本文开头附:Flink 学习路线系列 ^ _ ^
1.Table API & SQL
开头附上:Flink Table API & SQL 英文官方文档
1.1 背景
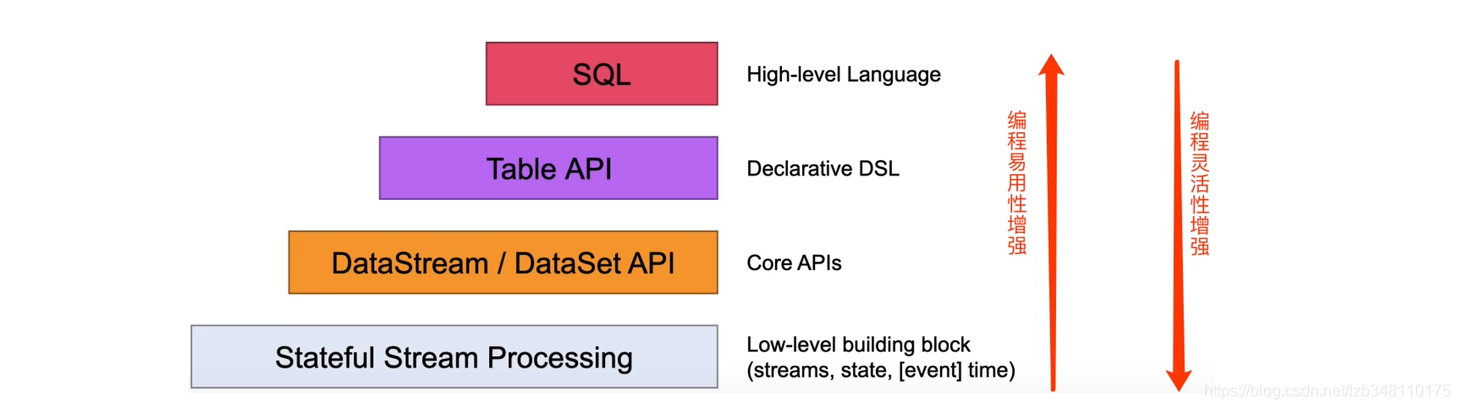
Flink虽然已经拥有了强大的 DataStream / DataSet API,而且使用非常的灵活,但是需要熟练使用 Java 或者 Scala 的 Flink 编程 API 来编写程序。为了满足流计算(实时计算)和批计算(离线计算)中的各种场景需求,同时降低用户的使用门槛,Flink 提供了一种关系型的 API 来实现流处理与批处理的统一,那么这就是 Flink 的 Table & SQL API。
1.2 特点
Table & SQL API 是一种关系型 API,用户可以像操作 MySQL 数据库表一样的操作数据,而不需要写 Java 代码来完成 Flink 代码,更不需要手工的优化 Java 代码调优。另外,SQL 学习成本很低,如果一个系统提供 SQL 支持,将很容易被用户接受。
- Table API & SQL 是关系型声明式的,是处理关系型结构化数据的;
- Table API & SQL 批流统一,支持 Stream 流计算和 Batch 离线计算;
- Table API & SQL 查询能够被有效的优化,查询可以高效的执行;
- Table API & SQL 编程比较容易,但是灵活度没有 DataStream/DataSet API 强。
1.3 环境创建
1.3.1 BatchTableEnvironment(离线批处理Table API )
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment batchEnv = BatchTableEnvironment.create(env);
1.3.2 StreamTableEnvironment(实时流处理Table API )
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment batchEnv = StreamTableEnvironment.create(env);
1.4 添加 Maven 依赖
<properties>
<flink.version>1.9.1</flink.version>
<scala.binary.version>2.11</scala.binary.version>
</properties>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
1.5 来个案例
1.5.1 实时 WordCount 例子
1.使用SQL 的例子:
/**
* TODO WordCount 使用 SQL Demo
*
* @author liuzebiao
* @Date 2020-2-26 10:37
*/
public class StreamWordCountSQLAPIDemo{
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//创建一个实时的 Table 执行上下文环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<String> wordStream = lines.flatMap((String line,Collector<String> out)->
Arrays.stream(line.split(",")).forEach(out::collect)
).returns(Types.STRING);
//将 wordStream 流注册成表(表名为:word_count)
//多字段使用逗号分隔。如:"word,count"
tableEnv.registerDataStream("word_count",wordStream,"word");
//SQL
String sql = "select word t0,count(1) as t1 from word_count group by word";
//执行SQL
Table table = tableEnv.sqlQuery(sql);
//如下三种均可(WordCount为实体类,ROW为Flink提供的一个拥有多个属性的类)
// DataStream<Tuple2<Boolean, Tuple2<String,Long>>> dataStream = tableEnv.toRetractStream(table, Types.TUPLE(Types.STRING, Types.LONG));
// DataStream<Tuple2<Boolean, Tuple2<String,Long>>> dataStream = tableEnv.toRetractStream(table, WordCount.class);
DataStream<Tuple2<Boolean, Row>> dataStream = tableEnv.toRetractStream(table, Types.ROW(Types.STRING, Types.LONG));
dataStream.print();
env.execute("StreamWordCountSQLAPIDemo");
}
}
2.使用 Table API 的例子:
/**
* TODO WordCount TABLE API Demo
*
* @author liuzebiao
* @Date 2020-2-26 10:37
*/
public class StreamWordCountTableAPIDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//创建一个实时的 Table 执行上下文环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<String> wordStream = lines.flatMap((String line,Collector<String> out)->
