+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
张贺,多年互联网行业工作经验,担任过网络工程师、系统集成工程师、LINUX系统运维工程师
个人网站:www.zhanghehe.cn
笔者微信:zhanghe15069028807,现居济南历下区
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
性能与单机监控
影响系统性能的因素
1.硬件相关
(1)CPU:
cpu的个数、核数、频率
//查看cpu的个数
[root@kk ~]# cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
4
//查看每个cpu的核数
cat /proc/cpuinfo | grep "cpu cores" | uniq
cpu cores : 1
比较消耗cpu的业务有动态站点、mail等
(2)内存:
物理内存与swap的取舍
尽量选项64位系统
消耗内存的应用:内存数据库(mong和redis)
(3)磁盘:
是否是专业存储服务器
存储方式:SAN、NFS
reid的选项
硬盘类型的选项
对硬盘要求比较高的应用:数据库
(4)网络:
交换机(吞吐量|背板带宽
网卡是否绑定
带宽大小
2.系统相关
- 分区是否合理
- raid是否合理
- swap大小是否合理
- 打开的最大文件数、最大用户数
- 文件系统选择是否合理
ext2:没有日志记录功能
ext3:有日志记录功能,但限制目录个数为32000个目录。
ext4:无限子目录,快速fsck修复
xfs:高性能文件系统
关于文件系统的选项,读操作频率,同时小文件众多的应用,首选ext4文件系统,接下来依次是xfs,ext3
写操作频繁的应用,首先xfs,接下来是ext4和ext3。
对性能要求不高,对数据安全性要求不高,用ext3即可。
3.应用相关
百分之七十问题的性能问题是由程序导致的,此类问题需要开发介入查看代码,但作为运维人员要给出程序问题的证据。
性能评估工具
1.综合性能评估(vmstat)
//vmstat是一项综合性能的性能评估工具,如下所示,两秒显示一次,显示三次
[root@kk ~]# vmstat 2 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1547536 2108 361868 0 0 8 4 14 22 0 0 100 0 0
0 0 0 1547544 2108 361868 0 0 0 0 46 54 0 0 100 0 0
0 0 0 1547544 2108 361868 0 0 0 0 33 43 0 0 100 0 0
procs
-
r列表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的核数,说明CPU不足,需要增加CPU..
-
b列表示在等待资源的进程数,比如正在等待1/0、或者内存交换等。
memory
-
swpd列表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si、 so的值长期为0,这种情况下一般不用担心,不会影响系統性能。.
-
free列表示当前空闲的物理内存数量(以k为单位)
-
buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。
-
cache列表示page cached的内存数里,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IObi比较小,说明文件系统效率比较好..
swap
- si烈表示由磁盘调入内存
- so列表示由内存调入磁盘
一般情况下, si,so的值都为d,如果si、so的值长期不为0,则表示系统内存不足。
IO项显示磁盘读写状况:
-
Bi列表示从块设备读入数据的总量(即读磁盘) (每秒kb)..
-
B0列表示写入到块设备的数据总里(即写磁盘) (每秒k)
这里我们设置的bi+bo.参考值为1000,如果超过1000,而且wa值较大,则表示系统磁盘IO有问题,应该考虑提高磁盘的读写性能。
system显示采集间隔内发生的中断数:
-
in列表示在某一时间间隔中观测到的每秒设备中断数。
-
cs列表示每秒产生的上下文切换次数.
上面这2个值越大,会看到由内核消耗的CPU时间会越多。
CPU项显示了CPU的使用状态,此列是我们关注的重点
-
us列显示了用户进程冲耗的CPU时间百分比.us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虚优化程序或算法..
-
sy列显示了内核进程消耗的CPU时间百分比.Sy的值较高时,说明内核消耗的CPU资源很多。如果被人注入了木马,当成了肉鸡之类的,这里的值可能就会比较大。
根据经验, us+sy的参考值为80%,如果us+sy大于80%说明可能存在CPU资源不足…
-
id列显示了CPU处在空闲状态的时间百分比.
