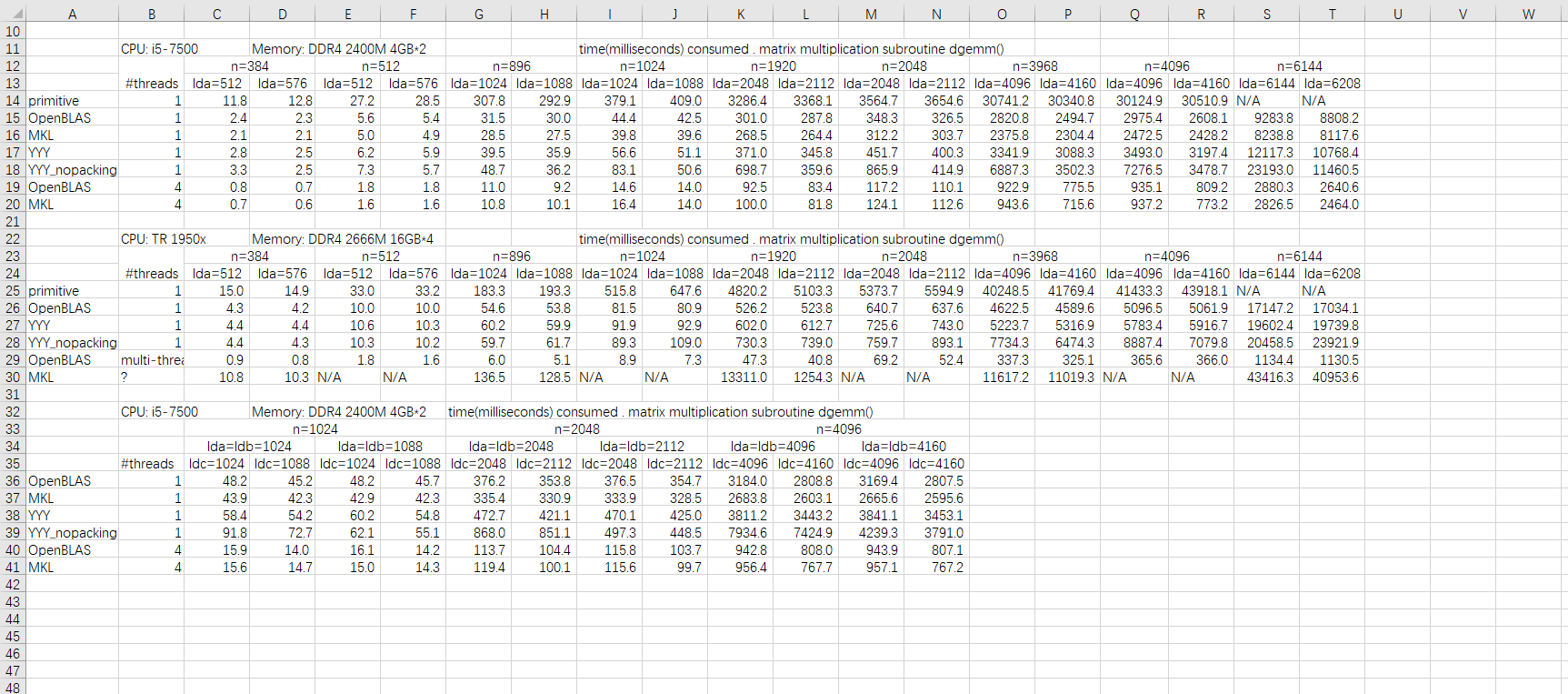
很多人简单创建两个1024*1024/2048*2048/4096*4096的矩阵然后计算矩阵乘法估算gflops,却没想过这样得到的结果是不准确的。
intel的文档上也提到了这个问题,不过重点说的是地址相差4K整数倍下的写后读问题。
Intel 64 and IA-32 Architectures Optimization Reference Manual, June 2016.11.8 4K ALIASING
4-KByte memory aliasing occurs when the code stores to one memory location and shortly after that it
loads from a different memory location with a 4-KByte offset between them. For example, a load to linear
address 0x400020 follows a store to linear address 0x401020.
The load and store have the same value for bits 5 - 11 of their addresses and the accessed byte offsets
should have partial or complete overlap.
