设计一个缓存系统,不得不要考虑的问题就是:缓存穿透、缓存击穿与失效时的雪崩效应。
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
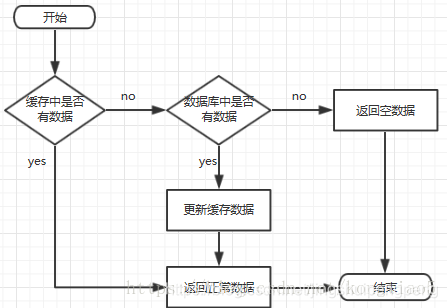
穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存是不命中时被动写的,并且出于容错 考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如5秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没
读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
1、设置热点数据永远不过期。
2、接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些 服务 不可用时候,进行熔断,失败快速返回机制。
3、布隆过滤器。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小,
4、使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为 空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}
雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,
缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
设置热点数据永远不过期。
数据一致性
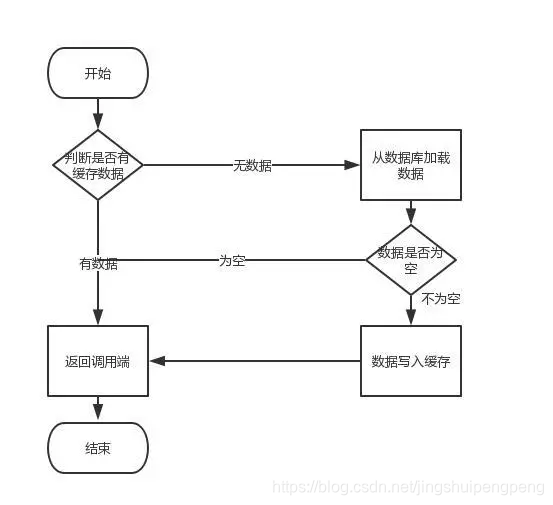
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存(Redis)和数据库(MySQL)间的数据一致性问题。
不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。举一个例子:
1.如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
2.如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。
如来解决?这里给出两个解决方案,先易后难,结合业务和技术代价选择使用。
缓存和数据库一致性解决方案
1.第一种方案:采用延时双删策略
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(500);
redis.delKey(key);
}
那么,这个500毫秒怎么确定的,具体该休眠多久呢?
需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
当然这种策略还要考虑redis和数据库主从同步的耗时。最后的的写数据的休眠时间:则在读数据业务逻辑的耗时基础上,加几百ms即可。比如:休眠1秒。
3.设置缓存过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
4.该方案的弊端
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致,而且又增加了写请求的耗时。
参见:https://www.jianshu.com/p/61c6f30dc043
https://blog.csdn.net/qq_16803227/article/details/92001895