-
wa列显示了IO等待所占用的CPU时间百分比.wa值越高,说明10等待越严重,根据经验, wa的参考值为20%,如果wa超过20%,说明10等待严重,引起IO等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者磁盘控制器的带宽瓶颈造成的(主要是块操作).
综上所述,在对CPU的评估中,需要重点注意的是procs项r列的值和CPU项中Us、sy和id列的值。
2.IO性能评估(iostat)
iostat的主要功能是对系统的磁盘IO操作进行监视。
- -c 表示对显示cpu的使用情况
- -d 显示磁盘的使用情况
- -k/-m:输出结果以kB/mB为单位,而不是以扇区数为单位
- -x:输出更详细的io设备统计信息
[root@kk ~]# yum -y install sysstat
[root@kk ~]#iostat -c 3 5 #3秒显示一次,一共显示五次
如上所示,iostat -c 与vmstat命令很是相似,avg-cpu表示总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值。重点关注iowait值,表示cpu用于等待io请求的完成时间。
如上所示.
Device: 以sdX形式显示的设备名称
tps: 每秒进程下发的IO读、写请求数量
KB_read/s: 每秒从驱动器读入的数据量,单位为K。
KB_wrtn/s: 每秒从驱动器写入的数据量,单位为K。
KB_read: 读入数据总量,单位为K。
KB_wrtn: 写入数据总量,单位为K。
dm-0和dm-1其实是逻辑卷,只不过在此以主次设备好的方式进行显示。
// 每隔1S输出磁盘IO的详细详细,总共采样2次
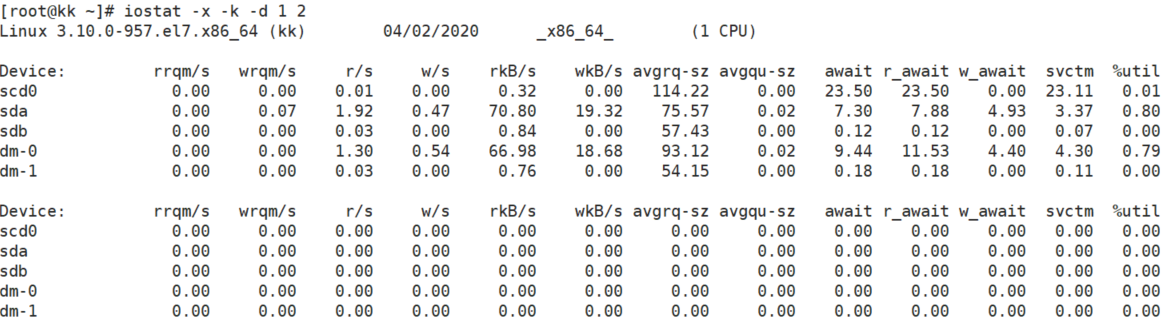
以上各列的含义如下:
rrqm/s: 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并
wrqm/s: 每秒对该设备的写请求被合并次数
r/s: 每秒完成的读次数
w/s: 每秒完成的写次数
rkB/s: 每秒读数据量(kB为单位)
wkB/s: 每秒写数据量(kB为单位)
avgrq-sz:平均每次IO操作的数据量(扇区数为单位)
avgqu-sz: 平均等待处理的IO请求队列长度
await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)
svctm: 平均每次IO请求的处理时间(毫秒为单位)
%util: 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率
重点关注参数
1、iowait% 表示CPU等待IO时间占整个CPU周期的百分比,如果iowait值超过50%,或者明显大于%system、%user以及%idle,表示IO可能存在问题。
2、avgqu-sz 表示磁盘IO队列长度,即IO等待个数。
3、await 表示每次IO请求等待时间,包括等待时间和处理时间
4、svctm 表示每次IO请求处理的时间
5、%util 表示磁盘忙碌情况,一般该值超过80%表示该磁盘可能处于繁忙状态。
3.综合性能统计top
//指定几秒刷新一次,默认5秒
top –d 5
//使用-d此选项可以仅查看某一个进程的状态
top –p <pid号码>
显示进程的动态信息,ps是显示的是进程的静态信息,直接使用ps命令进程按照占用cpu的资源的多少排序,注意,下图当中的信息实际上是在不断的变化,如下:
top - 20:05:19 up 1:32, 2 users, load average: 0.09, 0.04, 0.05
Tasks: 159 total, 1 running, 158 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.1 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3324936 total, 2368636 free, 365448 used, 590852 buff/cache
KiB Swap: 3538940 total, 3538940 free, 0 used. 2657500 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20058 root 20 0 162012 2300 1592 R 0.7 0.1 0:00.03 top
8353 root 20 0 320028 6744 5268 S 0.3 0.2 0:12.62 vmtoolsd
