mongodb副本集配置
最近项目中用到了mongodb,由于是用mongodb来记录一些程序的日志信息和日常的统计,为了增加应用的可靠性,一直在找mongodb集群的一些资料,下面是对最近做的一个小案例过程进行了一下总结记录。
一.先介绍一下副本集是什么?
副本集(复制)是将数据同步到多台服务器的过程,提供的数据的冗余备份,并且在多个服务器上存储数据的副本,提高了数据的可用性,也降低了数据的损坏风险,提高的安全性,并且可以实现故障的自动的切换恢复。
二.副本集的组成结构是什么?
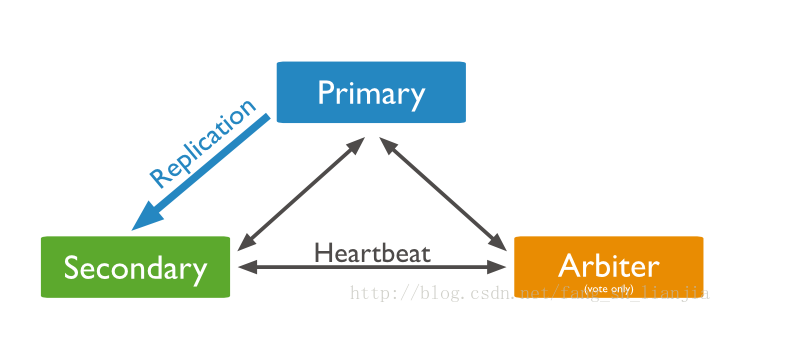
一个副本集的最小结构有用三个成员。一个三个成员的副本集可以有三个成员保存数据,或者有两个保存,一个为监督者。即一个主节点(Primary),一个从节点(Secondary),一个监督者(Arbiter),监督者不存储数据,监督者的作用主要是当主节点不可用时从从节点中选中主节点。如下图:
三.下面我们就按步骤小试牛刀一下?
第一步:
我们在本机的1001、1002和1003三个端口上启动三个不同的Mongodb实例;
mongod --port 1001 --dbpath F:/mongos/mongodb1/data --logpath F:/mongos/mongodb1/log/mongodb.log --pidfilepath F:/mongos/mongodb1/mongodb1.pid
--replSet test --logappend --directoryperdb mongod --port 1002 --dbpath F:/mongos/mongodb2/data --logpath F:/mongos/mongodb2/log/mongodb.log --pidfilepath F:/mongos/mongodb2/mongodb2.pid
--replSet test --logappend --directoryperdb mongod --port 1003 --dbpath F:/mongos/mongodb3/data --logpath F:/mongos/mongodb3/log/mongodb.log --pidfilepath F:/mongos/mongodb3/mongodb3.pid
--replSet test --logappend --directoryperdb
第二步:
登录到1001实例上编写指令,将三个不同的Mongodb实例结合在一起形成一个完整的副本集;
cd F:\mongos\mongodb1\bin
mongo 127.0.0.1:1001
use admin
config_test={_id:"test",members:[
{_id:0,host:"127.0.0.1:1001",priority:1},
{_id:1,host:"127.0.0.1:1002",priority:1},
{_id:2,host:"127.0.0.1:1003",arbiterOnly:true},
]};
到这里,members中可以包含多个值,这里列举的就是刚才启动的三个Mongodb实例,并且通过_id字段给副本集起了名字test。
第三步:
通过执行下面的命令初始化副本集。
rs.initiate(config_test);
下面的命令可以查看副本集的状态。
rs.status();
到这里搭建起一个由三个Mongodb实例构成的名称为test的副本集了。
副本集现在搭建起来了,那么这个副本集能不能解决我们上面主从模式的两个问题呢?
