了解了SVM的基本形式与算法实现,接下来用SKlearn实现支持向量机分类器.
1.函数定义与参数含义
先看一下SVM函数的完全形式和各参数含义:
SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
这里只介绍一部分,其余参数可以参考SKlearn.SVM
C:惩罚系数,default = 1.0,同软间隔中的松弛因子
kernel:核函数选择,default = "rbf",可选 ‘linear’(线性核函数), ‘poly’(多项式核函数), ‘rbf’(高斯核函数), ‘sigmoid’(siigmoid核函数), ‘precomputed’
degree:多项式核函数poly的项数,只有使用poly核函数才会调用,其他核函数会忽略
class_weight:{dict,'balanced'},样本权重,默认均等权重
decision_function_shape:拆分策略,默认ovr,ovo一对一1策略被舍弃
random_state:随机数生成种子
2.线性可分情况的SVM
1)导入相关库与数据读取函数
#Sklearn SVM支持向量机
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
2)通过SKlearn返回的参数绘制超平面
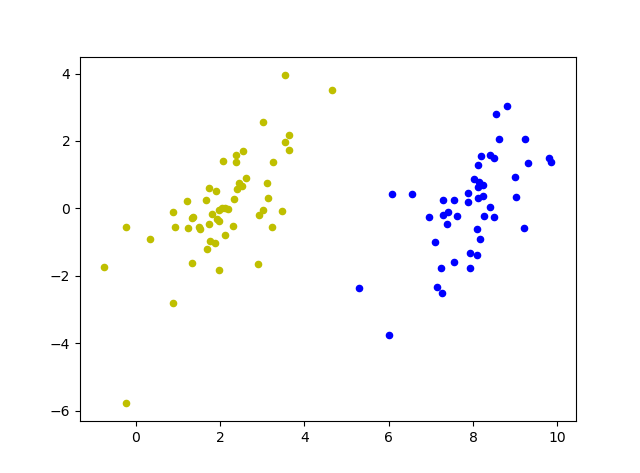
def plot_point(dataArr,labelArr,Support_vector_index,W,b): for i in range(np.shape(dataArr)[0]): if labelArr[i] == 1: plt.scatter(dataArr[i][0],dataArr[i][1],c='b',s=20) else: plt.scatter(dataArr[i][0],dataArr[i][1],c='y',s=20) for j in Support_vector_index: plt.scatter(dataArr[j][0],dataArr[j][1], s=100, c = '', alpha=0.5, linewidth=1.5, edgecolor='red') x = np.arange(0,10,0.01) y = (W[0][0]*x+b)/(-1*W[0][1]) plt.scatter(x,y,s=5,marker = 'h') plt.show()
3)主函数
if __name__ == "__main__":
#读取数据,针对二维线性可分数据
dataArr,labelArr = loadDataSet('testSet.txt')
#定义SVM分类器
clf = SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
#fit训练数据
clf.fit(dataArr, labelArr)
#获取模型返回值
n_Support_vector = clf.n_support_#支持向量个数
Support_vector_index = clf.support_#支持向量索引
W = clf.coef_#方向向量W
b = clf.intercept_#截距项b
#绘制分类超平面
plot_point(dataArr,labelArr,Support_vector_index,W,b)
clf.n_support_返回支持向量个数1,会返回一个1x2的列表,分别表示决策函数两边各有几个支撑向量
clf.suspport_返回支持向量的索引,通过对应索引,即可在图中标记支持向量
clf.coef_返回方向向量W,即超平面参数
clf.intercept_返回超平面截距项b
tips:这里几种用法只有kernel=“linear”才可以上使用,而其他几种核函数无法调用,所以我们这里只能在二维绘制超平面.
4)运行结果
3.线性不可分情况的SVM

1)导入相关库与读取数据
#Sklearn SVM支持向量机
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
2)标记支持向量
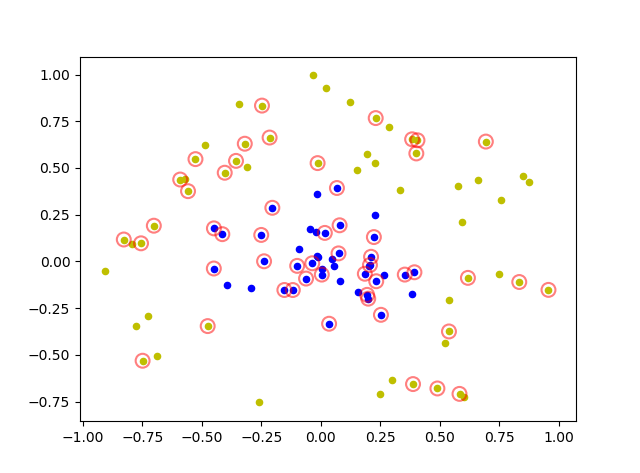
def plot_point(dataArr,labelArr,Support_vector_index): for i in range(np.shape(dataArr)[0]): if labelArr[i] == 1: plt.scatter(dataArr[i][0],dataArr[i][1],c='b',s=20) else: plt.scatter(dataArr[i][0],dataArr[i][1],c='y',s=20) for j in Support_vector_index: plt.scatter(dataArr[j][0],dataArr[j][1], s=100, c = '', alpha=0.5, linewidth=1.5, edgecolor='red') plt.show()
由于没有使用线性核函数,所以没有调用w,b,只标记支持向量
3)主函数
if __name__ == "__main__":
#读取数据,针对二维线性不可分数据
dataArr,labelArr = loadDataSet('testSetRBF.txt')
for i in range(np.shape(dataArr)[0]):
if labelArr[i] == 1:
plt.scatter(dataArr[i][0],dataArr[i][1],c='b',s=20)
else:
plt.scatter(dataArr[i][0],dataArr[i][1],c='y',s=20)
plt.show()
#交叉验证划分数据集,train:test = 0.8 : 0.2
X_train, X_test, y_train, y_test = train_test_split(dataArr,labelArr, test_size=.2,random_state = 0)
#初始化模型参数
clf = SVC(cache_size=200, class_weight=None, coef0=0.0,C=1.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
clf.fit(X_train,y_train)
#预测X_test
predict_list = clf.predict(X_test)
#预测精度
precition = clf.score(X_test,y_test)
print('precition is : ',precition*100,"%")
#获取模型返回值
n_Support_vector = clf.n_support_#支持向量个数
print("支持向量个数为: ",n_Support_vector)
Support_vector_index = clf.support_#支持向量索引
plot_point(dataArr,labelArr,Support_vector_index)
这里采用交叉验证和rbf高斯核函数,对线性不可分数据进行预测,训练集与测试集划分比例为0.8:0.2
clf.predict:给定数据集,预测数据集类别
clf.score:给予训练集与训练集标签获取预测精度
4)运行结果
precition is : 100.0 % 支持向量个数为: [27 26] [Finished in 3.8s]
精度为100%,支持向量共53个,一边27个,一边26个支持向量.
总结:
这里精度达到100%,说明分类效果不错,不过一般情况下不会出现100%的预测精度,这里只是简单的介绍了二维线性可分和二维线性不可分数据集,对于更高维的数据,支持向量机也总能发挥出比较好的性能,可以改造load_data函数实现数据读取然后用svm预测,而对于多分类问题,可以使用集成学习,构建多个支持向量分类器提高性能,一般默认先使用rbf高斯核,然后再尝试其他核函数,用交叉验证法评价分类效果.SVM相关就先写到这,这里只写了8篇,但对于支持向量机而言,可能80篇也写不完,所以还有更多的知识需要学习探索~