4K aliasing may have a five-cycle penalty on the load latency. This penalty may be significant when 4K
aliasing happens repeatedly and the loads are on the critical path. If the load spans two cache lines it
might be delayed until the conflicting store is committed to the cache. Therefore 4K aliasing that happens
on repeated unaligned Intel AVX loads incurs a higher performance penalty.
To detect 4K aliasing, use the LD_BLOCKS_PARTIAL.ADDRESS_ALIAS event that counts the number of
times Intel AVX loads were blocked due to 4K aliasing.
To resolve 4K aliasing, try the following methods in the following order:
• Align data to 32 Bytes.
• Change offsets between input and output buffers if possible.
• Use 16-Byte memory accesses on memory which is not 32-Byte aligned.
另外文档上还强调如果load,store的对齐不可兼得则优先考虑store操作的对齐。在故意设置lda,ldb,ldc使之不对齐后我发现真正对dgemm速度(i5-7500, n=2048,4096)有显著影响的只有ldc,这也与文档说法相符,但不确定是否有packing操作的影响。
TR1950x表现的有点迷。amd不仅cpuid指令和intel不一样(被坑过),cache也不一样?或者是单核同频一半的浮点计算能力减轻了cache的影响?
谈到amd不得不说intel家产品对其不友好的态度,虽然mkl文档里到处是提示。但是在TR1950x上连mkl_cbwr_set都不让用还是挺过分的。嗯,我并没有安装mkl,是用matlab自带的那个mkl.dll,手动导出函数列表发现了mkl_cbwr_set这个玩意,使用时也被坑过,看的c版本说好是int mkl_cbwr_set(int),结果程序崩了,容我三思后意识到这玩意是Fortran的,正确姿势是int mkl_cbwr(int*). 还有个mkl_enable_instructions ,但没能在mkl.dll的导出函数表里发现它。mkl在TR 1950x上的表现也没让我失望,一如既往的烂,后面有几个测试为节省时间就直接跳过mkl了。所以,amd上就忘了mkl吧。
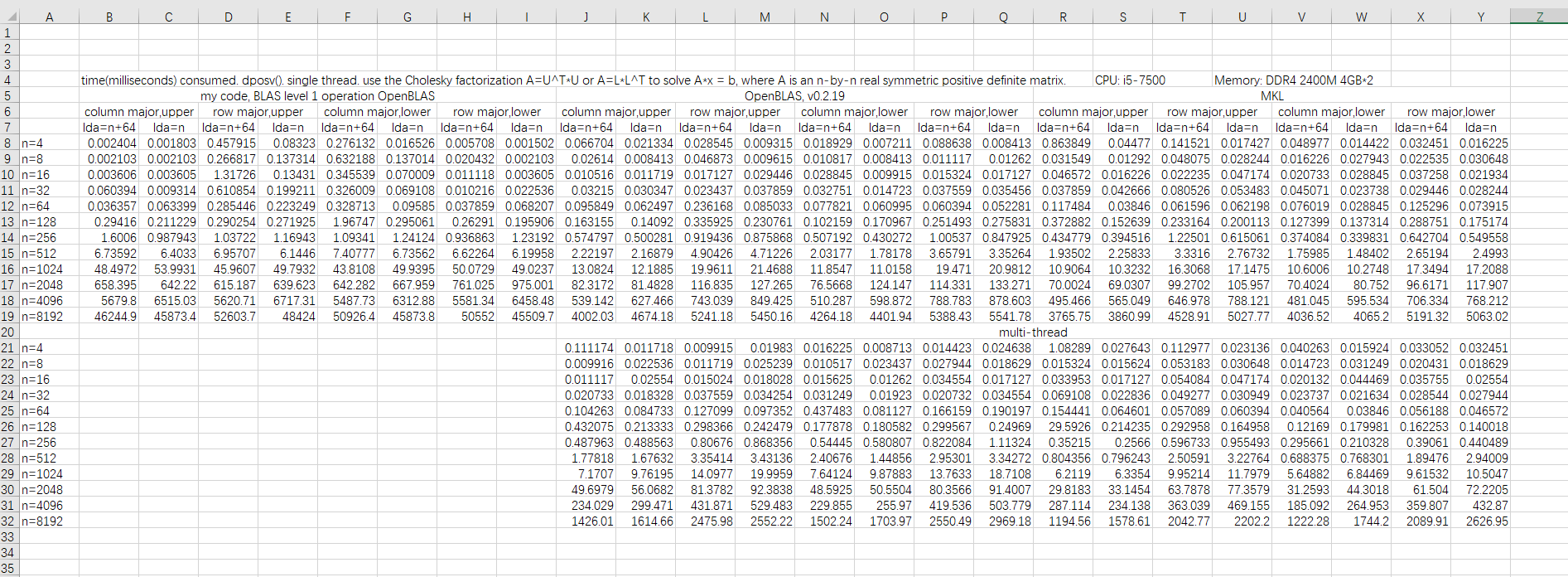
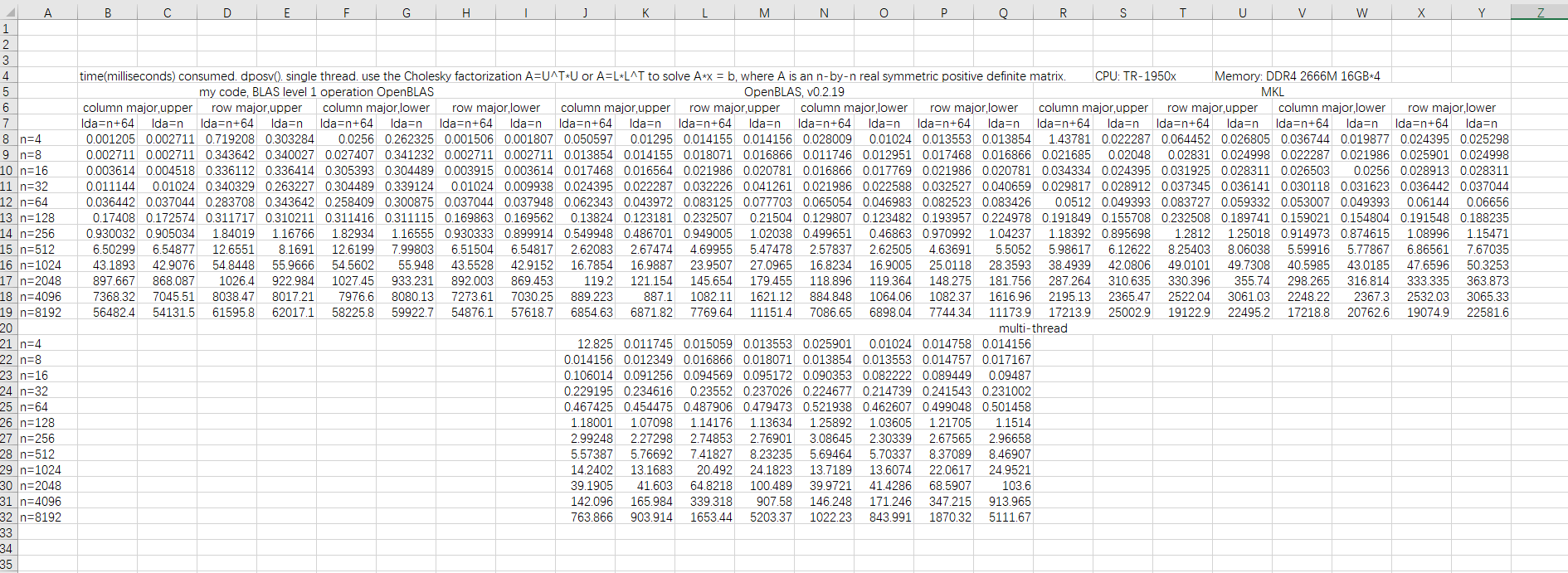
下面这个是dposv的测试结果。我知道你们不会看图的,只说结果。my code针对column/row major,upper/lower使用不同的处理方式,所以没有明显规律。而openblas和mkl对column major/row major非常敏感,并且和dgemm一样也受lda影响(因为内部也是分块的),这点并没有写到手册上!虽然这是实现相关的内容,但库开发者应提醒用户lapacke函数的性能与输入数据的layout有关。openblas的lapacke直接用的netlib实现,看过的就知道lapacke只不过是给lapack套了个C语言的壳子,内部实现完全依赖lapack,就是函数输入参数加了个major,当其为row major时我看过的那些函数都是将输入矩阵做个转置,调用lapack函数,算完后再转置,释放内存。因为大稠密矩阵转置必然带来不连续的内存访问,实际效率远低于普通的memcpy,而且这样内存使用量直接翻倍。