

SQL(Structured Query Language)结构化查询语言。
本课程以SQL Server 2005为应用背景。
学习建议:一定要习惯使用帮助!
SQL Server 的安装、启动和身份验证。
- 1、安装。
- 2、SQL Server 服务的启动:开始→程序→Microsoft SQL Server 2005→配置工具→SQL Server Configuration Manager
- 3、启动:开始→程序→Microsoft SQL Server 2005→SQL Server Management Studio
- 4、两种身份验证:Windows身份验证和SQL Server身份验证。
SQL Server 系统数据库
- 1、master 数据库:主要记录了SQL Server的所有系统信息。
- 2、tmpdb 数据库:为临时表和其他临时存储需求提供存储空间。
- 3、model 数据库:建立所有用户数据库的模板。
- 4、msdb 数据库:数据库在SQL Server代理程序调度报警和作业时使用。
数据库的创建与使用
create database test
on (name = testdata, filename = 'e:\lxd\td.mdf')
log on (name = testlog, filename = 'e:\lxd\tdlog.ldf')参数name:数据库文件逻辑名,它必须在全部数据库逻辑名中唯一。
参数filename:存储数据和日志的物理文件名及路径。
注意:数据文件后缀mdf,日志文件后缀ldf。
附加某些参数的Create Database命令
create database new_db
on primary
( name = new_db,
filename = 'd:\new_db.mdf',
size = 5mb,
maxsize = 50mb,
filegrowth = 10% )该命令自动建立日志文件。
使用某数据库命令:use new_db
数据库的修改与维护
1、修改数据库数据文件的初始大小
alter database new_db
modify file
( name = new_db,
size = 15mb )注意:数据库逻辑名必须与最初数据库定义时的逻辑名一致。
2、修改数据库名
exec sp_renamedb 'new_db', 'old_db'调用存储过程,第一个参数为原数据库名,第二个参数为新数据库名。
3、删除数据库
drop database old_db4、查看系统中有哪些数据库
exec sp_helpdb5、查看new_db数据库定义信息
exec sp_helpdb new_db数据库的分离、附加与备份、还原
1、分离数据库
exec sp_detach_db new_db2、附加数据库
create database new_db on
( filename = 'd:\new_db.mdf' ),
( filename = 'd:\new_db_log.ldf' )
for attach注意:一旦将数据库分离,则该数据库将不能对外提供服务。
3、备份数据库
backup database new_db
to disk = 'e:\lxd\test.bak'4、还原数据库
restore database new_db
from disk = 'e:\lxd\test.bak'关系模式的设计

常用数据类型
| 常用数据 类型 |
含义 |
| char(n) |
长度为n的定长字符串 |
| varchar(n) |
最大长度为n的变长字符串 |
| bigint |
大整型(8字节) |
| int |
整型(4字节) |
| smallint |
短整型(2字节) |
| tinyint |
微整型(1字节) |
| decimal(p,s) numeric(p,s) |
定点数,由p位十进制数位(小数位占s位)构成的数。1<=p<=38,默认为19;0<=s<=p,默认为0。 |
| money |
8字节整数,精确到万分之一。 |
| smallmoney |
4字节整数,精确到万分之一。 |
| float[(n)] |
浮点数,尾数位数为n,1<=n<=53,默认为53。 |
| real |
等同于float(24) |
| datetime |
时间日期型。格式化为YYY-MM-DD HH:MM:SS。精确到3.33毫秒。 |
| smalldatetime |
同datetime,精确到1分钟。 |
| text |
存储大容量长度可变字符串 |
基本表的定义

