Cross-X Learning for Fine-Grained Visual Categorization
本文提出了一种利用不同图像之间以及不同网络层之间的关系进行鲁棒的多尺度特征学习的框架。
问题陈述
细粒度视觉分类:由于类内差异大而类间差异小,从具有非常细微差异的子类别中识别对象是一项艰巨的任务。
目前的常见弱监督方式解决细粒度识别问题:首先检测对象部件,然后提取相应部分特征进行细粒度分类,但这些方法通常会单独处理每个图像的部分特定特征,而忽略它们在不同图像之间的关系。
概述
通过大量的实验,我们观察到,细粒度分类中的有效注意力机制应该满足三个条件:1.检测到的部分应该很好的分布在物体上以提取不相关的特征;2.每个部分的特征都能够用来区分类别;3.部位提取模型应该是轻量级的,以便按比例扩展到实际应用中。为了满足这些需求,提出了包含两个改进部分的新奇框架。首先,one-squeeze-multi-excitation模块能够定位不同部位,OSME能够直接提取部位特征,相对其他方法而言,不需要先cropping目标部位,然后前向传播提取特征。其次,受度量学习的激发,提出了多注意了多类别约束,以在细粒度对象分类器的训练过程中强制分析不同部位之间的相关性。MAMC鼓励相同注意力相同类别之间的特征比不同注意力或者不同类别之间的特征距离更近。
OSME结构
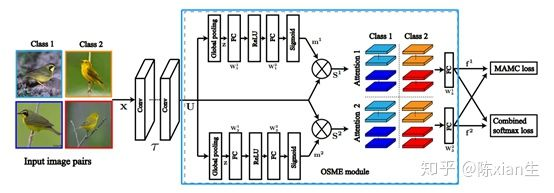
给定4个输入图像,包含两个类别,每个类有2张图像。这四张图像经过OSME模块产生多个注意力区域,图中示意的每个图像产生两个注意力区域,那么现在就会分为这几种情况:1.类别1的区域1 ;2.类别1的区域2;3.类别2的区域1;4.类别2的区域2. 然后将这四种情况按某种方式用MAMC损失和softmax损失共同训练网络。在测试的时候只采用softmax。
OSME注意力模型
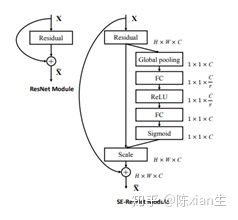
选择SENet的原因是在实际应用中其性能和扩展性的优越性。
ResNet50作为基础网络,假设 x
作为输入,被输入到最后一个残差块中。SEResNet的具体结构如下:
在第一步的一次挤压中,我们在空间维度W*H上聚合特征映射U以产生channel-wise描述子z=[z1, z2,…,zc],通过采用全局平均池化的方式能够简单并且高效的描述每个通道的统计特性: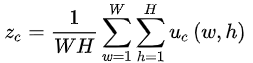
在第二步的多次激发中,对于每个注意力p需要在z上单独使用门控机制,p=1,2,…,P。


参考阅读
弱监督方式的FGVC:利用细粒度标签之间的关系来约束特征学习和定位判别性部分来提取特定部分特征;基于局部化的方式,具有从局部性区域提取细粒度特征的优点(子类别之间的细微差异通常存在于局部区域)
***介绍了早期的多阶段学习框架和近期的端到端学习框架并分析了这些模型改进有限的原因:***优化度量学习损失具有挑战性;涉及一个非平凡的样本选择过程。

