目录
- Bert详解(1)—从WE、ELMO、GPT到BERT
- BERT详解(2)—源码讲解[生成预训练数据]
- BERT详解(3)—源码解读[预训练模型]
- BERT详解(4)—fine-tuning
- BERT(5)—实战[BERT+CNN文本分类]
2. 预训练模型
bert模型的预训练过程包含两个任务:
- 下一句预测(Next Sentence Prediction)
- 遮蔽词预测
主程序在run_pretraining.py中, 进入run_pretraining.py主函数main(_)中,首先看model_fn_builder函数, 该函数中主要有以下几部分:构建BERT模型、构建遮蔽词预测的损失函数、构建Next Sentence Prediction的损失函数
2.1 BERT模型构建
词嵌入
程序在modeling.py中的Bertmodel类中。BERT模型构建的第一步是词嵌入,将输入的索引转换成稠密向量。输入input_ids.shape = [batch_size, seq_length], 输出output.shape= [batch_size, seq_length, embedding_size]。
def embedding_lookup(input_ids,
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False): # embedding方式的选择,是用one_hot还是用gather方式
"""Looks up words embeddings for id tensor.
Args:
input_ids: int32 Tensor of shape [batch_size, seq_length] containing word
ids.
vocab_size: int. Size of the embedding vocabulary.
embedding_size: int. Width of the word embeddings.
initializer_range: float. Embedding initialization range.
word_embedding_name: string. Name of the embedding table.
use_one_hot_embeddings: bool. If True, use one-hot method for word
embeddings. If False, use `tf.gather()`.
Returns:
float Tensor of shape [batch_size, seq_length, embedding_size].
"""
# This function assumes that the input is of shape [batch_size, seq_length,
# num_inputs].
#
# If the input is a 2D tensor of shape [batch_size, seq_length], we
# reshape to [batch_size, seq_length, 1].
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1])
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size],
initializer=create_initializer(initializer_range))
flat_input_ids = tf.reshape(input_ids, [-1])
if use_one_hot_embeddings:
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size)
output = tf.matmul(one_hot_input_ids, embedding_table)
else:
output = tf.gather(embedding_table, flat_input_ids)
input_shape = get_shape_list(input_ids)
output = tf.reshape(output,
input_shape[0:-1] + [input_shape[-1] * embedding_size])
return (output, embedding_table)
上面的程序是对token进行embedding, 而在【BERT详解(1)】提到BERT中的embedding包括三层,即 token embedding,segment embedding,position embedding。下面的程序即后面两者的embedding。
def embedding_postprocessor(input_tensor,
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16, # 在next sentence prediction任务里的Segment A和 Segment B
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512,
dropout_prob=0.1):
input_shape = get_shape_list(input_tensor, expected_rank=3) # [batchsize, seq_length, embedding_size]
batch_size = input_shape[0]
seq_length = input_shape[1]
width = input_shape[2]
output = input_tensor
# 在next sentence prediction任务里的Segment A和 Segment B编码
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# 因为token_type_vocab_size较小,在这里使用one-hot的方式,因为对于小词表这种方式更快
flat_token_type_ids = tf.reshape(token_type_ids, [-1])
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size)
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width])
output += token_type_embeddings
# 位置编码
if use_position_embeddings:
assert_op = tf.assert_less_equal(seq_length,
max_position_embeddings) # 如果seq_length>max_position_embeddings抛出异常
with tf.control_dependencies([assert_op]):
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# Since the position embedding table is a learned variable, we create it
# using a (long) sequence length `max_position_embeddings`. The actual
# sequence length might be shorter than this, for faster training of
# tasks that do not have long sequences.
# So `full_position_embeddings` is effectively an embedding table
# for position [0, 1, 2, ..., max_position_embeddings-1], and the current sequence has positions [0, 1, 2, ... seq_length-1], so we can just perform a slice.
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1])
num_dims = len(output.shape.as_list())
# Only the last two dimensions are relevant (`seq_length` and `width`), so we broadcast among the first dimensions, which is typically just the batch size.