查看表的基本定义信息:
exec sp_help student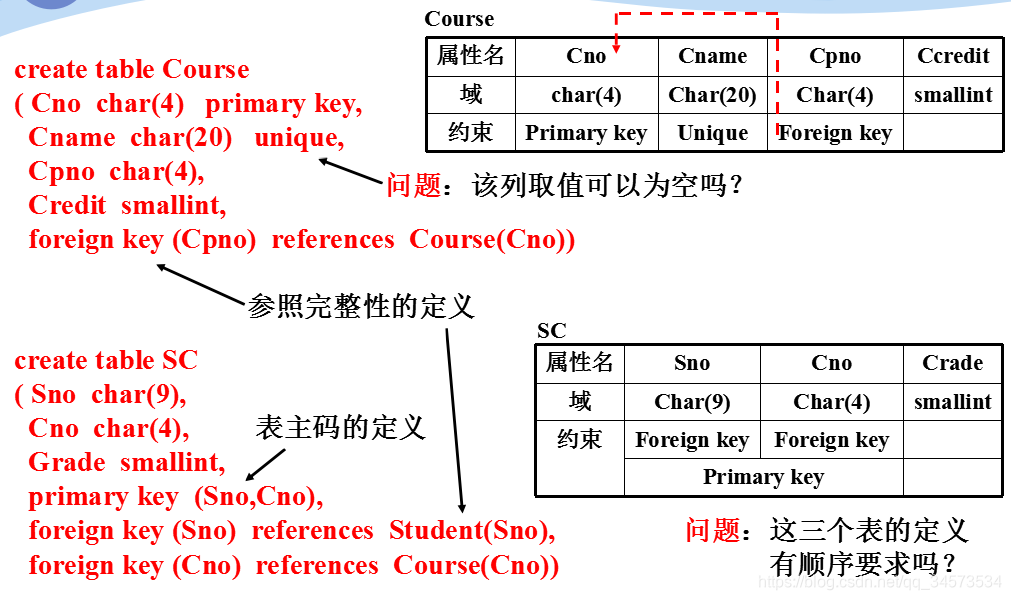
基本表数据的录入

基本表的常用维护操作
1、表重命名
exec sp_rename 'Student', 'stu'2、列重命名
exec sp_rename 'Student.Sname', 'name', 'column'3、添加新列
alter table Student add Sentrance datetime注意:新增列的数据为空。
4、更改列数据类型
alter table Student alter column Sage int注意:若表中已有数据,数据类型不相容时不能进行列数据类型的更改。
5、删除列
alter table Student drop column Sentrance6、删除表
drop table Student注意:若该表与其它表关联(如外键的参照等),则删除失败。
7、对表的常用维护操作还包括对表中约束的增删改问题,以后专门介绍。
数据查询

选择表中的若干列
1、查询全体学生的学号与姓名
select sno, sname
from student2、查询学生表的全部属性数据
select *
from student3、查询学校有哪些系
select sdept
from student问题:查询结果取消重复行吗?
结论:保留重复的元组。
4、取消查询结果中的重复元组
select distinct sdept
from student问题:该语句该如何理解?
select distinct sdept, ssex
from student结论:distinct关键词修饰后面的整个属性组。
注意:SQL Server不区分大小写。
属性列可以是表达式
问题:什么是表达式?
常量和变量是表达式;常量、变量、运算符、括号及函数的有效组 合是表达式。
1、查询全体学生的姓名与出生年份
select sname, 2012-sage
from student2、查询结果是什么?
select sname, 'Year of Birth', 2011-sage, lower(sdept)
from student3、问题:你知道SQL Server中都提供了哪些函数吗?查帮助啊!
属性列的别名
利用属性别名可改变查询结果的列标题名称,当然还可用于方便或清晰 表示查询命令的作用。
例如:
select sname NAME, 2011-sage BIRTHDAY
from studentselect 'Year of Birth' as birth, lower(sdept) as dept
from studentas 可省略
返回查询结果的前n行数据
利用 top n 可以得到查询结果的前n行记录的数。
select top 2 *
from studentselect top 2 sno, sname
from studentselect distinct top 3 ssex
from student1、top n 只能出现在第1个属性名之前;
2、select top 3 distinct ssex from student 语法错误;
3、当 n 大于结果行数时,则返回全部的查询结果。
into子句
1、自动创建一个新表,并将查询结果存入该新表。
select sno, cno
into xk
from sc注意:新 xk 表属性类型来自于 sc 表。但并不具有码、参照完整性等其它约束的定义。
2、将查询结果存入到一个新的临时表。
select cname, ccredit
into #kc
from course该表存入系统的tempdb数据库中。
注意:
1、可以对 #kc 表进行增删改查询操作。如:select * from #kc
2、该临时表将在会话期结束后被自动删除。
完成下列查询要求
1、求我校都哪些系招收学生了?
select distinct sdept from student2、求哪些学生选修了课程?求出他(她)们的学号。
select distinct sno from sc3、求哪些课程被学生选修了?求出它们的课程号。
select distinct cno from SC4、求我校所开设的全部课程的学分总和是多少?
select sum(credit) from course常用的查询条件

