论文题目:Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational Capability and Advanced Training Algorithm_ECCV2018
引用量:27
code:caffe版:https://github.com/liuzechun/Bi-Real-net
点
- 引入one layer per block形式的shortcut连接、
- 采用二次函数拟合实数激活的sign操作、
- 在更新实数权重时引入实数权重的幅度、
- 预训练模型采用clip函数替代ReLU予以训练
提高在大型数据集(ILSVRC ImageNet)上的表现
问题引出
二值化压缩方法在Imagenet这样的大数据集上会有较大的精度下降是量化的一核心问题,
文章认为,这种精度的下降主要是有两方面造成的:
- 1-bit CNN 的表达能力本身很有限,不如实数值的网络。
- 1-bit CNN 在训练过程中有导数不匹配的问题导致难以收敛到很好的精度。

XNOR-Net的bitcount(xnor)方式产生的激活值仍是实数,直接二值化会损失表达能力。怎么利用呢
网络改进
one layer per block形式的shortcut连接
首先网络结构上实现了one layer per block形式的shortcut连接,即当前1bit convolution或BN输出的实数结果与下一个1bit convolution或BN输出的实数结果直接相加,从而增加了网络的数值表示范围(Value Range),该shortcut结构如下所示:

左图是传统神经网络,连续灰度的特征图每次经过 1-bit 卷积的时候,都会被二值化。所以我们提出在特征图在被二值化之前,利用 shortcut 来传递这些实数值的特征图,这样就可以大大地保留网络中的信息量,提高网络的表达能力。

训练方法改进
文章所提出的二值网络的训练框架如下图所示,包括forward过程(实数激活的Sign操作、实数权重的Magnitude-aware Sign操作、1bit Conv、BN等)以及backward过程(二值权重、二值权重求导以及实数权重的更新等):

二值化激活值的求导
用二阶拟合 sign 的 ApproxSign 的导数来作为 sign的导数

由于sign 函数不可导,以前采用的方法是利用 clip(-1,x,1)的导数来拟合 sign 的导数,式(1)F()为clip()这种计算方式会带来所谓的导数值不匹配的问题。

但是这样造成的效果就是,网络在正向计算 loss 的时候所看到的是一个以 sign 为非线性函数的网络,
而在反向计算gradients 的时候是根据一个以 clip 为非线性函数的网络进行计算的。由于 clip 函数与 sign函数有差距,这种计算方式会带来所谓的导数值不匹配的问题。
基于这个,我们提出用二阶拟合 sign 的 ApproxSign 的导数来作为 sign的导数,从而缩小导数值的不匹配问题。这个带来了约 12% 的性能提升。
公式:
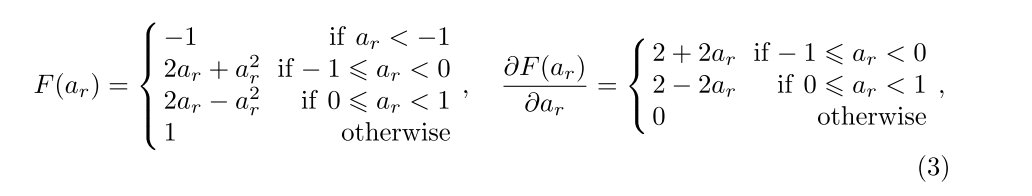
图

基于实数量级(带幅值)的导数
而在对二值化参数进行更新的时候,由于二值化参数是离散的,导数值太小往往不足以改变它的符号,因此前人采用的方法是存储实数值的参数,在更新的时候将网络根据二值参数计算出来的导数更新实数值参数,
在正向传播过程中,用sign 将实数值参数二值化,得到更新后的二值化参数。
但是这样的更新方式的实质是,将对于二值化参数求得的导数值加在存储的实数值。而在将导数二值化的时候,sign函数其实只考虑了所存储的实数参数的符号,而没有考虑存储实数参数的量级,由于一些训练上的考虑,实数值网络内部的参数值,往往集中在 0附近,而直接把它二值化到+1 或者-1,会导致网络计算导数值所参考的参数和网络实际更新的参数有很大差距,使得网络难于收敛到较高精度。即
在训练阶段,由于Loss关于二值权重的梯度通常很小,因此较难引起实数权重的变化。
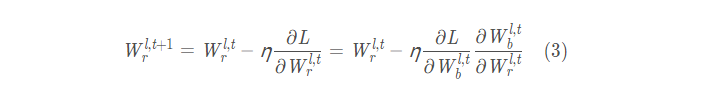
基于这个观察,我们提出,在训练的时候,将网络中存储的实数值的量级计入考虑。
文章为此引入了实数权重的幅度信息,
即在训练时将实数权重的Sign操作替换为Magnitude-aware Sign操作,能够增加二值权重关于实数权重的梯度,从而增加实数权重更新的步长,有助于加快模型的收敛速度:
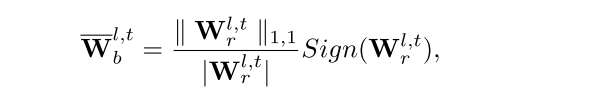
最终用于更新实数权重的递归公式如下:

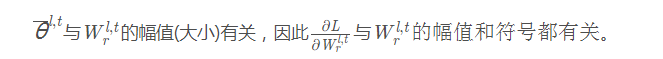
其中更新步长中的乘积项为Loss关于实数激活的梯度、BN层Gamma系数、二值激活、以及Magnitude-aware Sign操作的梯度。Magnitude-aware Sign操作的梯度,即二值权重关于实数权重的梯度表示为(Sign函数的求导仍然采用Clip函数近似):
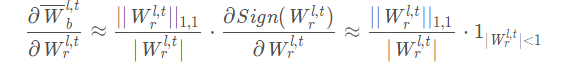
由于模型在推理部署阶段,实数权重的二值化仍然采用常规的Sign操作,因此采用Magnitude-aware Sign操作训练模型并收敛之后,需要采用Sign操作额外训练若干epoch更新BN层moving参数(此时learning rate置零),以适应实际部署的需求。
这种方法大大缩小了二值化参数与网络内部存储的用于更新的实值参数之间的差距,达到23% 的网络精度值相对提升。
二值化网络的初始化方法
从二值化参数更新的方法里也可以看出,内部所存储的实数值代表了二值化参数能改变符号的可能性,因此初始化的实数值选取非常重要。之前的工作都是直接采用随机初始化(XnorNet)或者是直接用以ReLU 为非线性函数的实数值网络初始化。
由于二值网络的二值化输出为{-1,1},不包含零元素,故在更新预训练模型的参数时,选择clip函数替代ReLU作为非线性激活函数能够获得更好的初始化效果,将进一步带来性能提升。

同时在二值网络的训练阶段,weight decay置零,即不需要对实数权重作L1或L2正则化约束。并且两个one layer per block的shortcut结构要优于一个two layer per block的shortcut结构,具体见实验分析。
实验结果表明Bi-Real Net在CIFAR10/100、ImageNet等数据集上的表现优于XNOR-net、ABC-net等,且参数量更少,非常适合移动端部署,并借助NEON指令集加速:
