一、实验目标
1)体验敏捷开发中的两人合作。
2)进一步提高个人编程技巧与实践。
二 、实验内容
1)根据以下问题描述,练习结对编程(pair programming)实践;
2)要求学生两人一组,自由组合。每组使用一台计算机,二人共同编码,完成实验要求。
3)要求在结对编程工作期间,两人的角色至少切换 4 次;
4)编程语言不限,版本不限。建议使用 Python 或 JAVA 进行编程。
三、实验过程
1、代码规范
(1)函数命名、 变量命名、 文件命名要有描述性,少用缩写,尽量做到见名知意。
(2)文件名要全部小写,可以包含下划线 (_) 或连字符 (-),依照项目的约定.。如果没有约定,,那么 “_” 更好。
(3)一般来说,函数名的每个单词首字母大写 (即 “驼峰变量名” 或 “帕斯卡变量名”), 没有下划线.。对于首字母缩写的单词, 更倾向于将它们视作一个单词进行首字母大写 。
(4)使用前置自增。不考虑返回值的话,前置自增 (++i) 通常要比后置自增 (i++) 效率更高。因为后置自增 (或自减) 需要对表达式的值 i 进行一次拷贝.。如果 i 是迭代器或其他非数值类型, 拷贝的代价是比较大的。
(5)不使用流(除非是日志接口需要),使用 printf 之类的代替。
(6)注释:// 或 /* */ 都可以,但 // 更 常用。要在如何注释及注释风格上确保统一。
(7)函数注释:基本上每个函数声明处前都应当加上注释,描述函数的功能和用途。只有在函数的功能简单而明显时才能省略这些注释。注释使用叙述式 (“Opens the file”) 而非指令式 (“Open the file”); 注释只是为了描述函数,而不是命令函数做什么。通常,注释不会描述函数如何工作,那是函数定义部分的事情。
2、总体设计
代码有四个主要功能模块:随机初始化、清屏、下一时刻以及输出0/1矩阵
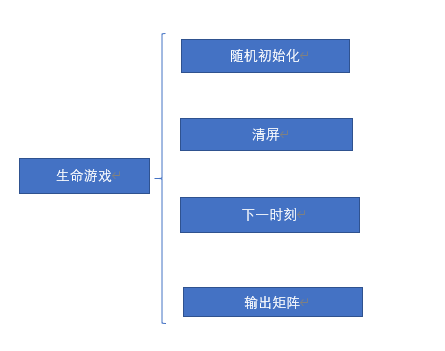
各功能模块的实现如下图所示:

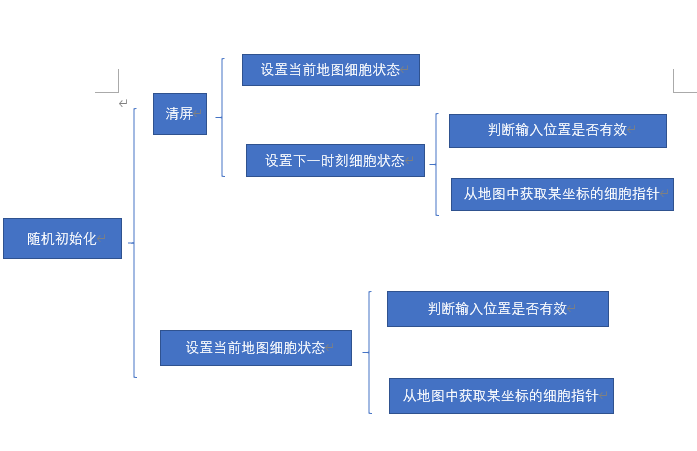
3、结对编程过程
对所选题目进行再次分析之后,我组决定使用C++在VC6.0上编写代码。
经讨论,我们组决定每人承担部分功能,编写代码时,由写代码的人开启屏幕分享。

在编写print()函数时,我没有弄清楚i、j和width、height的对应关系,导致输出的矩阵大小与设定的大小不同,经杜蒙蒙同学提醒,将错误改正。同时注意到C++习惯于使用前置自增,而平时我们多使用后置自增。为更好符合代码规范,将原本写的后置自增改为前置自增。main()函数由杜蒙蒙同学编写,编写后运行无误,但是运行结果只能进行单次单步演化,为使功能更加完善,杜蒙蒙同学添加了switch,使得运行结果可以进行单次单步演化也可以进行多次单步演化。
4、主要功能模块
(1)随机初始化
① 实现代码

