一、发送get请求
- response = requests.get(url,[data=data,parment=parment,header=heder])
import requests
response = requests.get('http://www.baidu.com/') # 请求百度首页
print(response.status_code) #返回整型数据
- 注
①header、parment和data的类型为字典型
②header中传递浏览器的请求头,主要让服务器认为此请求是浏览器客户端发送的,而非程序实现的而发送
③请求返回的response是一个对象
二、响应response常用的方法
- response.text
以字符串方式返回响应的内容 - respones.content
以字节bytes方式返回响应的内容 - response.status_code
返回响应的状态码 - response.request.headers
返回请求的头部 - response.headers
返回响应的头部 - response.request.url
返回请求的url - response.url
返回响应的url - response.cookies
返回响应的cookie值
reqeusts.util.dict_from_cookiejar(response.cookies)
返回响应的cookie值的字典形式
import requests
response = requests.get('http://www.baidu.com') # 请求百度首页
print(response.content.decode()) #解码响应数据并打印
print(response.status_code) # 打印响应的状态码
print(response.request.headers) #打印请求的头部
print(response.headers) #打印响应的头部
print(response.request.url) #打印请求的url
print(response.url) #打印响应的url
print(response.cookies) # 打印响应的cookie值
print( requests.utils.dict_from_cookiejar(response.cookies)) #打印字典形式的cookie值
运行结果
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
200
{'User-Agent': 'python-requests/2.21.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Wed, 25 Mar 2020 09:43:52 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:36 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
http://www.baidu.com/
http://www.baidu.com/
三、发送带有头部和参数的get请求
import requests
params = {"wd":"python"} # 参数
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
} # 头部信息
response = requests.get('http://www.baidu.com/',headers=headers,params=params) # 请求百度首页
print(response.status_code) #打印响应的状态码
运行结果
200
注
①请求头中的User-Agent,表示发送请求的浏览器名称
②服务器一般会先判断User-Agent是否为浏览器类型,如果头部信息User-Agent还是不能够请求成功,可以尝试人为发送更多的头部信息
import requests
class TieBa():
def __init__(self,tieba_name):
'''初始化获取贴吧名和贴吧url'''
self.tieba_name = tieba_name # 获取需要查看的贴吧名
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"}
self.url = 'https://tieba.baidu.com/f?kw={}'.format(self.tieba_name) # 拼凑url
def create_url_list(self):
'''创建贴吧中每一页的url'''
return [self.url+'pn={}'.format(i*50) for i in range(1000)]
def get_response(self,url):
'''获取每一页对应的响应'''
response = requests.get(url,self.headers)
return response.content.decode()
def save_data(self,data,page_num):
'''保存获取到的响应数据'''
data_html = '{}第{}页.html'.format(self.tieba_name,page_num)
with open(data_html,'w',encoding='utf-8') as f:
f.write(data)
def run(self):
'''完成对整体的控制'''
# 1.获取url列表
url_list = self.create_url_list()
# 2.遍历url列表,获取对应的响应
for url in self.create_url_list():
response = self.get_response(url)
# 3.保存获取的数据
self.save_data(response,url_list.index(url))
if __name__ == '__main__':
tie_ba = TieBa('李毅')
tie_ba.run()
四、发送post请求
- 场景
登录注册( POST 比 GET 更安全)
需要传输大文本内容的时候( POST 请求对数据长度没有要求) - 用法
response = requests.post("url,[ data = data,headers=headers]) - 注
data和headers均为字典型
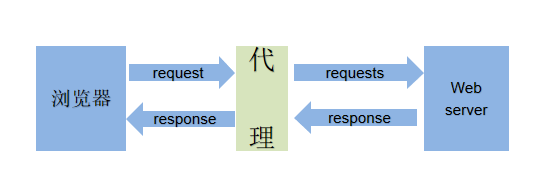
五、使用代理
- 作用
让服务器以为不是同一个客户端在请求
防止我们的真实地址被泄露,防止被追究
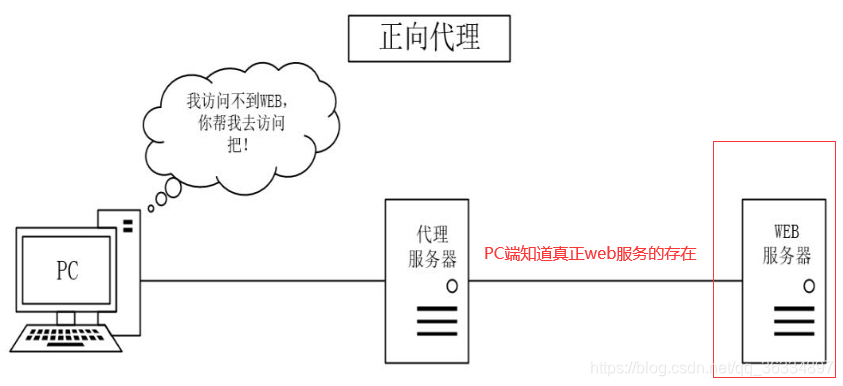
- 正向代理
- 说明
