目录
1. A-Softmax的推导
2. A-Softmax Loss的性质
3. A-Softmax的几何意义
4. 源码解读
A-Softmax的效果
与L-Softmax的区别
A-Softmax的总结及与L-Softmax的对比——SphereFace
1. A-Softmax的推导
回顾一下二分类下的Softmax后验概率,即:
式
其中

2. A-Softmax Loss的性质
性质1:A-Softmax Loss定义了一个大角度间隔的学习方法,
这个性质是相当容易理解的,如图1所示:这个间隔的角度为
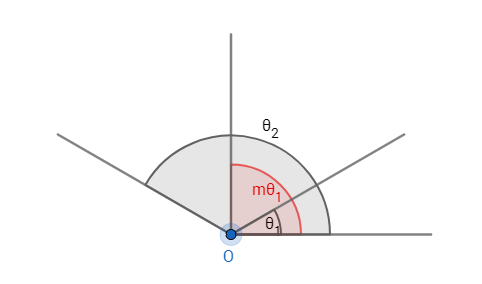
定义1:
性质2:在二分类问题中:
证明:1.对于二分类问题,设
当
无论是上述中的第一种情况还是第二种情况,类间的最小角度特征距离如图5所示情况中的

以上的分析可以总结为以下方程:
解上述不等式可以行到
2.对于
可以解得
3. A-Softmax的几何意义
个人认为A-Softmax是基于一个假设:不同的类位于一个单位超球表面的不同区域。从上面也可以知道它的几何意义是权重所代表的在单位超球表面的点,在训练的过程中,同一类的输入映射到表面上会慢慢地向中心点(这里的中心点大部分时候和权重的意义相当)聚集,而到不同类的权重(或者中心点)慢慢地分散开来。
4. 源码解读
############### A-Softmax Loss ##############
layer {
name: "fc6"
type: "MarginInnerProduct"
bottom: "fc5"
bottom: "label"
top: "fc6"
top: "lambda"
param {
lr_mult: 1
decay_mult: 1
}
margin_inner_product_param {
num_output: 10572
type: QUADRUPLE
weight_filler {
type: "xavier"
}
base: 1000
gamma: 0.12
power: 1
lambda_min: 5
iteration: 0
}
}
layer {
name: "softmax_loss"
type: "SoftmaxWithLoss"
bottom: "fc6"
bottom: "label"
top: "softmax_loss"
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
template
<
typename
Dtype>
void
MarginInnerProductLayer<Dtype>::Forward_cpu(
const
vector<Blob<Dtype>*>& bottom,
const
vector<Blob<Dtype>*>& top)
{
iter_ += (Dtype)1.;
Dtype base_ =
this
->layer_param_.margin_inner_product_param().base();
Dtype gamma_ =
this
->layer_param_.margin_inner_product_param().gamma();
Dtype power_ =
this
->layer_param_.margin_inner_product_param().power();
Dtype lambda_min_ =
this
->layer_param_.margin_inner_product_param().lambda_min();
lambda_ = base_ *
pow
(((Dtype)1. + gamma_ * iter_), -power_);
lambda_ = std::max(lambda_, lambda_min_);
top[1]->mutable_cpu_data()[0] = lambda_;
/************************* normalize weight *************************/
Dtype* norm_weight =
this
->blobs_[0]->mutable_cpu_data();
Dtype temp_norm = (Dtype)0.;
for
(
int
i = 0; i < N_; i++) {
temp_norm = caffe_cpu_dot(K_, norm_weight + i * K_, norm_weight + i * K_);
temp_norm = (Dtype)1./
sqrt
(temp_norm);
caffe_scal(K_, temp_norm, norm_weight + i * K_);
}
/************************* common variables *************************/
// x_norm_ = |x|
const
Dtype* bottom_data = bottom[0]->cpu_data();
const
Dtype* weight =
this
->blobs_[0]->cpu_data();
Dtype* mutable_x_norm_data = x_norm_.mutable_cpu_data();
for
(
int
i = 0; i < M_; i++) {
mutable_x_norm_data[i] =
sqrt
(caffe_cpu_dot(K_, bottom_data + i * K_, bottom_data + i * K_));
}
Dtype* mutable_cos_theta_data = cos_theta_.mutable_cpu_data();
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, (Dtype)1.,
bottom_data, weight, (Dtype)0., mutable_cos_theta_data);
for
(
int
i = 0; i < M_; i++) {
caffe_scal(N_, (Dtype)1./mutable_x_norm_data[i], mutable_cos_theta_data + i * N_);
}
// sign_0 = sign(cos_theta)
caffe_cpu_sign(M_ * N_, cos_theta_.cpu_data(), sign_0_.mutable_cpu_data());
/************************* optional variables *************************/
switch
(type_) {
case
MarginInnerProductParameter_MarginType_SINGLE:
break
;
case
MarginInnerProductParameter_MarginType_DOUBLE:
// cos_theta_quadratic
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data());
break
;
case
MarginInnerProductParameter_MarginType_TRIPLE:
// cos_theta_quadratic && cos_theta_cubic
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data());
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)3., cos_theta_cubic_.mutable_cpu_data());
// sign_1 = sign(abs(cos_theta) - 0.5)
caffe_abs(M_ * N_, cos_theta_.cpu_data(), sign_1_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, -(Dtype)0.5, sign_1_.mutable_cpu_data());
caffe_cpu_sign(M_ * N_, sign_1_.cpu_data(), sign_1_.mutable_cpu_data());
