一、本地过程调用:
假设我们需要一个计算器,专门处理算术运算,我们将在当前的进程地址空间内实现这么一个类,然后提供一些接口,比如需要加法运算,在本地如此调用:
class Calculator{
public:
int add(int left_value, int right_value){
return left_value + right_value;
}
};
int main(){
Calculator* calculator = new Calculator();
cout << calculator->add(1, 99) << endl;
return 0;
}
即在自己的地址空间中调用当前进程的方法,这就是本地过程调用,我们可以直接获取到调用结果。
二、远程过程调用: Remote Procedure Call
随着时间的发展,Calculator需要提供的方法和服务越来越多,不仅自己需要调用多种算术运算方法,更希望给其他进程,以及其他主机上的进程提供服务,就不用重复实现这些服务。远程调用就是请求服务方可以将需要计算的数据发送到服务端,经过服务端的计算将结果返回给客户端,而客户端根本不需要知道谁给他提供服务,服务是怎么实现的。
(实际的生产环境中服务比Calculator复杂的多,总结一句话:将在远程跑的程序做得就像在本地运行一样)
RPC要解决的两个问题:
- 解决分布式系统中,服务之间的调用问题;
- 远程调用时,要能够像本地调用一样方便,让调用者感知不到远程调用的逻辑。
三、简单的RPC的实现:
RPC很少用到http协议来进行数据传输,毕竟我只是想传输一下数据而已,何必动用到一个文本传输的应用层协议呢,我为什么不直接使用二进制传输?比如直接原始的Socket协议进行传输?
不管你用何种协议进行数据传输,一个完整的RPC过程,都可以用下面这张图来描述:
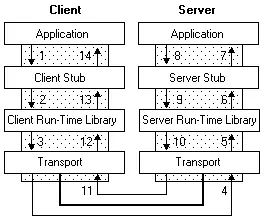
比如,既然是分布式了,那么一个服务可能有多个实例,你在调用时,要如何获取这些实例的地址呢?
- 这时候就需要一个服务注册中心,比如在Dubbo里头,就可以使用Zookeeper作为注册中心,在调用时,从Zookeeper获取服务的实例列表,再从中选择一个进行调用;
那么选哪个调用好呢?
- 这时候就需要负载均衡了,于是你又得考虑如何实现复杂均衡,比如Dubbo就提供了好几种负载均衡策略;
- 这还没完,总不能每次调用时都去注册中心查询实例列表吧,这样效率多低呀,于是又有了缓存,有了缓存,就要考虑缓存的更新问题
你以为就这样结束了,没呢,还有这些:
- 客户端总不能每次调用完都干等着服务端返回数据吧,于是就要支持异步调用;
- 服务端的接口修改了,老的接口还有人在用,怎么办?总不能让他们都改了吧?这就需要版本控制了;
- 服务端总不能每次接到请求都马上启动一个线程去处理吧?于是就需要线程池;
- 服务端关闭时,还没处理完的请求怎么办?是直接结束呢,还是等全部请求处理完再关闭呢?优雅停机?
参考链接:一篇不错文章
四、grpc:google rpc
有了解过google的protobuffer的朋友都知道,该IDL语言无论在效率还是性能都是很不错的。
当protobuffer遇到rpc ,那么grpc就诞生了,数据的发送与解析,都使用protobuffer效率上会不会更高?