①PC客户端无法访问web服务器(例如有些国外服务器,在国内无法访问),但是代理服务器可以访问
②代理服务器帮助PC请求页面并缓存到本地,并将页面返回给PC
注
PC只需要浏览器设置代理服务器的ip和端口即可,且PC端知道WEB服务器的真实存在 - 反向代理
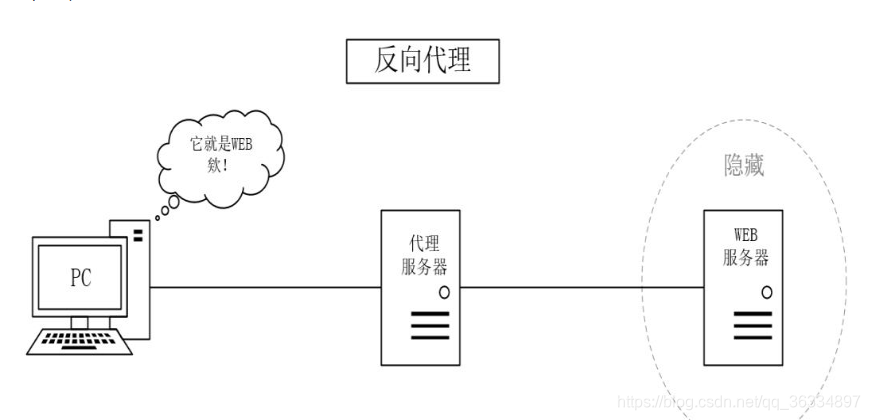
- 说明
①PC访问WEB服务器,并不知道访问的是代理服务器,PC端以为代理服务器就是WEB服务器
②代理服务器将WEB服务器页面缓存到本地,当PC访问时直接返回给PC页面
注
PC浏览器不需要做任何设置,PC浏览器访问代理服务器就相当于访问WEB服务器 - 应用
requests.get(url, proxies = proxies)
proxies = {
“http”: “http://12.34.56.79:9527”,
“https”: “https://12.34.56.79:9527”,
} 设置代理服务器的ip和端口
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"}
proxies = {"http":"http://163.177.152.23:80"}
response = requests.get('http://www.baidu.com',headers=headers,proxies=proxies)
print(response.status_code)
六、cookie和session区别
-
cookie
当网页要发http请求时,浏览器会先检查是否有相应的cookie,有则自动添加在request header中的cookie字段中,cookie中存储的值一般时用户身份认证信息的值,服务端也可以通过响应头中的set-cookie来设置浏览器中缓存的cookie值 -
session
session是存储在服务器中的数据(简单理解) -
区别
①cookie数据存放在客户的浏览器上,session数据放在服务器上。
②cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗。
③session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能。
④单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。 -
爬虫中使用cookie的好处
能够请求到登录之后的页面,比如某些网站的个人主页等,需要先登录才能查看,当再次重新输入个人主页的url后,会重新跳转到登录页面 -
爬虫中使用cookie的坏处
①一套cookie和session往往和一个用户对应
②请求太快,请求次数太多,容易被服务器识别为爬虫
建议
不需要cookie的时候尽量不去使用cookie,但是为了获取登录之后的页面,我们必须发送带有cookies的请求
七、使用cookie -
实例化一个session对象
session = requests.session() -
让session发送get或者post请求
session.post(url,data=post_data,headers=headers)
response = session.get(url,headers=headers)
注
使用post发送请求后,服务器会返回cookie值,浏览器则会将cookie值保存到本地,当下次再get发送请求是,只需要个人主页url和请求头User-Agent就可完成对登录操作的模拟
八、模拟登录的三种操作
- 使用session对象(如七)
- 在requests.get请求中加入cookie参数
requests.get(url,headers=headers,cookies=cookies)
此时,cookies中的键是cookie中的name,值是cookie中的value - 将cookie参数添加到header中,再发送请求requests.get(url,headers=headers,cookies=cookies)发送
此时,cookies中的键是‘cookies’,值是请求头中的cookies的值
九、 SSL证书验证设置
- response = requests.get(url, verify=False) # 不检验安全证书
十、超时设置
- response = requests.get(‘http://www.baidu.com’,timeout=n)
强制设置请求页面的时间为n秒,如果超出n秒,程序将会报错
import requests
response = requests.get('http://www.baidu.com',timeout=10)
print(response.status_code)
十一、页面刷新(重新发送请求)
- @retry(stop_max_attempt_number=3)
def function()
from retrying import retry
@retry(stop_max_attempt_number=3)
def parse_url():
print('*'*10)
response = requests.get('http://www.baidu.com',timeout=10)
print(response.status_code)
parse_url()
运行结果
**********
200
- 说明
stop_max_attempt_number=3,表示最多发送三次请求,当第一次请求不成功是,发送第二次请求,当第二次请求不成功时,发送第三次请求;如果第一次请求成功,则不会再发送请求
十二、URL编/解码 - url编码
requests.utils.quote(url) - url解码
requests.utils.unquote(url)
import requests
url = 'http://www.baidu.com'
url_encode = requests.utils.quote(url) # url编码
url_decode = requests.utils.unquote(url_encode) #url解码
print(url_encode)
print(url_decode)
运行结果
:
1
import requests
2
url = 'http://www.baidu.com'
3
url_encode = requests.utils.quote(url) # url编码
4
url_decode = requests.utils.unquote(url_encode) #url解码
5
print(url_encode)
6
print(url_decode)
http%3A//www.baidu.com
http://www.baidu.com
- 注:也可使用在线url编/解码工具