Arrays.stream(line.split(",")).forEach(out::collect)
).returns(Types.STRING);
//将 wordStream 流注册成表(表名为:word_count)
tableEnv.registerDataStream("word_count",wordStream,"word");
Table table = tableEnv.fromDataStream(wordStream, "word");
Table resTable = table.groupBy("word").select("word,count(1) as counts");
//将 Table 转换成 DataStream
DataStream<Tuple2<Boolean, Row>> dataStream = tableEnv.toRetractStream(resTable, Types.ROW(Types.STRING, Types.LONG));
//打印结果
dataStream.print();
env.execute("StreamWordCountTableAPIDemo");
}
}
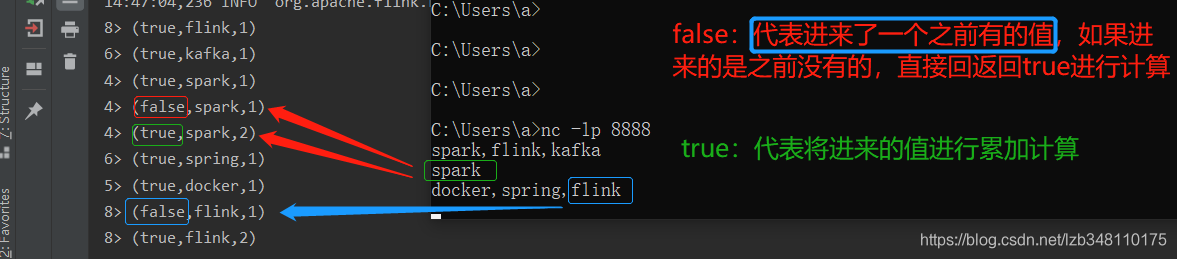
3.测试结果:
1.5.2 离线 WordCount 例子
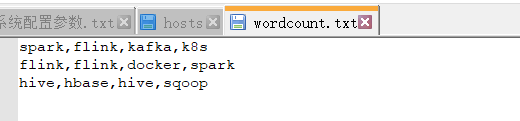
离线文档:
1.使用 SQL 的例子:
/**
* TODO 离线 WordCount SQL Demo
*
* @author liuzebiao
* @Date 2020-2-26 10:37
*/
public class BatchWordCountSQLAPIDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//创建一个实时的 Table 执行上下文环境
BatchTableEnvironment batchEnv = BatchTableEnvironment.create(env);
DataSource<String> lines = env.readTextFile("C:\\Users\\a\\Desktop\\wordcount.txt");
FlatMapOperator<String, String> wordDataSet = lines.flatMap((String line, Collector<String> out) ->
Arrays.stream(line.split(",")).forEach(out::collect)
).returns(Types.STRING);
//将 wordDataSet 流注册成表(表名为:word_count)
batchEnv.registerDataSet("word_count",wordDataSet,"word");
//SQL
String sql = "select word,count(1) from word_count group by word having count(1) >= 2 order by count(1) desc";
//执行SQL
Table table = batchEnv.sqlQuery(sql);
//如下三种均可(WordCount为实体类,ROW为Flink提供的一个拥有多个属性的类)
DataSet<Row> dataSet = batchEnv.toDataSet(table, Types.ROW(Types.STRING, Types.LONG));
dataSet.print();
}
}
2.使用 Table API 的例子:
/**
* TODO WordCount Table API Demo
*
* @author liuzebiao
* @Date 2020-2-26 10:37
*/
public class BatchWordCountTableAPIDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//创建一个实时的 Table 执行上下文环境
BatchTableEnvironment batchEnv = BatchTableEnvironment.create(env);
DataSource<String> lines = env.readTextFile("C:\\Users\\a\\Desktop\\wordcount.txt");
FlatMapOperator<String, Tuple2<String, Long>> wordDataSet = lines.flatMap((String line, Collector<Tuple2<String, Long>> out) ->
Arrays.stream(line.split(",")).forEach(str -> out.collect(Tuple2.of(str, 1l)))
).returns(Types.TUPLE(Types.STRING, Types.LONG));
//将 wordDataSet 流注册成表(表名为:word_count)
Table table = batchEnv.fromDataSet(wordDataSet,"word,num");
Table resultTable = table
.groupBy("word")//分组
.select("word, num.sum as counts")//sum求和
.filter("counts >= 2")//过滤
.orderBy("counts.desc");//排序
//如下三种均可(WordCount为实体类,ROW为Flink提供的一个拥有多个属性的类)
DataSet<Row> dataSet = batchEnv.toDataSet(resultTable, Types.ROW(Types.STRING, Types.LONG));
dataSet.print();
}
}
3.测试结果:

Table API & SQL 部分,介绍到此为止
文章都是博主用心编写,如果本文对你有所帮助,那就给我点个赞呗 ^ _ ^
End
