--------------------------------------------------------scala安装-----------------------------------------------------------
scala安装: 下载---》解压---》配置系统变量----》检查是否安装成功
百度scala --->点击down---->选择之前的版本previous releases---->下载对应系统的包

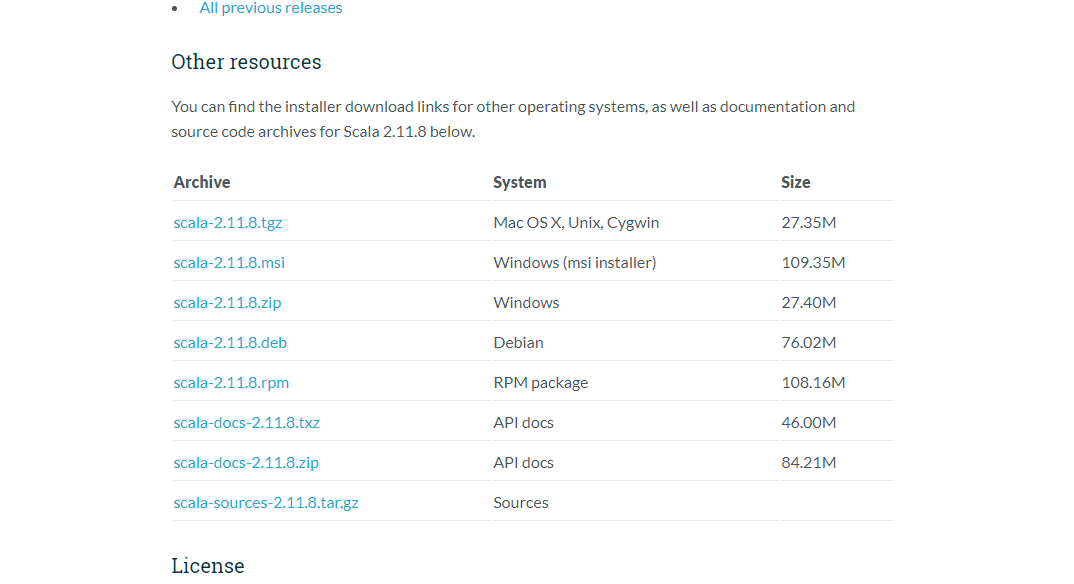
解压 tar -zxvf + tgz+ -C ~/app/
配置系统变量SCALA_HOME和PATH
export SCALA_HOME=/home/hadoop/app/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH
使之生效:source ~/.bash/profile
测试: 输入scala
-----------------------------------------------------Maven安装-------------------------------------------------
maven安装步骤:下载---》解压----》配置环境变量-------》检查是否安装成功
百度maven -----》进入官网点击下载
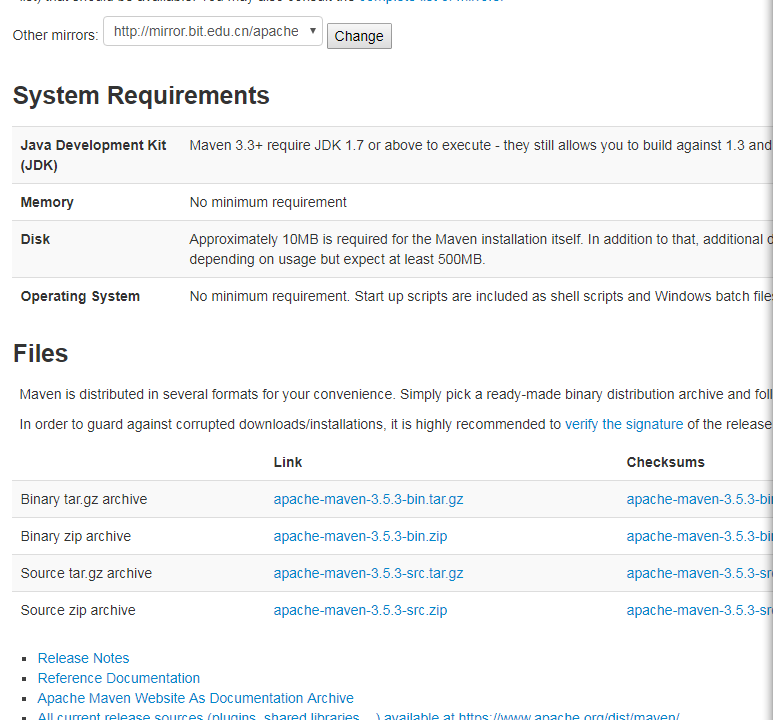
解压 tar -zxvf + tgz+ -C ~/app/
配置系统变量MAVEN_HOME和PATH
export MAVEN_HOME=/home/hadoop/app/apache-maven-3.3.9
export PATH=$MAVEN_HOME/bin:$PATH
使之生效:source ~/.bash/profile
测试: 输入mvn -v
cd conf 修改settings.xml ,配置仓库的存储路径
--------------------------------------------Hadoop安装----------------------------------------------
百度index of cdh5 ,会显示所有此系列的组件
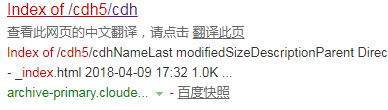
找到hadoop-2.6.0-cdh5.7.0.tar.gz
配置ssh : ssh-keygen -t rsa
cd ~/.ssh/ 显示公钥和私钥
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
cd /etc/hadoop
修改配置: 1. hadoop-env.sh
echo $JAVA_HOME---->复制到export JAVA_HOME中去
2.core-site.xml
配置namenode和临时目录
3.hdfs-site.xml
配置副本系数
4.slaves
配置子节点名称
格式化namenode: cd bin 输入 ./hdfs namenode -format
配置hadoop的环境变量 ---》source一下
启动hadoop
cd sbin
./start-dfs.sh
jps查看是否启动成功
如果是单节点的话:显示NameNode \DataNode \SecondaryNameNode
浏览器输入:hadoop:50070 查看到live nodes 1 代表正常
搭建yarn
cp maperd-site.templete maperd-site
vi maperd-site
配置使用yarn做资源调度框架---->mapreduce.framework.name: yarn
配置yarn-site.xml---->yarn.nodemanager .aux-services: mapreduce_shuffle