查询满足条件的元组
1、查询CS系全体学生的姓名。
select sname
from student
where sdept = 'CS'问题:若表中的数据值为小写的cs呢?
结论:SQL Server字符串内的字符不区分大小写。
2、查询所有年龄在20岁以下的学生姓名及年龄。
select sname, sage
from student
where sage < 20问题:含不含20?(自然语言不精确)
3、查询不是CS系的学生姓名。
select sname
from student
where sdept < > 'CS'问题:若sdept属性数据含有空值呢?
以Course关系的Cpno为例进行讨论。
结论:空值不参与比较运算。
涉及空值的查询
1、查询所有缺考的学生学号及相应的课程号。
select sno, cno
from sc
where grade is null注意:is 不能用 = 代替。
2、查询所有有成绩的学生学号及相应的课程号。
select sno, cno
from sc
where grade is not null谓词and、or、not
1、查询CS系年龄在20岁(不含20)以下的学生的姓名。
select sname
from student
where sdept = 'cs' and sage < 202、查询CS系和IS系全体学生的姓名及所在系。
select sname, sdept
from student
where sdept = 'cs' or sdept = 'is'3、查询不是CS系学生的姓名。
select sname
from student
where not sdept = 'cs'问题:你能理解吗?
问题:它的等价形式是什么?
select sname
from student
where sdept <> 'cs' 问题:该查询有什么问题吗?
select sname
from student
where sdept <> 'cs' or sdept is null问题:若student关系定义时对sdept属性有not null约束会怎样?此时则不必考虑空值问题。
谓词between…and…
1、查询年龄在20~23岁之间的学生的姓名及年龄。
select sname, sage
from student
where sage between 20 and 23问题:包括20和23吗?
结论:包括20和23。
2、查询年龄不在20~23岁之间的学生的姓名及年龄。
select sname, sage
from student
where sage not between 20 and 233、问题:你能利用其它运算写出上述两条查询的等价形式吗?
select sname, sage
from student
where sage >= 20 and sage <= 23select sname, sage
from student
where sage < 20 or sage > 23注意:在sage属性中仍存在空值问题。
谓词in
1、查询CS系、MA系和IS系全体学生的姓名和性别。
select sname, ssex
from student
where sdept in ('cs', 'ma', 'is')2、查询既不是CS系、MA系,也不是IS系的学生姓名和性别。
select sname, ssex
from student
where sdept not in ('cs', 'ma', 'is')问题:该查询对吗?
select sname, ssex
from student
where sdept not in ('cs', 'ma', 'is') or sdept is null3、问题:你能用其它运算写出上述两条查询的等价形式吗?
select sname, ssex
from student
where sdept = 'cs' or sdept = 'ma' or sdept = 'is'select sname, ssex
from student
where (sdept <> 'cs' and sdept <> 'ma' and sdept <> 'is') or sdept is null谓词like
| 运算符 |
含义 |
| % |
与任意长度的字符串匹配。(长度可为0) |
| _ |
与长度为0或1的单个字符匹配。(一个汉字当作单字符) |
| [ ] |
与指定范围内的单个字符匹配。如 [ 张王李 ] |
| [^ ] |
与不属于指定范围内的单个字符匹配。如 [ ^张王李] |
1、查询所有姓刘的学生姓名。
select sname
from student
where sname like '刘%'2、查询所有不姓刘的学生姓名。
select sname
from student
where sname not like '刘%'注意:这里仍涉及到空值问题。故该查询严格讲不准确。
select sname
from student
where sname not like '刘%'
or sname is null3、查询所有姓刘的但姓名只有两个字的学生姓名。