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
output += position_embeddings
output = layer_norm_and_dropout(output, dropout_prob)
return output
参数说明:
input_tensor:即token embedding的结果
use_token_type:是否要进行segment embedding
token_type_ids: 就是预处理时的segment_ids, 形如[0, 0, 0, 1, 1, 1, 1, 1], 用于next sentence prediction中sengment A和segment B
token_type_vocab_size: 不能太确定该参数,在此先不说,若有大神知道,请告知
use_position_embeddings: 是否要位置编码
上面程序先在token embedding基础上进行segment embedding和position embedding, 然后再进行LN和dropout
构建transformer网络
BERT中Transformer结构如下图
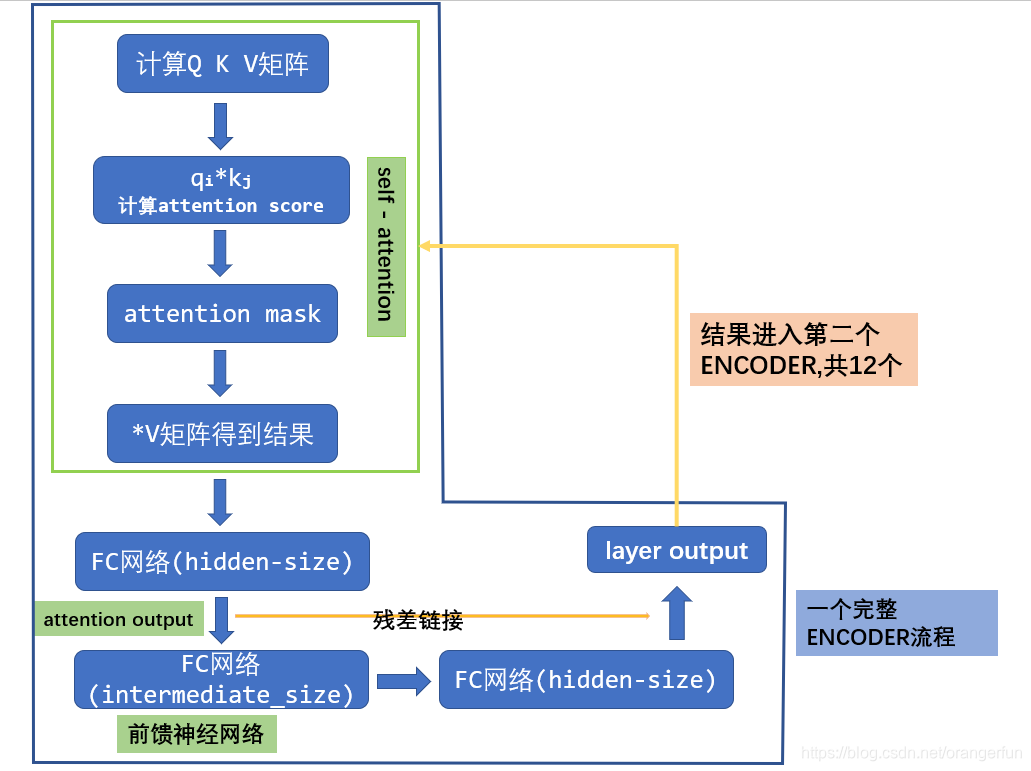
代码如下:
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768, # 词向量维度
num_hidden_layers=12, # transformer 层数
num_attention_heads=12,
intermediate_size=3072, # 前馈网络的隐藏层神经元个数
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False): # 是否返回所有层,还是只返回最后一层
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads)
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
input_width = input_shape[2]
# transformer网络在所有层上进行残差链接,所以需要输入的width和hidden_size相同
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
prev_output = reshape_to_matrix(input_tensor) # [batch_size, seq_len*width]
all_layer_outputs = []
for layer_idx in range(num_hidden_layers): # transformer 有12个block组成
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
with tf.variable_scope("attention"):
attention_heads = []
with tf.variable_scope("self"):
# attention 计算: Softmax(Qk'/Sqrt(dim))V
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
# attention_head.shape = (batch_size*seq_len, num_head*per_head_width)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# In the case where we have other sequences, we just concatenate
# them to the self-attention head before the projection.
attention_output = tf.concat(attention_heads, axis=-1)
# Run a linear projection of `hidden_size` then add a residual
# with `layer_input`.
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input)
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
# 将每一层的输出都放入列表保存起来
all_layer_outputs.append(layer_output) # layer_output.shape = [bath_size*seq_len, hidden_size]
# 返回所有encoder的输出
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output) # [batch_size, seq_len, hidden_size]
return final_outputs
# 返回最后一层的输出
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output # [batch_size, seq_len, hidden_size]
关于transformer原理部分请移步【transformer详解】,这里重点讲解其中的attention-mask的实现原理,代码如下:
if attention_mask is not None:
# `attention_mask` = [B, 1, F, T]= [batch_size, 1, seq_len, seq_len]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# 在attention_mask中原来值为1的位置,现在变为0,原来为0的位置,现在变为-10000
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# 加上adder后,不被关注的位置为一个很小的负数,被attention的位置,值几乎没变,经过 softmax 后很小的负数变为0
attention_scores += adder
# Normalize the attention scores to probabilities.
# `attention_probs` = [B, N, F, T]
attention_probs = tf.nn.softmax(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` = [B, F, N, H]=[batch_size, seq_len, num_head, per_head_width]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
代码实现原理如下图:

2.2 构建遮蔽词预测的损失函数
对MASK的词的预测值计算损失使用了交叉熵损失函数,关于交叉熵损失函数详见【交叉熵】;主要过程是先从transformer模型中取出最后一层的输出中的对应被MASK的词向量,并将其与embedding table中每个词向量求点积获得和每个词的相似度,这个输出就是对mask的词的预测值;然后将输出与真实值求交叉熵损失,具体实现如下
def get_masked_lm_output(bert_config, input_tensor, output_weights, positions, label_ids, label_weights):
"""Get loss and log probs for the masked LM.
