机器学习中的性能度量指标
对机器学习、深度学习中的学习器的泛化性能进行评估,不仅仅需要有效可行的实验方法,还需要有衡量模型泛化能力的评价标准。这就是性能度量指标。在回归任务中,我们使用均方误差来衡量性能;在分类任务中,我们使用错误率、精度、查全率、查准率、F1度量、P-R曲线、ROC-AUC等指标来衡量模型。本文重点记录了分类任务的度量指标。
我们假设在预测任务中:给定样例集合 ,其中 是 真实标记, 是 的预测结果。
回归任务:
在回归任务中,我们使用均方误差来衡量模型性能。均方误差定义如下:
分类任务:
1. 错误率和精度:
精确度和错误率是分类中最常用的两种性能度量,既适用于二分类,也适用于多任务分类。错误率就是预测错误的测试样本占整体样本的比率。精确度就是预测正确的测试样本占整体样本的比率。针对我们之前提到的样例D,分类任务的错误率为:
其中
称为指示函数,在这里取值如下:
精确度定义为:
2. 查全率、查准率
查全率,查准率在信息检索中是常用的度量指标。查全率又称召回率(recall),简单的来说就是正确的信息有多少被模型检索出来了;查准率又称为准确率,即模型检索出来的结果有多少是真正正确的。
在二分类问题中,我们将样例根据其真实类别与学习模型预测类别的组合,划分为true positive,false positive,true negative,false negative。
| 名称 | 解释 |
|---|---|
| 真正例 (true positive) TP | 真实的正例被模型识别为正例 |
| 假正例 (false positive) FP | 真正的反例被模型识别为正例 |
| 真反例 (true negative) TN | 真正的反例被识别为反例 |
| 假反例 (false negative) FN | 真正的正例被识别为反例 |
我们常使用混淆矩阵(confusion matrix)来描述上述的关系:
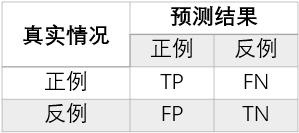
查准率(Precision)定义为:
查准率(Recall)定义为:
查准率和查全率是一对矛盾的变量。通常来说,查准率较高的时候,查全率往往偏低。查全率较高的时候,查准率往往较低。(可以这样理解,如果我们的模型把所有样本都标记为正例,那么查全率为100%,但是查准率比较低。反之,如果我们的模型十分的谨慎,则可能造成查准率特别高,但是查全率比较低的情况)
3. P-R曲线和F1度量
P-R曲线通常被用来直观地显示出学习器在样本总体上的查全率,查准率。P-R曲线的定义如下:我们根据模型对样本的预测值进行排序,排在前边的是模型认为“最可能的”正例(即置信度高的),排在最后的是模型认为“最不可能的”正例。我们设置不同的阈值,针对每一个阈值,计算模型的准确率和召回率。然后将召回率作为横轴,准确率作为纵轴,根据坐标绘制计算P-R曲线。
例如:我们将模型预测的置信度进行从高到低排序,然后分别按照0.5,0.6,0.7的阈值,来判断一个样本是否是正样本,并计算准确率和召回率
| 序号 | 真实标签 | Hyp(0.5) | Hyp(0.6) | Hyp(0.7) | … | Score |
|---|---|---|---|---|---|---|
| 1 | 正 | √ | √ | √ | 0.9998 | |
| 2 | 正 | √ | √ | √ | 0.9438 | |
| 3 | 正 | √ | √ | √ | 0.8992 | |
| 4 | 正 | √ | √ | √ | 0.8692 | |
| 5 | 正 | √ | √ | √ | 0.8095 | |
| 6 | 正 | √ | √ | √ | 0.7238 | |
| 7 | 正 | √ | √ | 0.6752 | ||
| 8 | 反 | √ | 0.5383 | |||
| 9 | 反 | 0.4102 | ||||
| 10 | 反 | 0.4053 |
计算结果:
| 阈值 | 召回率 | 准确率 | P-R曲线坐标 |
|---|---|---|---|
| 0.5 | 1 | 7/8 = 0.875 | (1,0.875) |
| 0.6 | 1 | 1 | (1,1) |
| 0.7 | 6/7 = 0.857 | 1 | (0.857,1) |
| … |
根据坐标,绘制P-R曲线。常见P-R曲线如下所示:

在P-R曲线中,若一个模型的P-R曲线被另外一个模型的曲线完全的“包住”,那么我们说后者优于前者。例如图中的A曲线完全包裹了C曲线,所以模型A性能优于模型C。但是,一旦P-R曲线发生交叉,无法判断两者的性能,例如图中的A和B。
如果A的P-R曲线和B的曲线交叉,并且我们还希望比较两个模型的性能,我们通常使用“平衡点”(Break-Even Point,简称BEP)。BEP是P-R曲线和直线 的交点,即“查全率” = “查准率”时候的取值。
更常用的综合考虑查准率和查全率的指标还有F1度量,F1度量是查全率R和查准率P的算术平均值。
4. ROC与AUC
ROC曲线(Receiver Operating Characteristic) 和之前提到的P-R曲线有相同之处。ROC曲线也是根据模型对样本的预测值进行排序,排在前边的是模型认为“最可能的”正例(即置信度高的),排在最后的是模型认为“最不可能的”正例。我们设置不同的阈值,计算不同的度量指标。在P-R曲线中,我们使用查全率作为横坐标,使用查准率作为纵坐标。在ROC中,我们使用“真正例率(TPR)“作为纵轴,使用”假正例率(FPR)“作为横轴,两个指标的定义如下:
ROC曲线的一般图像如下:

与PR曲线比较相同。当一个模型A的ROC曲线被另外一个模型B完全的“包住”地时候,后者的性能要优于前者。当两个曲线交叉地时候,我们需要引入AUC指标才能比较两个模型的性能。AUC(Area Under ROC Curve) 是什么呢?顾名思义,AUC就是ROC曲线下的面积。AUC值越大,模型的性能就越好。
在前面我们介绍了P-R曲线,这是一个综合考虑查全率和查准率的度量指标。那么为什么我们还要定义一个ROC曲线呢?考虑下边一种情况。假设我们将测试集中的负样本增加10倍以后,PR曲线和ROC曲线的变化如下所示:

可以看出,当我们的数据集中的负样本增加十倍以后,ROC曲线的变化是不大的。但是P-R曲线发生了很大的变化。
分析:对于PR曲线来说,当样本中的负样本增加10倍以后,召回率(Recall)不变的时候,模型肯定将很多的反例错误的标记为正例,这样模型的查准率就会降低很多。所以PR曲线变化很大。
对于ROC曲线来说,横轴为假正例率,纵轴为真正例率。假如样本中的负样本增加10倍以后,当纵轴的真正例率(召回率)不变的时候,模型肯定将很多的反例错误的标记为正例,即FP的数值会变大。因此,FPR的分子(FP)和分母(TN+FP,即负样本个数)都增多了,所以FPR数值变化相对查准率来看,变化不大。
PR曲线比ROC曲线更加关注正样本,而ROC则兼顾了两者。当我们希望查看模型在特定的数据集上的表现,PR曲线更能直观地反映其性能。
当我们常常选择不同的测试集的时候,P-R曲线的变化就会很大,而ROC曲线则能更加稳定地反映模型本身的好坏。ROC曲线的应用场景更加广泛。
参考资料:
[1]《机器学习》- 周志华
[2] P-R曲线及与ROC曲线区别