select sname
from student
where sname like '刘_'4、查询所有姓刘、姓李和姓张的学生姓名。
select sname
from student
where sname like '[刘李张]%'5、查询不姓李、不姓张,但名叫海燕的学生姓名。
select sname
from student
where sname like '[^李张]海燕'6、若查询字符串中本身含有通配符,则需要进行转义。
select sname
from student
where sname like '刘\_%' escape '\'
完成下列查询要求
1、求哪些学生还没有被分配系?
select * from student where sdept is null2、求CS系中所有男同学的学生姓名和年龄。
select sname,sage from student where sdept = 'cs' and ssex = '男'3、我校开设的课程中哪些课程名以“数据”两个字开头?
select cname from course where cname like '数据%'4、求哪些学生的姓名中第2个字是“立”?
select * from student where sname like '_立%'5、求哪些学生的成绩为优秀,求出该学生的学号及相应的课程号。
select sno,cno from sc where grade >= 906、求既不是CS系,也不是MA系的学生中年龄不小于20的学生姓名。
select sname from student where (sdept not in ('cs','ma') or sdept is null)
and sage >= 20或
select sname from student where ((sdept <> 'cs' and sdept <> 'ma') or sdept is null) and sage >= 20order by子句
1、查询所有学生的姓名和年龄,要求按年龄由小到大排序。
select sname, sage
from student
order by sage asc注意:asc 可以省略,即默认为升序。
2、查询CS系的全体学生,要求按年龄升序排列,年龄相同的按姓名的降序排列。
select *
from student
where sdept = 'cs'
order by sage, sname desc3、问题:若排序属性列上有空值,则如何排序呢?
结论:空值当成最小值。
top n with ties子句
在有order by子句时,可以使用top n with ties子句。
select top 1 with ties *
from student
order by sage该语句的功能是查询出所有年龄最小的学生的全部属性数据。
注意:若使用top n with ties时,则返回结果不一定只有n行记录,而是和排序后的第n行记录的排序列取值相同的所有行都会被查询出来。
又如:查询不及格的学生中成绩最低的学生学号。
select top 1 with ties sno
from sc
where grade < 60
order by grade再如:求1号课程考试成绩前10名学生的学号。
select top 10 with ties sno
from sc
where cno = '1'
order by grade desc聚集函数
| 聚集函数 |
含义 |
| count([distinct] *) |
统计元组个数 |
| count([distinct] <列名>) |
统计一列中值的个数 |
| sum([distinct] <列名>) |
计算一列值的总和(此列必须是数值型) |
| avg([distinct] <列名>) |
计算一列的平均值(此列必须是数值型) |
| max([distinct] <列名>) |
求一列值中的最大值 |
| min([distinct] <列名>) |
求一列值中的最小值 |
注意:
1、没有分组时,函数是在整个查询结果的基础上进行计算。
2、<列名> 只能是一个列名。
3、应用avg函数时若列为整型类型,则计算结果也为整型,并进行下取整。
4、除count(*)函数外,其它聚集函数都跳过空值而只处理非空值。
聚集函数的使用
1、查询学生总人数。
select count(*)
from student2、查询选修了课程的学生总人数。
select count(distinct sno)
from sc3、计算选修1号课程的学生平均成绩。
select avg(grade)
from sc
where cno = '1'问题:若grade属性上有空值,则该平均值是什么含义?
注意:除count(*)函数外,其它聚集函数都跳过空值而只处理非空值。
问题:若将grade属性为空值的学生成绩计为0分,则如何计算平均成绩?
select sum(grade)/count(*)
from sc
where cno='1'
分组
分组:将某个表或查询结果按某一列或多列的值分组,即值相等的为一组。