// sign_2 = sign_0 * (1 + sign_1) - 2
caffe_copy(M_ * N_, sign_1_.cpu_data(), sign_2_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, (Dtype)1., sign_2_.mutable_cpu_data());
caffe_mul(M_ * N_, sign_0_.cpu_data(), sign_2_.cpu_data(), sign_2_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, - (Dtype)2., sign_2_.mutable_cpu_data());
break
;
case
MarginInnerProductParameter_MarginType_QUADRUPLE:
// cos_theta_quadratic && cos_theta_cubic && cos_theta_quartic
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data());
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)3., cos_theta_cubic_.mutable_cpu_data());
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)4., cos_theta_quartic_.mutable_cpu_data());
// sign_3 = sign_0 * sign(2 * cos_theta_quadratic_ - 1)
caffe_copy(M_ * N_, cos_theta_quadratic_.cpu_data(), sign_3_.mutable_cpu_data());
caffe_scal(M_ * N_, (Dtype)2., sign_3_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, (Dtype)-1., sign_3_.mutable_cpu_data());
caffe_cpu_sign(M_ * N_, sign_3_.cpu_data(), sign_3_.mutable_cpu_data());
caffe_mul(M_ * N_, sign_0_.cpu_data(), sign_3_.cpu_data(), sign_3_.mutable_cpu_data());
// sign_4 = 2 * sign_0 + sign_3 - 3
caffe_copy(M_ * N_, sign_0_.cpu_data(), sign_4_.mutable_cpu_data());
caffe_scal(M_ * N_, (Dtype)2., sign_4_.mutable_cpu_data());
caffe_add(M_ * N_, sign_4_.cpu_data(), sign_3_.cpu_data(), sign_4_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, - (Dtype)3., sign_4_.mutable_cpu_data());
break
;
default
:
LOG(FATAL) <<
"Unknown margin type."
;
}
|
对于后面传播,求推比较麻烦,而且在作者的源码中训练用了不少的trick,并不能通过梯度测试,我写出推导过程,方便大家在看代码的时候可以知道作用用了哪些trick,作者对这些trick的解释是有助于模型的稳定收敛,并没有给出原理上的解释。
当
在这里我仅于
要注意的是上述的
Caffe代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
|
template
<
typename
Dtype>
void
MarginInnerProductLayer<Dtype>::Backward_cpu(
const
vector<Blob<Dtype>*>& top,
const
vector<
bool
>& propagate_down,
const
vector<Blob<Dtype>*>& bottom) {
const
Dtype* top_diff = top[0]->cpu_diff();
const
Dtype* bottom_data = bottom[0]->cpu_data();
const
Dtype* label = bottom[1]->cpu_data();
const
Dtype* weight =
this
->blobs_[0]->cpu_data();
// Gradient with respect to weight
if
(
this
->param_propagate_down_[0]) {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, N_, K_, M_, (Dtype)1.,
top_diff, bottom_data, (Dtype)1.,
this
->blobs_[0]->mutable_cpu_diff());
}
// Gradient with respect to bottom data
if
(propagate_down[0]) {
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
const
Dtype* x_norm_data = x_norm_.cpu_data();
caffe_set(M_ * K_, Dtype(0), bottom_diff);
switch
(type_) {
case
MarginInnerProductParameter_MarginType_SINGLE: {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, (Dtype)1.,
top_diff,
this
->blobs_[0]->cpu_data(), (Dtype)0.,
bottom[0]->mutable_cpu_diff());
break
;
}
case
MarginInnerProductParameter_MarginType_DOUBLE: {
const
Dtype* sign_0_data = sign_0_.cpu_data();
const
Dtype* cos_theta_data = cos_theta_.cpu_data();
const
Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data();
for
(
int
i = 0; i < M_; i++) {
const
int
label_value =
static_cast
<
int
>(label[i]);
for
(
int
j = 0; j < N_; j++) {
if
(label_value != j) {
// 1 / (1 + lambda) * w
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j],
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
}
else
{
// 4 * sign_0 * cos_theta * w
Dtype coeff_w = (Dtype)4. * sign_0_data[i * N_ + j] * cos_theta_data[i * N_ + j];
// 1 / (-|x|) * (2 * sign_0 * cos_theta_quadratic + 1) * x
Dtype coeff_x = (Dtype)1. / (-x_norm_data[i]) * ((Dtype)2. *
sign_0_data[i * N_ + j] * cos_theta_quadratic_data[i * N_ + j] + (Dtype)1.);
Dtype coeff_norm =
sqrt
(coeff_w * coeff_w + coeff_x * coeff_x);
coeff_w = coeff_w / coeff_norm;
coeff_x = coeff_x / coeff_norm;
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_w,
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_x,
bottom_data + i * K_, (Dtype)1., bottom_diff + i * K_);
}
}
}
// + lambda/(1 + lambda) * w
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, lambda_/((Dtype)1. + lambda_),
top_diff,
this
->blobs_[0]->cpu_data(), (Dtype)1.,
bottom[0]->mutable_cpu_diff());
break
;
}
case
MarginInnerProductParameter_MarginType_TRIPLE: {
const
Dtype* sign_1_data = sign_1_.cpu_data();
const
Dtype* sign_2_data = sign_2_.cpu_data();
const
Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data();
const
Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data();
for
(
int
i = 0; i < M_; i++) {
const
int
label_value =
static_cast
<
int
>(label[i]);
for
(
int
j = 0; j < N_; j++) {
if
(label_value != j) {
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j],
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
}
else
{
// sign_1 * (12 * cos_theta_quadratic - 3) * w
Dtype coeff_w = sign_1_data[i * N_ + j] * ((Dtype)12. *
cos_theta_quadratic_data[i * N_ + j] - (Dtype)3.);
// 1 / (-|x|) * (8 * sign_1 * cos_theta_cubic - sign_2) * x
Dtype coeff_x = (Dtype)1. / (-x_norm_data[i]) * ((Dtype)8. * sign_1_data[i * N_ + j] *
cos_theta_cubic_data[i * N_ + j] - sign_2_data[i * N_ +j]);
Dtype coeff_norm =
sqrt
(coeff_w * coeff_w + coeff_x * coeff_x);
coeff_w = coeff_w / coeff_norm;
coeff_x = coeff_x / coeff_norm;
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_w,
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_x,
bottom_data + i * K_, (Dtype)1., bottom_diff + i * K_);
}
}
}
// + lambda/(1 + lambda) * w
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, lambda_/((Dtype)1. + lambda_),
top_diff,
this
->blobs_[0]->cpu_data(), (Dtype)1.,
bottom[0]->mutable_cpu_diff());
break
;
}
case
MarginInnerProductParameter_MarginType_QUADRUPLE: {
const
Dtype* sign_3_data = sign_3_.cpu_data();
const
Dtype* sign_4_data = sign_4_.cpu_data();
const
Dtype* cos_theta_data = cos_theta_.cpu_data();
const
Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data();
const
Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data();
const
Dtype* cos_theta_quartic_data = cos_theta_quartic_.cpu_data();
for
(
int
i = 0; i < M_; i++) {
const
int
label_value =
static_cast
<
int
>(label[i]);
for
(
int
j = 0; j < N_; j++) {
if
(label_value != j) {
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j],
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
}
else
{
// 1 / (1 + lambda) * sign_3 * (32 * cos_theta_cubic - 16 * cos_theta) * w
Dtype coeff_w = sign_3_data[i * N_ + j] * ((Dtype)32. * cos_theta_cubic_data[i * N_ + j] -
(Dtype)16. * cos_theta_data[i * N_ + j]);
// 1 / (-|x|) * (sign_3 * (24 * cos_theta_quartic - 8 * cos_theta_quadratic - 1) +
// sign_4) * x
Dtype coeff_x = (Dtype)1. / (-x_norm_data[i]) * (sign_3_data[i * N_ + j] *
((Dtype)24. * cos_theta_quartic_data[i * N_ + j] -
(Dtype)8. * cos_theta_quadratic_data[i * N_ + j] - (Dtype)1.) -
sign_4_data[i * N_ + j]);
Dtype coeff_norm =
sqrt
(coeff_w * coeff_w + coeff_x * coeff_x);
coeff_w = coeff_w / coeff_norm;
coeff_x = coeff_x / coeff_norm;
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_w,
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_x,
bottom_data + i * K_, (Dtype)1., bottom_diff + i * K_);
}
}
}
// + lambda/(1 + lambda) * w
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, lambda_/((Dtype)1. + lambda_),
top_diff,
this
->blobs_[0]->cpu_data(), (Dtype)1.,
bottom[0]->mutable_cpu_diff());
break
;
}
default
: {
LOG(FATAL) <<
"Unknown margin type."
;
}
}
}
}
|
A-Softmax的效果
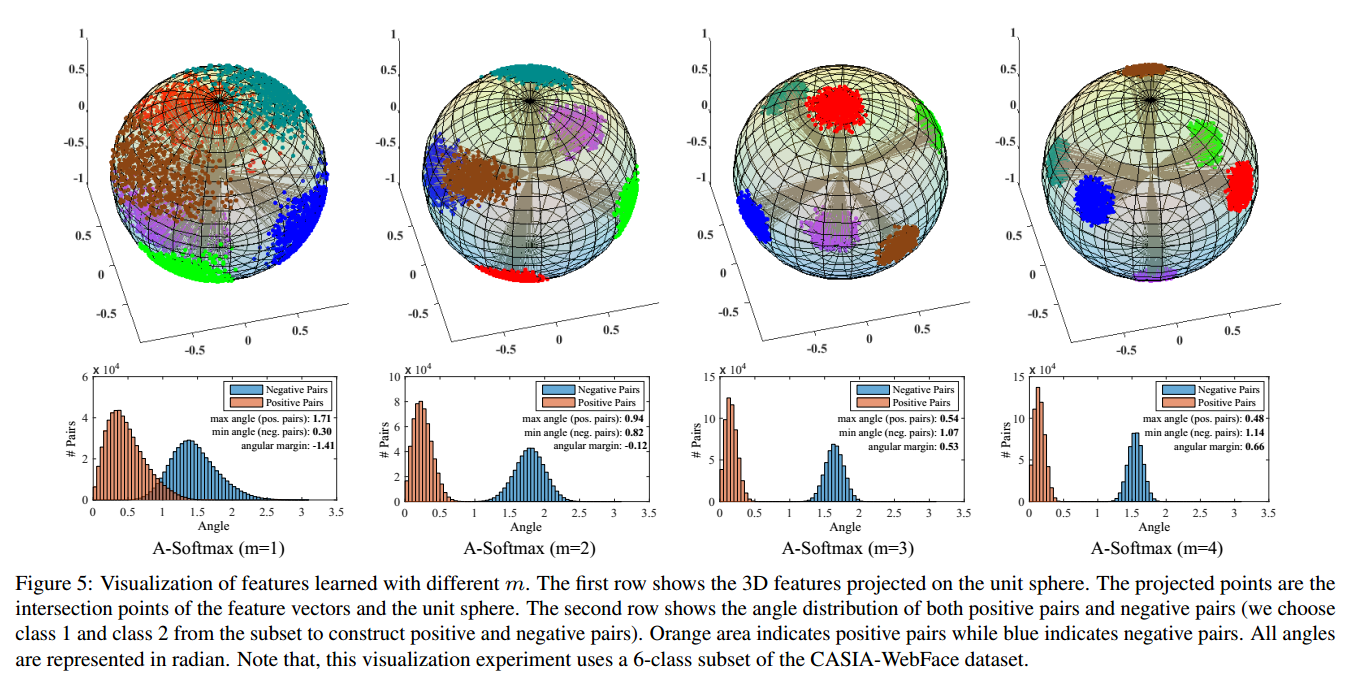
在训练模型(training)用的是A-Softmax函数,但在判别分类结果(vilidation)用的是余弦相似原理,如下图7所示:
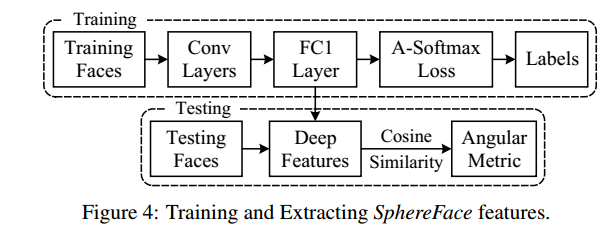
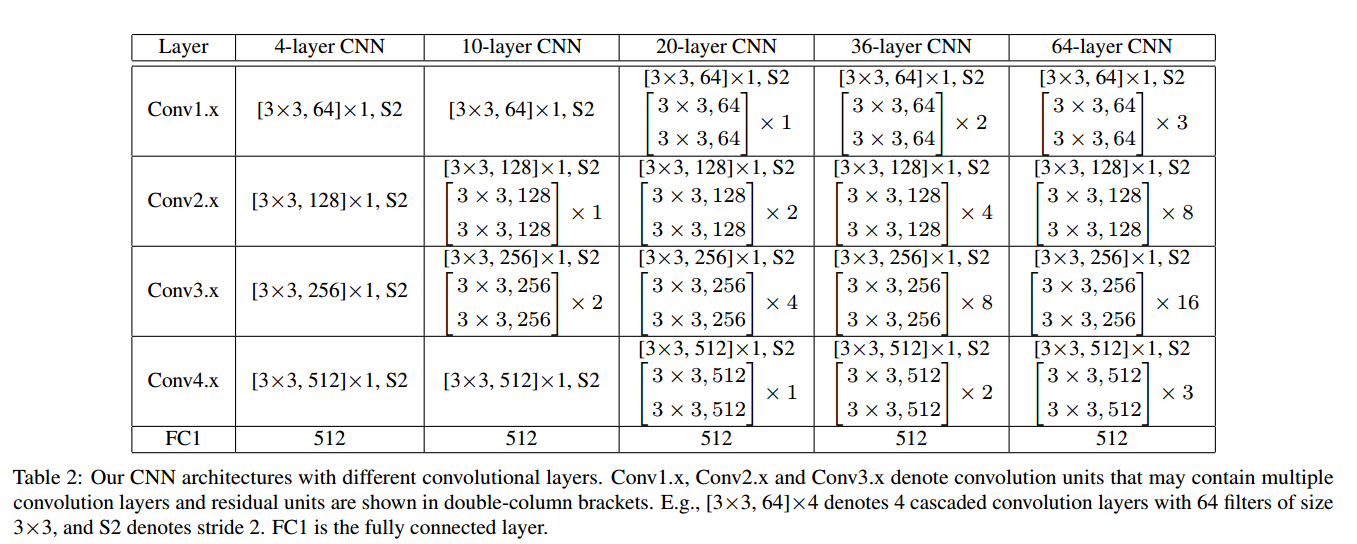
所用的模型如图8所示:
效果如下所示(详细的对比,请看原文):
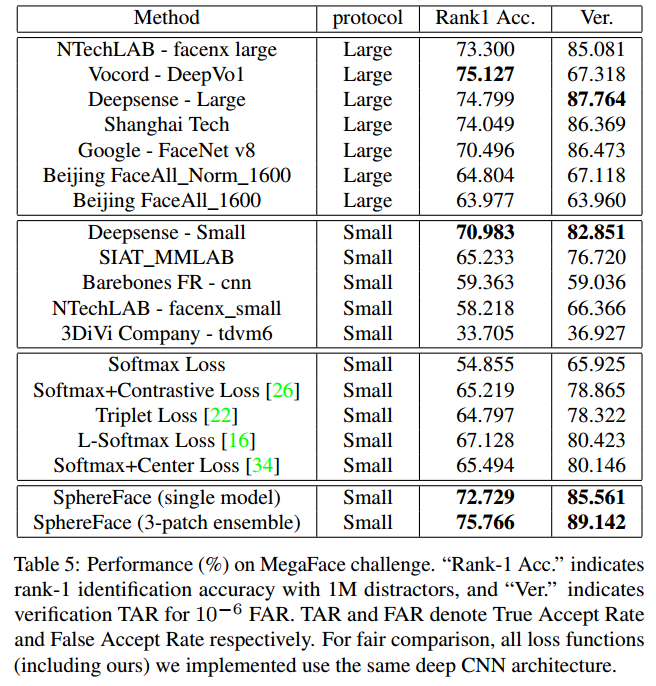