我们首先从第一个问题开始看,我们将1001端口的Mongodb服务器给关闭,然后我们使用rs.status()命令来查看下,如下所示:
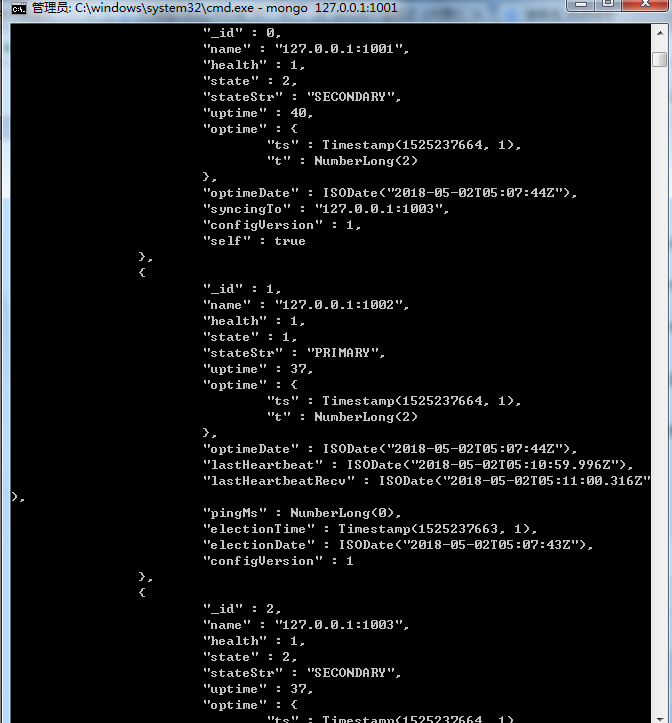
从返回包信息中,可以看到关闭1001端口后,在副本集节点的状态中该节点是不可达的,重新选取产生的主节点是1002端口上启动的Mongodb实例,选举过程是这样的,当主节点挂掉之后,其他节点可以发起选举行为,只要在选举过程中某个节点得到副本集节点数一半以上的选票并且没有节点投反对票,那么该节点就可以成为主节点。(参数注释请看开始位置)在1001端口上的Mongodb实例挂掉之后,1002成为了新的主节点,可以实现故障自动切换。
至于第二个问题,那就是主节点负责所有的读写操作造成主节点压力较大,那么在副本集中如何解决这个问题了呢?正常情况下,我们在Java中访问副本集是这样的,如下所示:
public class TestMongoDBReplSet {
public static void main(String[] args) {
try {
List<ServerAddress> addresses = new ArrayList<ServerAddress>();
ServerAddress address1 = new ServerAddress("127.0.0.1",1001);
ServerAddress address2 = new ServerAddress("127.0.0.1",1002); ServerAddress address3 = new ServerAddress("127.0.0.1",1003); addresses.add(address1); addresses.add(address2); addresses.add(address3); MongoClient client = new MongoClient(addresses); DB db = client.getDB( "testdb"); DBCollection coll = db.getCollection( "testdb"); // 插入 BasicDBObject object = new BasicDBObject(); object.append("userid","001"); coll.insert(object); DBCursor dbCursor = coll.find(); while (dbCursor.hasNext()) { DBObject dbObject = dbCursor.next(); System. out.println(dbObject.toString()); } } catch (Exception e) { e.printStackTrace(); } } }
但是上面不能做到在副本集中读写压力分散,在代码层面我们可以设置再访问副本集的时候只从副节点上读取数据。为了在副本集上实现读写分离,我们需要实现以下两步:
(1)在副本节点上设置setSlaveOk;
(2)代码层面,在读操作过程中设置从副本节点读取数据,如下所示:
public class TestMongoDBReplSet {
public static void main(String[] args) {
try {
List<ServerAddress> addresses = new ArrayList<ServerAddress>();
ServerAddress address1 = new ServerAddress("127.0.0.1",1001);
ServerAddress address2 = new ServerAddress("127.0.0.1",1002);
ServerAddress address3 = new ServerAddress("127.0.0.1",1003);
addresses.add(address1);
addresses.add(address2);
addresses.add(address3);
MongoClient client = new MongoClient(addresses);
DB db = client.getDB( "test");
DBCollection coll = db.getCollection( "test");
BasicDBObject object = new BasicDBObject();
object.append("userid","001");
ReadPreference preference = ReadPreference.secondary();
DBObject dbObject = coll.findOne(object, null , preference);
System. out .println(dbObject);
} catch (Exception e) {
e.printStackTrace();
}
}
}
上面代码中的读参数除了secondary以外,还有其他几个参数可以使用,他们的含义分别如下所示:
primaryPreferred:大部分从主节点上读取数据,只有主节点不可用时从secondary节点读取数据。
secondary:只从secondary节点上进行读取操作,存在的问题是secondary节点的数据会比primary节点数据“旧”。
secondaryPreferred:优先从secondary节点进行读取操作,secondary节点不可用时从主节点读取数据;
nearest:不管是主节点、secondary节点,从网络延迟最低的节点上读取数据。
四.最后对使用到的参数进行了一下总结方便以后记忆和复习?
dbpath:数据存放目录
logpath:日志存放路径
pidfilepath:进程文件,方便停止mongodb
directoryperdb:为每一个数据库按照数据库名建立文件夹存放
logappend:以追加的方式记录日志
replSet:replica set的名字
bind_ip:mongodb所绑定的ip地址
port:mongodb进程所使用的端口号,默认为27017
oplogSize:mongodb操作日志文件的最大大小。单位为Mb,默认为硬盘剩余空间的5%
fork:以后台方式运行进程
noprealloc:不预先分配存储
priority:优先级,返回时0-100,数组越大,优先级越高,默认是1,0不进行选举