可见,空值参与分组。
group by子句


切记:分组后聚集函数将作用于每一个分组,即每一个组都有一个函数值。
group by子句应用示例
1、求每门课程号及相应的选课人数。
select cno 课程号, count(*) 选课人数
from sc
group by cno2、求每门课程的课程号、选课人数及该课的平均成绩。
select cno 课程号, count(*) 总人数, sum(grade)/count(*) 平均分
from sc
group by cno或
select cno 课程号, count(*) 总人数, avg(grade) 平均分
from sc group by cno3、求每个学生的学号及其平均成绩。
select sno 学号, avg(grade) 平均分
from sc
group by sno或
select sno 学号, sum(grade)/count(*) 平均分
from sc group by sno注意:实际应用中如何选择平均值的计算方法需由用户认可。
问题:如何查询平均成绩及格的学生学号及其平均成绩?
having短语
| Sno |
Cno |
Crade |
| 2008001 |
1 |
90 |
| 2008001 |
2 |
87 |
| 2008002 |
1 |
50 |
| 2008003 |
3 |
1、求平均成绩及格的学生学号及其平均成绩。
select sno, avg(grade)
from sc
group by sno
having avg(grade) >= 602、求选修了3门以上课程的学生学号。
select sno
from sc
group by sno
having count(*) > 33、问题:having短语与where子句有什么区别吗?作用对象不同:前者作用于每个分组,后者作用于表或视图。
分组查询应用举例
1、求CS系中男女学生的数量分别是多少?
select ssex, count(*)
from student
where sdept = 'cs'
group by ssex2、求各系中每个年龄段的学生总人数,要求结果中对系进行排序,同一个系的按年龄排序。即想得到右表所示的结果。
| sdept |
sage |
snum |
select sdept, sage, count(*) snum
from student
group by sdept, sage
order by sdept, sage即用来确定分组的属性可以是一个属性组。
3、假定有如下关系,求每一年每一个月份的收入总和。
create table S
( 日期 datetime,
收入 int )| Year |
Month |
Total |
select year(日期) Year, month(日期) Month, sum(收入) Total
from s
group by year(日期), month(日期)即用来确定分组的可以是属性的表达式。
连接查询

连接查询示例
1、求选修了1号课程的学生姓名。
select sname
from student, sc
where student.sno = sc.sno and cno = '1'2、求选修了2号课程且成绩为优秀的所有学生学号和姓名。
select student.sno, sname
from student, sc
where student.sno = sc.sno and cno = '2' and grade >= 903、求选修了DB课程的学生学号和姓名。(即打印课程的学生名单)
select student.sno, sname
from student, sc, course
where student.sno = sc.sno and course.cno = sc.cno and cname = 'DB'
自身连接