用于计算maskLM的训练loss
args:
bert_config: bert配置文件
input_tensor: transformer encoder最后一层的输出
output_weights:embedding table
positions: 句子中mask的词在当前这句话中的索引位置
labels_ids: 句子中被mask的词在词表中的索引
label_weights:mask_lm_weights 即mask的词的权重,一般都为1
"""
# 从transformer最后一层的输出取出被mask的词的向量
input_tensor = gather_indexes(input_tensor, positions) # [len(position)*batchsize, width]
with tf.variable_scope("cls/predictions"):
# We apply one more non-linear transformation before the output layer.
# This matrix is not used after pre-training.
with tf.variable_scope("transform"):
input_tensor = tf.layers.dense(
input_tensor,
units=bert_config.hidden_size,
activation=modeling.get_activation(bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(bert_config.initializer_range))
input_tensor = modeling.layer_norm(input_tensor) # [len(position)*bs, hidden_size]
# 上面部分是transformer encoder 的输出
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
output_bias = tf.get_variable(
"output_bias",
shape=[bert_config.vocab_size],
initializer=tf.zeros_initializer())
# 用transformer的输出值与embedding table中每个词向量求点积获得和每个词的相似度
logits = tf.matmul(input_tensor, output_weights, transpose_b=True) # output_weights: embedding_tabel; shape=[len(position)*bs, vocab_size]
logits = tf.nn.bias_add(logits, output_bias)
# 预测的输出值进行softmax和log,用于后面求交叉熵
log_probs = tf.nn.log_softmax(logits, axis=-1)
label_ids = tf.reshape(label_ids, [-1])
label_weights = tf.reshape(label_weights, [-1])
# 将标签用one hot 表示
one_hot_labels = tf.one_hot(label_ids, depth=bert_config.vocab_size, dtype=tf.float32)
# The `positions` tensor might be zero-padded (if the sequence is too
# short to have the maximum number of predictions). The `label_weights`
# tensor has a value of 1.0 for every real prediction and 0.0 for the
# padding predictions.
# 参数position可能有pad 0(如果输入序列太短从而使得其没有达到最大预测输出的数量), label_weights指对每个真实的预测输出都是1, 对于pading的预测输出对应为0
per_example_loss = -tf.reduce_sum(log_probs * one_hot_labels, axis=[-1])
numerator = tf.reduce_sum(label_weights * per_example_loss)
denominator = tf.reduce_sum(label_weights) + 1e-5
# 平均损失
loss = numerator / denominator
return (loss, per_example_loss, log_probs)
2.3 构建Next Sentence Prediction的损失函数
取出每个句子首位的【CLS】组成一个矩阵向量,后面接上一个全连接层进行2分类,将预测值与next_sentence_labels中的真实标签计算交叉熵损失,具体实现如下
def get_next_sentence_output(bert_config, input_tensor, labels):
"""Get loss and log probs for the next sentence prediction."""
# args: input_tensor:shape= [batchsize,hidden_units] transformer最后输出【CLS】对应的向量
# labels: next_sentence_label 真实标签
# Simple binary classification. Note that 0 is "next sentence" and 1 is
# "random sentence". This weight matrix is not used after pre-training.
with tf.variable_scope("cls/seq_relationship"):
# 全连接的权重
output_weights = tf.get_variable(
"output_weights",
shape=[2, bert_config.hidden_size],
initializer=modeling.create_initializer(bert_config.initializer_range))
output_bias = tf.get_variable(
"output_bias", shape=[2], initializer=tf.zeros_initializer())
# 全连接预测
logits = tf.matmul(input_tensor, output_weights, transpose_b=True) # [batch_size, 2]
logits = tf.nn.bias_add(logits, output_bias)
# 计算交叉熵损失函数
log_probs = tf.nn.log_softmax(logits, axis=-1)
labels = tf.reshape(labels, [-1])
one_hot_labels = tf.one_hot(labels, depth=2, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, log_probs)
2.3 总结
本章讲解了BERT源码中的预训练模型过程,包括BERT模型的搭建过程、训练过程的损失函数等内容。BERT模型中最核心的就是transformer模型, BERT预训练的损失函数由两部分组成,即遮蔽词预测的损失函数和Next Sentence Prediction的损失函数,其两者之和就是总的损失函数。在下章我们将讲解BERT实战