8732 root 20 0 573828 17228 6060 S 0.3 0.5 0:01.74 tuned
当使用top命令之后默认是使用cpu的占用的多少进行排序(%CPU)使用P表示,如果在这个界面当中按大写的M就会按照占用内存的多少来排序;也可以使用T累积占用cpu时间的多少进行排序(也就是TIME+)。
第一行02:17:41显示的是当前的系统时间,up 11:05是系统运行了多少时间,5user当前系统登录多少用户,load average平均负载 cpu队列当中等待运行的任务的个数(也可以是排列的长度),并不是百分比,过去的一分钟,五分钟的平均长度(这是队列当中的进程的多少,越小越好,越小代表cpu的负载越低),十五分钟的平均负载状态。如果在top命令当中没想显示此行的内容使用l(小写的L)就可折叠,再次使用l又会显示。这个地方显示的信息使用uptime也可以显示,如下:
[root@China ~]# uptime
02:29:54 up 11:17, 5 users, load average: 0.04, 0.03, 0.05
第二行,tasks所有的进程的数量,后面就是处于运行状态的有多少个,睡眠状态的有多少个,停止状态的有多少个,僵死状态的有多少个。
第三行是cpu的负载情况:从下图我们看出当前有两个cpu,按数字1可以把所有cpu的负载信息都展开或者折叠显示,默认是是cpus,这表示是平均的负载情况,如下图:
top - 20:09:38 up 1:36, 2 users, load average: 0.00, 0.02, 0.05
Tasks: 158 total, 2 running, 156 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.6 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3324936 total, 2368140 free, 365928 used, 590868 buff/cache
us指用户空间占据的cpu百分比,sy内核空间的占用cpu的百分比,ni是nice占用cpu的空间,id空间比例,wa等待io完成占据的时间,如果这个时间过大的话代表磁盘太慢了已经成为了系统瓶颈了,hi(硬件中断)处理硬中断占据的百分比,si(软中断)是处理软中断占据的百分比,st cpu被偷走的时间的比例,如果系统中有运行虚拟化cpu的时间可能被偷走。
按t可以把task和cpu的负载信息都折叠或者是展开显示,如下图:
top - 20:11:08 up 1:38, 2 users, load average: 0.00, 0.01, 0.05
KiB Mem : 3324936 total, 2368124 free, 365924 used, 590888 buff/cache
KiB Swap: 3538940 total, 3538940 free, 0 used. 2656996 avail Mem
第三行,物理内存的总大小,已经使用的空间,空闲的空间,缓冲区的空间,与free -m的显示结果是差不多的 .如下所示:
[root@zabbix ~]# free -h
total used free shared buff/cache available
Mem: 3.2G 356M 2.3G 11M 577M 2.5G
Swap: 3.4G 0B 3.4G
最后一行的解释如下:
PR优先级
ni值
VIRT虚拟内存级
RES常驻内存级
SHR共享内存大小
S当前的简要状态
TIME+占据cpu的时长
4. uptime
[root@kk mapper]# uptime
09:16:09 up 25 min, 2 users, load average: 0.00, 0.01, 0.05
uptime是监控系统性能最常用的一个工具,主要用来统计系统当前的运行状况,输出的值依次为:
当前时间、系统从上次开机到现在的时长、目前登录的用户数量、系统在一分钟、五分种、十五分钟的平均负载,超过cpu的数目就表示负载过高。
5free

centos6的free -m提供了两个角度的输出,其中第一行是从系统的角度,第二行是从程序的角度。
系统认为buffer和cache用的内存也应该算到已经用掉的内存里面,used其实已经包括buffers和cached的内容,也就是说,416当中包括195和53,所以计算剩下的内存时直接用总量(3816)减去used(416)即可,即等于3400,这就是系统剩下的内存。
应用程序认为被buffers和cache占用的内存不应该算是被占用的内存,因为当系统内存不足时会自动清理buffer和cache占用的空间,所以第二行的used当中就没有包括buffer和cache,而计算余量时直接通过总量减去166,也就是3649.