左外连接
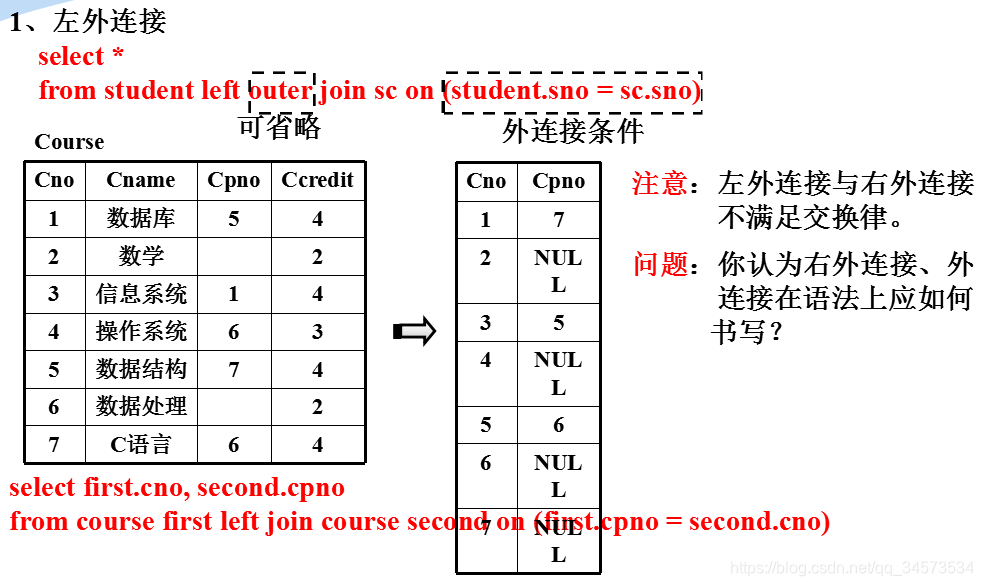
右外连接、外连接
1、右外连接
select *
from student right outer join sc on (student.sno = sc.sno)2、外连接
select *
from student full outer join sc on (student.sno = sc.sno)3、求IS系全体学生的选课情况。
select *
from student left join sc on (student.sno = sc.sno)
where sdept = 'IS'注意:where子句的条件不能写在外连接条件处。
问题:如果不用外连接会出现什么结果?即
select *
from student, sc
where sdept = 'IS' and student.sno = sc.sno关于连接与外连接的语法格式

完成下列查询要求
1、打印李勇的成绩单(即求李勇所选修的课程名及其成绩)。
select cname, grade
from student, course, sc
where student.sno=sc.sno and course.cno=sc.cno and sname='李勇'2、求不及格和缺考的学生所在系、学号、姓名及相应课程名,要求查询结果按系排序,同一个系的按学号排序。
select sdept, student.sno, sname, cname
from student, course, sc
where student.sno=sc.sno and course.cno=sc.cno and (grade<60 or grade is null)
order by sdept,student.sno3、求CS系不及格和缺考的学生学号、姓名及相应课程名,要求按学号排序。
select student.sno, sname, cname
from student, course, sc
where student.sno=sc.sno and course.cno=sc.cno and (grade<60 or grade is null)
and sdept='cs'
order by student.sno4、求既不是CS系,也不是MA系缺考学生的学号、姓名及相应课程名。
select student.sno, sname, cname
from student, course, sc
where student.sno=sc.sno and course.cno=sc.cno and grade is null
and (sdept not in('cs','ma') or sdept is null)5、求选修BD课程的学生平均成绩。
select avg(grade) from course, sc where course.cno=sc.cno and cname='DB'6、求每一门课程的学生平均成绩,要求输出课程名及对应的平均成绩,并按平均成绩由大到小排序。
select cname, avg(grade) agrade
from course, sc
where course.cno=sc.cno
group by cname
order by agrade desc7、求李勇所选修的总学分(即成绩及格的课程学分总和)。
select sum(credit)
from student, course, sc
where student.sno=sc.sno and course.cno=sc.cno
and sname='李勇' and grade>=60嵌套查询
求选修了1号课程的学生姓名。
select sname
from student, sc
where student.sno = sc.sno and cno = '1'换个思路。
select sname
from student
where sno in
( select sno
from sc
where cno = '1' )特点:内层子查询条件中所涉及的属性与外层无关。将这样的子查询称为不相关子查询。
问题1:你认为该语句是怎么执行的?
问题2:哪种表达方式好?
问题3:你还有别的办法吗?

