一、hadoop2.x概览
hadoop生态圈
相比于一般的软件工具:tomcat、mysql等,它们的功能比较单一。但是由于hadoop包含大量工具,可以完成许多事情,包括:数据管理功能、大规模并行处理框架等。虽然hadoop提供了这么多的功能,但是仍然应该把它归类为多个组件组成的Hadoop生态圈,这些组件包括数据存储、数据集成、数据处理和其他进行数据分析的专门工具。
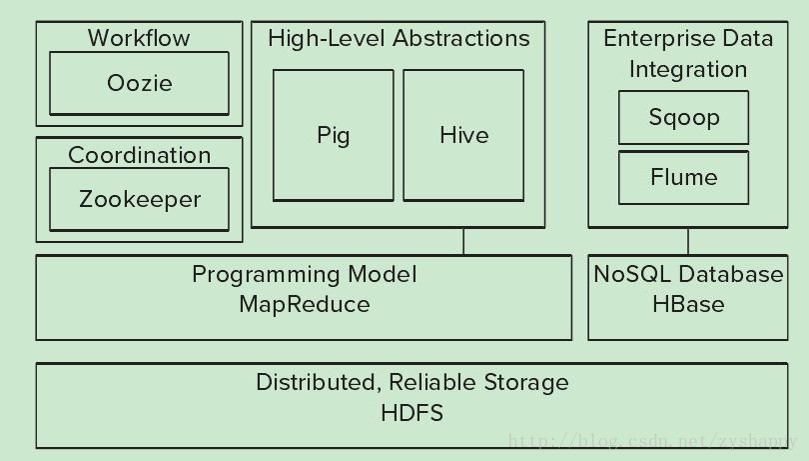
hadoop核心组件/体系结构
抛除Spark、Storm等内存/实时计算框架以及Hadoop相关安全框架外,Hadoop生态圈剩下的就是hadoop生态圈的基本组件。
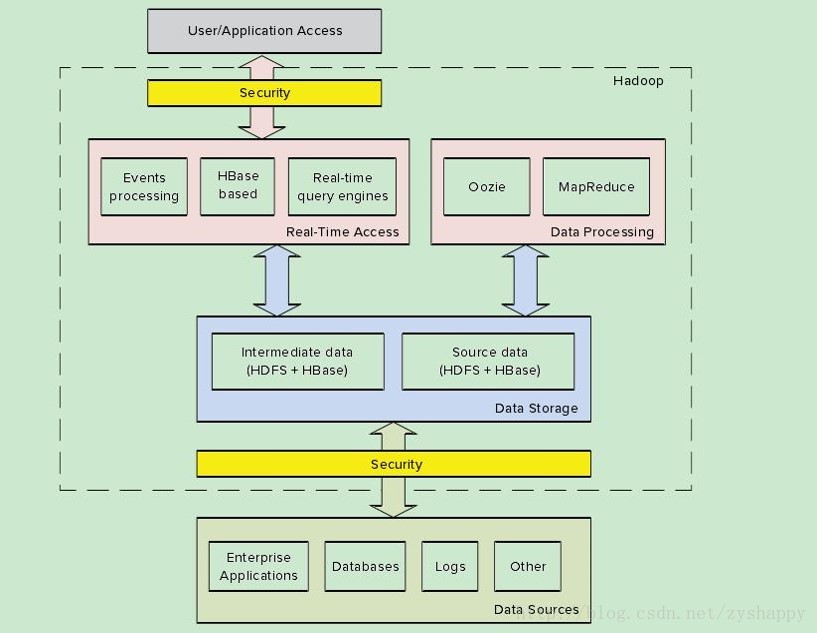
hadoop企业级应用
Hadoop的企业级应用主要包括四个大的层次,分别为数据存储层、数据处理层、实时访问层和安全层(可选)。
数据存储层包括源数据和中间数据。源数据主要来自外部数据:业务数据库、日志和其他数据源;中间数据结果来自hadoop程序,被hadoop的实时应用程序使用,并交付给其他应用程序和终端用户。通过sqoop、flume等软件或者工具将外部数据转移到hadoop中。
数据处理层中使用oozie调度mr、hive等任务进行数据处理,并产生中间数据,供其他模块使用。
对于实时访问层,hadoop的实时应用程序即支持直接数据访问,也支持数据集的访问。
安全性主要是保证数据不被没有权限的人员修改。
- hadoop的扩展性
虽然Hadoop对开发人员隐藏了底层的实现复杂性,但是可以通过设计hadoop的实现方式,集成新的功能到hadoop中执行,hadoop中可以自定义一下内容:
- 自定义Hadoop并行执行问题的方式,包括被分割的方式和执行的位置。
- 支持新的输出数据类型和数据定位。
- 支持新的输出数据类型。
- 支持自定义输出数据的位置。
- 支持自定义服务(Service)