//下面是cetos7显示内存信息
[root@client ~]# free -m
total used free shared buff/cache available
Mem: 1980 106 1509 9 365 1696
Swap: 4223 0 4223
centos的计算要简单很多了,就直接放到一行当中了,并提供两个余量:free和available
free是从应用程序的角度看内存,没有算buffer和cahce,所以free=total-used-buff/cache
available是从系统的角度年内存,等于total减去used
6.sar
此两个命令主要用于监控全部或指定进程占用系统资源的情况,如cpu、内存,磁盘
- -u获取cpu状态
- -r获取内存状态
- -d获取磁盘IO状态
//获取cpu 3秒内的状态,与iostat的输出类似
[root@kk mapper]# sar -u 3
Linux 3.10.0-957.el7.x86_64 (kk) 04/02/2020 _x86_64_ (1 CPU)
09:39:32 AM CPU %user %nice %system %iowait %steal %idle
09:39:35 AM all 0.00 0.00 0.33 0.00 0.00 99.67
09:39:38 AM all 0.33 0.00 0.00 0.00 0.00 99.67
09:39:41 AM all 0.00 0.00 0.33 0.00 0.00 99.67
09:39:44 AM all 0.00 0.00 0.00 0.00 0.00 100.00
09:39:47 AM all 0.00 0.00 0.34 0.00 0.00 99.66

其中:
Kbmemfree-表示空闲物理内存大小, kbmemused-表示已使用的物理内存空间大小, %memused表示已使用内存占总内存大小的百分比, kbbuffers和kbcached分别表示Buffer Cache和Page Cache的大小, kbcommit和%commit分别表示应用程序当前使用的内存大小和使用百分比。. I
可以看出sar的输出其实与free的输出完全对应,不过sar更加人性化,不但给出了内存使用重,还给出了内存使用的百分比以及统计的平均值。从%commit项可知,此系统目前内存资源充足。
对上面每项的输出解释如下:
DEV表示磁盘设备名称。
ts表示每秒到物理磁盘的传送数,也就是每秒的1/0流量。一个传送就是一个1/0请求,多个逻辑请求可以被合并为一个物理1/0请求。
rdsec/s表示每秒从设备读取的扇区数(1扇区=512字节)
wr_sec/s表示每秒写入设备的扇区数目。
avgrg-sz表示平均每次设备1/0操作的数据大小(以扇区为单位)
avgqu-sz表示平均1/0队列长度。
await表示平均每次设备1/0操作的等待时间(以毫秒为单位)。t
svctm表示平均每次设备1/0操作的服务时间(以毫秒为单位)。
%util表示一秒中有百分之几的时间用于1/0操作
Linux中1/0请求系统与现实生活中超市购物排队系统有很多类似的地方,通过对超市购物排B系统的理解,可以很快掌握linux中1/0运行机制。比如:.
avgra-sz类似与超市排队中每人所买东西的多少。
avgqu-sz类似与超市排队中单位时间内平均排队的人数。
await类似与超市排队中每人的等待时间。
svctm类似与超市排队中收银员的收款速度。
%util类似与超市收银台前有人排队的时间比例。.对以磁盘10性能,一般有如下评判标准:
正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关, CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。
vctm类似与超市排队中收银员的收款速度。
%util类似与超市收银台前有人排队的时间比例。
对以磁盘10性能,一般有如下评判标准:
正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关, CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。
await值的大小一般取决与svctm的值和1/0队列长度以及1/0请求模式,如果svctm的值与await很接近,表示几乎没有1/0等待,磁盘性能很好,如果await的值远高于svctm的值,则表示1/0队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%utill页的值也是衡里磁盘1/0的一个重要指标,如果%util接近100%,表示磁盘产生的1/0请求太多, 1/0系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。.