1、求没选修1号课程的学生姓名。
select sname
from student, sc
where student.sno = sc.sno and cno <> '1'问题:该语句的执行结果是什么?它对吗?
2、下列语句的执行结果是什么?
select sname
from student
where sno not in
( select sno
from sc
where cno = '1' )3、求不是CS系的学生姓名。
select sname
from student
where sdept <> 'cs' or sdept is null问题:该语句正确吗?
4、问题:你能理解吗?
嵌套查询示例

相关子查询

不相关子查询与相关子查询比较
不相关子查询:即子查询的条件中不涉及外层关系的属性。
执行过程为:由里向外逐层处理。即每个子查询在上一层查询处理之前求解,子查询结果用于建立上一层查询的查找条件。
相关子查询:即子查询的条件中涉及外层关系的属性。
执行过程为:首先取外层查询表中的第一个元组,利用该元组值执行内层查询,若此时子查询结果使外层的Where子句表达式为真,则该元组的相应属性值放入结果表;然后再取外层表的下一个元组,重复上述过程,直至外层表的全部元组处理完毕为止。
注意:子查询内不可以使用order by子句。
相关子查询示例

exists谓词

问题:求没选修1号课程的学生姓名。
select sname
from student
where not exists
( select *
from sc
where student.sno = sno and cno = '1')问题:你能理解吗?若不采用exists谓词,你能完成查询吗?
select sname
from student
where sno not in
( select sno
from sc
where cno = '1' )

any(some)、all谓词

any(some)、all谓词举例

union、interset、except子句

插入数据


插入子查询结果

修改数据


删除数据




什么是索引?

索引小结
1、建立索引的目的是为了加快查询速度。 (你能理解吗?加快查找、连接、排序、分组、参照完整性的检查等)
2、索引分为聚集索引和非聚集索引两大类。
3、聚集索引针对表中数据在索引项上直接进行物理排序。
4、若属性有primary key约束,则针对该主码自动建立聚集索引。
5、一个表只能建立一个聚集索引。
6、若属性有unique约束,则针对该属性自动建立唯一非聚集索引。
7、若表中某列已有数据,且数据中有重复值,则建立唯一索引将会失败。
8、针对某列创建唯一索引,可保证该列数据取值的唯一性,相当于在该列上定义了unique约束。
9、一个表中可建立多个索引,甚至是索引名不同,而内容相同的索引。
10、索引需要占用物理存储空间,且该空间随表中数据的增大而增大。
11、对表中数据进行增删改时,索引的存在会降低数据更新速度。
索引的建立与删除
1、建立聚集索引
create clustered index CI_Student_Sno on student(sno)索引默认为升序
2、建立聚集唯一索引
create unique clustered index CUI_Student_Sno on student(sno)3、建立非聚集唯一索引
create unique index UI_Student_Sno on student(sno)4、建立非聚集不唯一索引
create index idx_Student_Sno on student(sno)5、在多个列上建索引并指定升序或降序
create index idx_SC_Sno_Cno on sc(sno asc, cno desc)6、索引删除
drop index idx_Student_Sno on student什么情况下需要建立索引?
下列情况需要我们考虑是否应该建立索引。
1、是否会针对某属性频繁进行比较运算的查询?
2、是否会针对某属性频繁进行连接运算?
3、是否会针对某属性频繁进行排序和分组运算?
4、上述操作针对的属性是不是不是表的主码?
5、表的数据量是否很大?
6、是否对表中数据的增删改操作很少?
7、是否建立索引后不会严重地影响系统效率?
若以上问题的回答基本上均为“是”,则需要考虑在那些属性上建立索引。 所建索引的类型一般与索引列的数据取值特点和要求有关。
注意:一个基本表上最好不要建立很多索引。
连接查询的可能执行过程