②运行结果

(2)下一时刻
①实现代码
 ②运行结果
②运行结果

(3)输出矩阵
①实现代码

②运行结果
如上图
5、提交到GitHub
此次试验GitHub仓库地址是https://github.com/cloudy-y/game_of_life
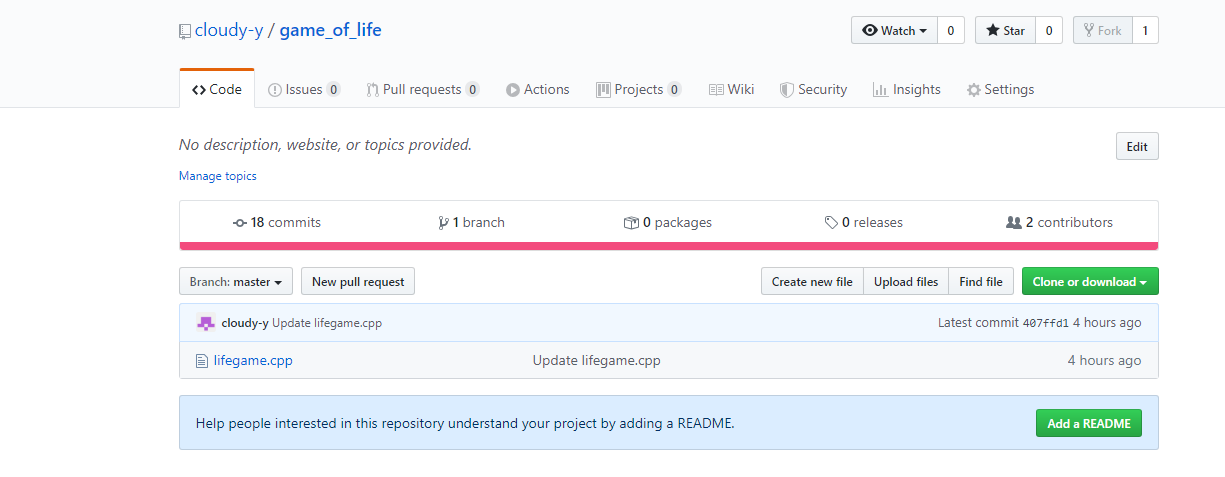
我和杜蒙蒙同学对各自负责的模块进行了多次commit
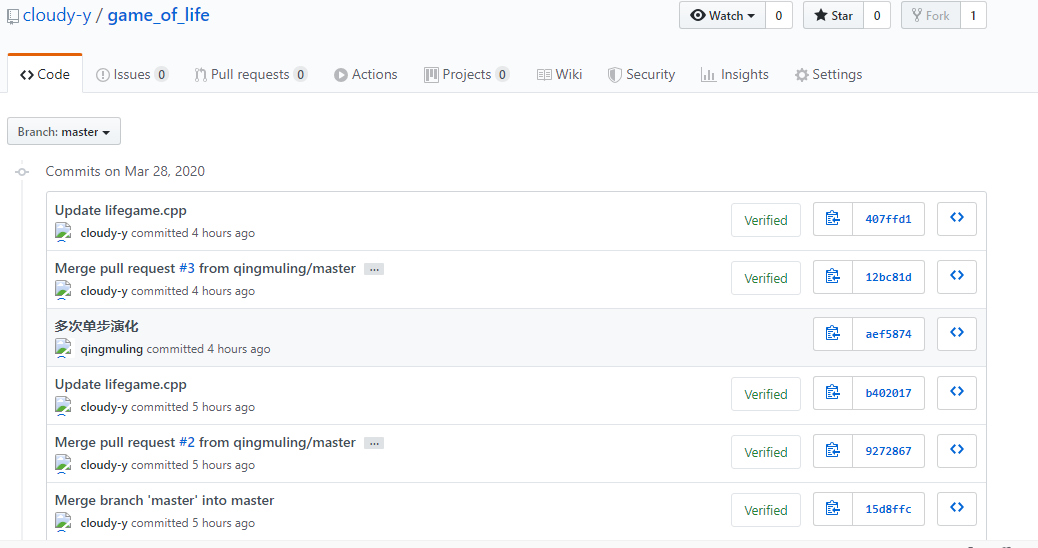
在其中一次pull request 时,发生了冲突,无法进行merge。经查阅资料发现,这是因为我们在相近的时间修改了相同的一段代码,导致在github中不能够自动merge。此时合并过程发生冲突, git 会把修改记录直接保存在文件中,让开发者判断文件如何解决合并。要解决冲突,只需要将发生冲突的文件中不需要的内容删掉,再分别执行①git commit -a②git checkout master③git merge 小伙伴-master即可。
四、实验小结
1、通过此次结对编程实验,加强了自己对于问题看法的表达能力,同时在小组讨论时思维更加集中、跳跃,效率得到很大提升,体会到了结对编程的好处。
2、对于git的操作更加熟练,也发现了GitHub的强大之处。