7.pidstat
查看单独进程的对内存的占用百分比。
//获取内存3秒内的状态
[root@kk ~]# pidstat -r -p 1 3
Linux 3.10.0-957.el7.x86_64 (kk) 04/02/2020 _x86_64_ (1 CPU)
09:49:53 AM UID PID minflt/s majflt/s VSZ RSS %MEM Command
09:49:56 AM 0 1 0.67 0.00 125436 3876 0.19 systemd
09:49:59 AM 0 1 0.00 0.00 125436 3876 0.19 systemd
09:50:02 AM 0 1 8.03 0.00 125436 3876 0.19 systemd
-p 指定一个PID
8、网络性能分析(ping)
[root@client ~]# ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=128 time=95.8 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=128 time=77.6 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=128 time=86.5 ms
64 bytes from 8.8.8.8: icmp_seq=4 ttl=128 time=95.8 ms
64 bytes from 8.8.8.8: icmp_seq=5 ttl=128 time=94.6 ms
^C
--- 8.8.8.8 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4007ms
rtt min/avg/max/mdev = 77.606/90.101/95.857/7.147 ms
ping主要要是看其延时时间,在最后一行,最小/平均/最大超时时间,像上图我们ping的是在美国的服务器,所以延时时间都比较长,我们可以ping一下国内的网站 ,会发现延迟小多了。
[root@client ~]# ping 223.6.6.6
PING 223.6.6.6 (223.6.6.6) 56(84) bytes of data.
64 bytes from 223.6.6.6: icmp_seq=1 ttl=128 time=19.6 ms
64 bytes from 223.6.6.6: icmp_seq=2 ttl=128 time=19.6 ms
64 bytes from 223.6.6.6: icmp_seq=3 ttl=128 time=20.2 ms
64 bytes from 223.6.6.6: icmp_seq=4 ttl=128 time=20.6 ms
64 bytes from 223.6.6.6: icmp_seq=5 ttl=128 time=19.4 ms
^C
--- 223.6.6.6 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4007ms
rtt min/avg/max/mdev = 19.470/19.922/20.614/0.454 ms
9、网络性能分析(mtr)
mtr和traceroute都是用来跟踪路由的,只不过traceroute是静态的,而mtr是动态的。
yum -y install mtr traceroute
[root@client ~]# traceroute www.baidu.com
traceroute to www.baidu.com (61.135.169.125), 30 hops max, 60 byte packets
1 gateway (192.168.80.1) 0.114 ms 0.116 ms 0.066 ms
2 * * *
3 * * *

10、网络性能分析(netstat)
[root@client ~]# netstat -an
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:47075 0.0.0.0:* LISTEN
tcp 0 0 192.168.80.11:22 192.168.80.9:65168 ESTABLISHED
tcp6 0 0 :::56843 :::* LISTEN
tcp6 0 0 :::111 :::* LISTEN
tcp6 0 0 :::22 :::* LISTEN
tcp6 0 0 ::1:25 :::* LISTEN
我们可以通过脚本将其状态取出来然后发送给zabbix进行监控。
系统性能分析标准:
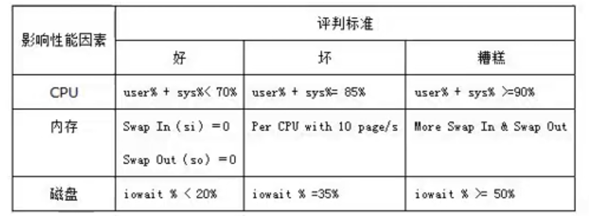
其中:
%user:表示cpu处在用户模式下的时间百分比
%sys:表示cpu处在系统模式下的时间百分比
%iowait:表示cpu等待输入输出完成时间的百分比
swap in:即si,表示虚拟内存页导入,即从swap disk交换到ram.