返回 Deep Learning 经典网络 model 发展史 目录
上一章:深度篇—— Deep Learning 经典网络 model 发展史(三) 细说 ZF-Net 结构和特点
下一章:深度篇—— Deep Learning 经典网络 model 发展史(五) 细说 GoogleNet 结构和特点 (包括 v1, v2, v3)
本小节,细说 VGG16 结构和特点,下一小节细说 GoogleNet 结构和特点 (包括 v1, v2, v3)
VGG16 论文:Very Deep Convolutional Networks for Large-Scale Image Recognition
二. 经典网络(Classic Network)
4. VGG16
VGG16 是由牛津大学 VGG (Visual Geometry Group, VGG) 提出的,是 2014 年 ImageNet 竞赛定位任务的第一名 和 分类任务的第二名中的基础网络。观察以往的 AlexNet 和 ZF-Net 的经验,发现,卷积核变小,网络加深,有利于提高精度,所以,VGG16 就是奔着这个方向去发展而得的。
(1). 网络描述:
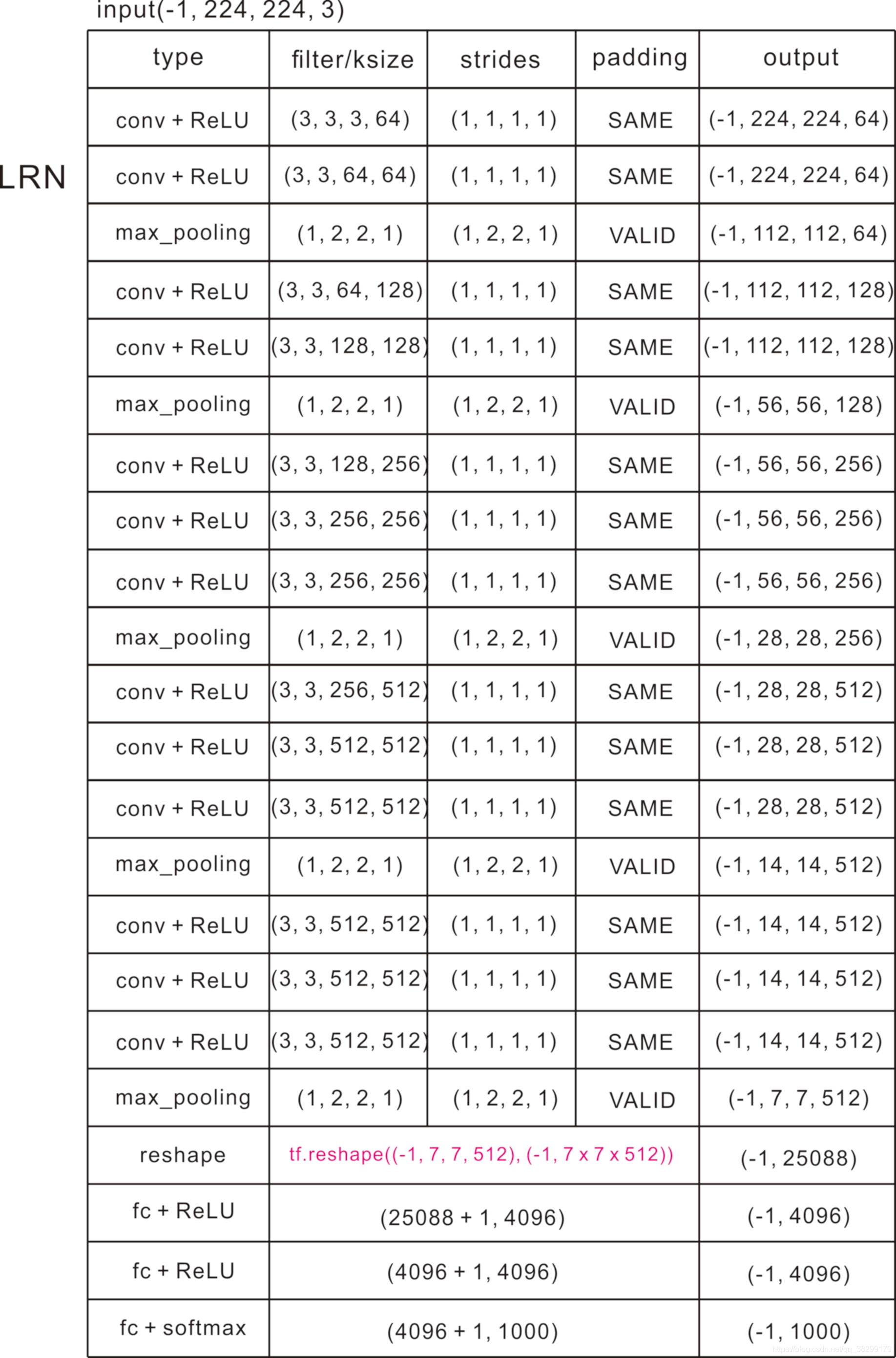

(2). VGG16 的新特点:
①. 在 VGG16 中,所有的卷积核大小都为 ,步幅都为
,padding 都为 SAME;所有的池化都为 max_pool(),池化核大小都为
,步幅都为
,padding 都为 VALID。
②. VGG16 相比于 AlexNet 的一个改进是采用连续的几个 的卷积核代替 AlexNet 中较大的卷积核 (
)。对给定的感受野(与输出有关的输入图像的局部大小),对给定的感受野(与输出有关的输入图像的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少,5 x 5 > 3 x 3 + 3 x 3)
③. 优点:
a. 卷积串联比单独使用一个较大的卷积核,拥有更少的参数,同时会比单独一个卷积拥有更多的非线性变化,适应更复杂的模式。而卷积核串联,多次提取特征,比单一的卷积核提取的特征要细腻。padding 的步幅 小于 核 的 大小,可以覆盖提取特征,也提高了特征的细腻度。
b. VGG16 模型相对稳定、易于移植,所以很多网络用它做 backbone 来做示例。
④. 缺点:
a. 网络架构 weight 数量相当大,很消耗磁盘空间。比 ResNet-53 的 weight 还大。
b. 由于 VGG16 全连接节点的数量较多,再加上网络比较深,所以训练非常慢。

返回 Deep Learning 经典网络 model 发展史 目录
上一章:深度篇—— Deep Learning 经典网络 model 发展史(三) 细说 ZF-Net 结构和特点
下一章:深度篇—— Deep Learning 经典网络 model 发展史(五) 细说 GoogleNet 结构和特点 (包括 v1, v2, v3)