A-Softmax在较小的数据集合上有着良好的效果且理论具有不错的可解释性,它的缺点也明显就是计算量相对比较大,也许这就是作者在论文中没有测试大数据集的原因。
与L-Softmax的区别
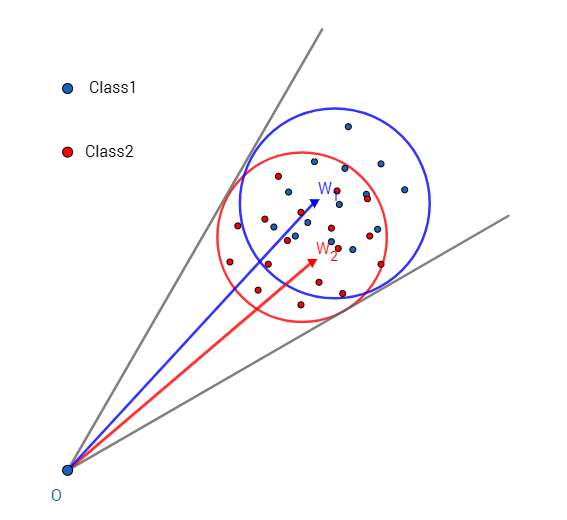
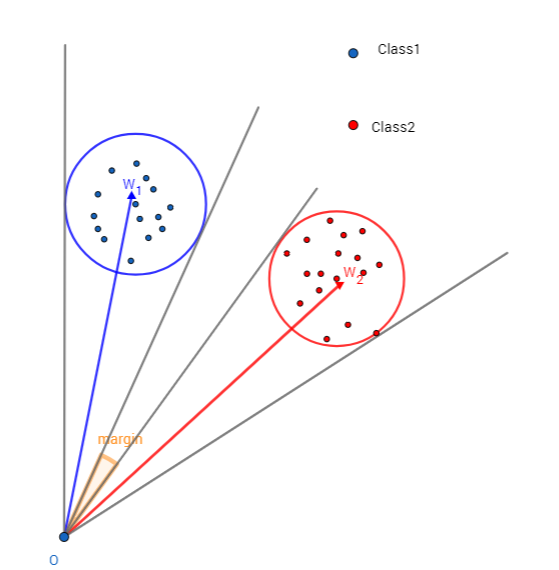
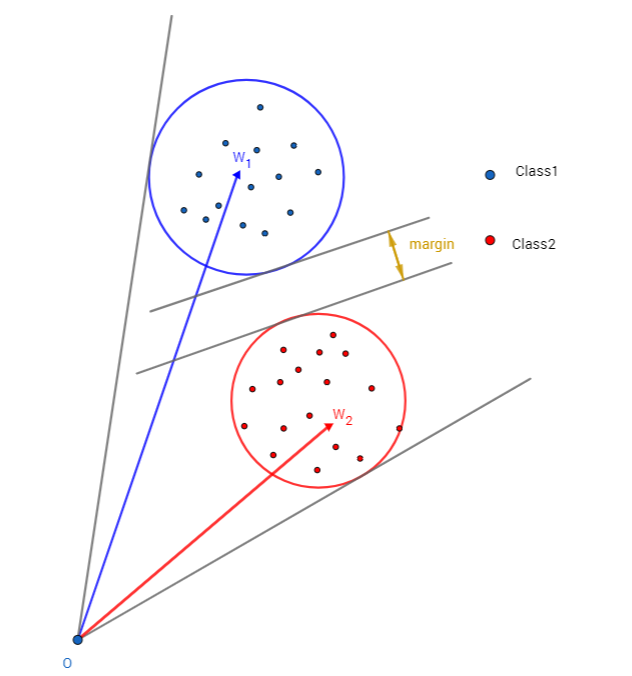
A-Softmax与L-Softmax的最大区别在于A-Softmax的权重归一化了,而L-Softmax则没的。A-Softmax权重的归一化导致特征上的点映射到单位超球面上,而L-Softmax则不没有这个限制,这个特性使得两者在几何的解释上是不一样的。如图10所示,如果在训练时两个类别的特征输入在同一个区域时,如下图10所示。A-Softmax只能从角度上分度这两个类别,也就是说它仅从方向上区分类,分类的结果如图11所示;而L-Softmax,不仅可以从角度上区别两个类,还能从权重的模(长度)上区别这两个类,分类的结果如图12所示。在数据集合大小固定的条件下,L-Softmax能有两个方法分类,训练可能没有使得它在角度与长度方向都分离,导致它的精确可能不如A-Softmax。
【防止爬虫转载而导致的格式问题——链接】:http://www.cnblogs.com/heguanyou/p/7503025.html