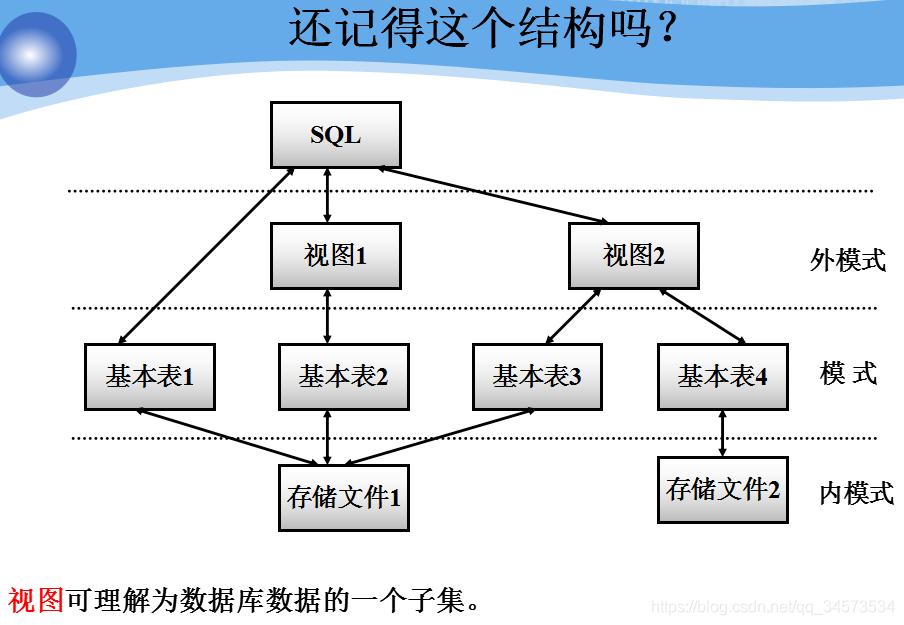
视图及其创建

视图定义示例
1、定义CS系学生的视图。
create view CS_S(sno, sname, ssex, sage)
as
select sno, sname, ssex, sage
from student
where sdept = 'cs'2、定义IS系学生的视图。
create view IS_S(ISsno, ISsname, ISsex, ISsage)
as
select sno, sname, ssex, 2011-sage
from student
where sdept = 'is'可见,视图的列名可以与基本表的列名相同,也可以不相同。
查看视图的定义信息:
exec sp_helptext cs_s3、定义MA系学生的视图。
3、定义MA系学生的视图。
create view MA_S
as
select sno, sname, ssex, sage
from student
where sdept = 'ma'即视图定义时可省略列名,但不是好习惯。
4、定义CS系选修了1号课程的学生视图。
create view CS_Cno_1(sno, sname, grade)
as
select student.sno, sname, grade
from student, sc
where student.sno = sc.sno and sdept = 'cs' and cno = '1'即视图可以建立在多个基本表之上。
5、定义CS系选修1号课程且成绩为优秀的学生视图。
create view CS_Cno1_90(sno, sname, grade)
as
select sno, sname, grade
from cs_cno_1
where grade >= 90即视图可定义在其它视图之上。
6、定义每名学生及其平均成绩的视图。
create view S_AG(sno, Gavg)
as
select sno, avg(grade)
from sc
group by sno该视图也称为分组视图。分组视图在定义时必须给出列名。
删除视图

视图的查询
可以像对基本表一样对视图进行查询。
1、查询CS系中年龄小于20的学生姓名。
select sname
from cs_s
where sage < 202、查询选修1号课程的IS系学生学号和姓名。
select issno, issname
from is_s, sc
where is_s.issno = sc.sno and cno = '1'3、查询平均成绩90分以上的学生学号及其平均成绩。
select *
from s_ag
where gavg >= 90问题:你知道它们是怎么执行的吗?
视图的消解

视图的更新

with check option子句



视图的可更新性和视图的基本作用
行列子集视图:从单个基本表导出的,且只是去掉了基本表的某些行和某些列,但保留了主码,这类视图称行列子集视图。
结论:行列子集视图是可更新的。
除行列子集视图外,有些视图是可更新的,但确切特征尚待研究;还有些 视图从理论上就是不可更新的。目前,不同的DBMS有不同的规定。应用时要 小心谨慎!
视图的基本作用:
1、视图能够简化用户的操作;
2、视图使用户能以多种角度看待同一数据;
3、视图对重构数据库提供了一定程度的逻辑独立性;
4、视图能够对机密数据提供安全保护;
5、适当地利用视图可以更清晰地表达查询。
习题


