一、Mapduce概观(MapReduce是一个计算软件框架、可以在集群上并行处理数据集。)
1.Hadoop MapReduce是一个软件框架,用于轻松编写应用程序,以可靠,容错的方式在大型集群(数千个节点)的商用硬件上并行处理大量数据(多TB数据集)。
2.MapReduce是Hadoop的两大核心技术之一,HDFS解决了大数据存取问题,而MapReduce是对大数据的高效并行编程模型。
3.MapReduce任务分为两个阶段:map与reduce;每阶段都是以键值对(key-value)作为输入和输出的;在执行mapreduce任务时,一个大数据集会被划分为许多独立的的数据块,称为输入分片。hadoop为每个分片构建一个map任务,即运行自定义的map函数,处理分片中的每一条记录。map阶段处理后的结果会作为reduce阶段的输入,最后由reduce函数处理并输出最终结果,并吸入文件系统中。
4.MapReduce框架由单个主ResourceManager,每个集群节点一个从NodeManager和每个应用程序的MRAppMaster组成。
5.Hadoop 作业客户端将作业(jar /可执行文件等)和配置提交给ResourceManager,然后ResourceManager负责将软件/配置分发给从站,调度任务并监视它们,为作业提供状态和诊断信息 -客户。
二、MapReduce进行作业时分为两个阶段(Map阶段和Reduce阶段)
1.MapReduce模型的核心是Map函数和Reduce函数;Map函数和Reduce函数都是以key-value作为输入,
按一定的映射规则转换成另一批key-value输出。
2.该键和值类必须由框架序列化,因此需要实现可写接口。此外,关键类必须实现WritableComparable接口以便于按框架进行排序。
3.MapReduce作业的输入和输出类型:
(输入)<k1,v1> - > map - > <k2,v2> - > combine - > <k2,v2> - > reduce - > <k3,v3>(输出)
- Map:(K1,V1) ➡ list((K2,V2))
- Reduce:(K2,list(V2)) ➡ list(K3,V3)
可以理解为:
- map阶段:将数据集分解为一批分片(K1,V1),map函数对每一个分片进行处理输出一批(K2,V2)
- reduce阶段:接收来自map阶段的(K2,V2),并将相同key值的键值对整合成(K2,list(V2)),最后做执行redeuce函数,输出一批(K3,V3)
即:map函数键值对的输出类型与reduce函数的输入类型一定是相同的;
reduce阶段:接收来自map阶段的(K2,V2),并将相同key值的键值对整合成(K2,list(V2)),最后做执行redeuce函数,输出一批(K3,V3)
三、Map函数与Reduce函数
1.Map阶段对应Map函数

输入分片中的每一个键值对(每一行)都会调用一次map函数,图上的map函数是Mapper类里的,它用context对Key,和Value直接进行输出,KV怎么进来的怎么出去,所以往往我们继承Mapper类重写其map方法。
2.Reduce阶段对应reduce函数

在reduce函数中,对map输入进来的values集合进行遍历输出,同样每一个键值对调用一次reduce函数。
3.我一个文件有多行,为什么在写map,reduce函数时都是针对于其中的一行?
我们可以打开map,和reduce的源码看看
在Mapper类中:

在Reducer类中:

我们可以在Mapper,Reducer类中看到都有一个run方法,run方法里循环去调用我们重写的map,reduce函数,即一个文件的多行处理真正的逻辑在run()里。
Context类对象用于输出键值对
四、wordcount实例
首先我们要理清楚分别在map和reduce阶段应该干些什么:
1.map阶段获取所有文件中的每一行作为输入分片,此时key为每一行在各自文件中的偏移量,value为对应偏移量的一行数据,此时的偏移量并不是我们关心的数据。
2.然后运行map函数对每一行拆分为多个单词,此时key为单词,value为一个标记(可记为1,表示该单词出现了一次,但并不是该单词出现的总次数),比如一个单词出现了两次,就会有两个对应的键值对;
如:hello world welcome to china <0,"hello world welcome to china"> --------> <"hello",1> <"world","1">
hello kitty <29,"hello kitty"> --------> <"hello",1> <"kitty",1>
3.reduce阶段:
reduce阶段接收到map函数输出的一堆键值对,先将key值相同的键值对的value值整合在一起,构成一个key为单词,value为对应的标记的集合,该集合的长度即为单词出现的总次数。所以再运行reduce函数计算每个value值中集合的长度,输出key为单词,value为对应单词出现次数的键值对。
如:
hello【1,1】 world【1】 kitty【1】
-->hello【2】 world【1】 kitty【1】
五、worldcount代码实现
1.map类

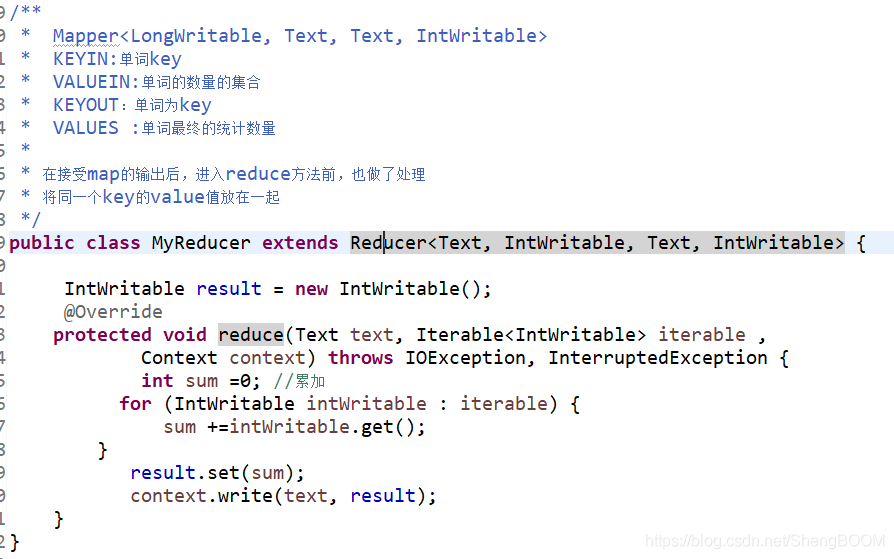
2.reduce类
3.Driver类

运行在集群中
将程序打包为jar文件,注意指定含main方法的主类,上传到集群中,通过以下命令运行jar包:
hadoop jar wordcount.jar 文件路径 结果输出路径
