一般情况下面试大数据岗位的时候都会问到flume,我们之前也对flume进行过总结,不过时间太快了,转眼到了2020年。下面根据本人最新的flume相关面试并总结最准确的答案如下:
本文目录
友情提示:本专栏涉及大数据面试题及相关知识点不同于大多数的网络复制文,是博主精心准备和总结的最新的面试及知识点,喜欢就订阅噢,后续还会进行flink源码解析,spark源码解析,欢迎关注博客,大家一起讨论学习!
一、Flume的Source,Sink,Channel的作用?你们Source是什么类型?
1.1、首先各组件的作用
-
Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy
-
Channel组件对采集到的数据进行缓存,可以存放在Memory或File中。
-
Sink组件是用于把数据发送(下沉)到目的地的组件,目的地包括Hdfs、Logger、avro、thrift、ipc、file、Hbase、solr、自定义。
1.2、实际生产常用的Source类型为:
- 监控后台日志:exec 监控tail -F /dir;
- 监控后台产生日志的端口:netcat,exec, spooldir;
- 我们还自定义了mysqlSource用来监控mysql。
二、你对Flume的Channel Selectors了解多少?
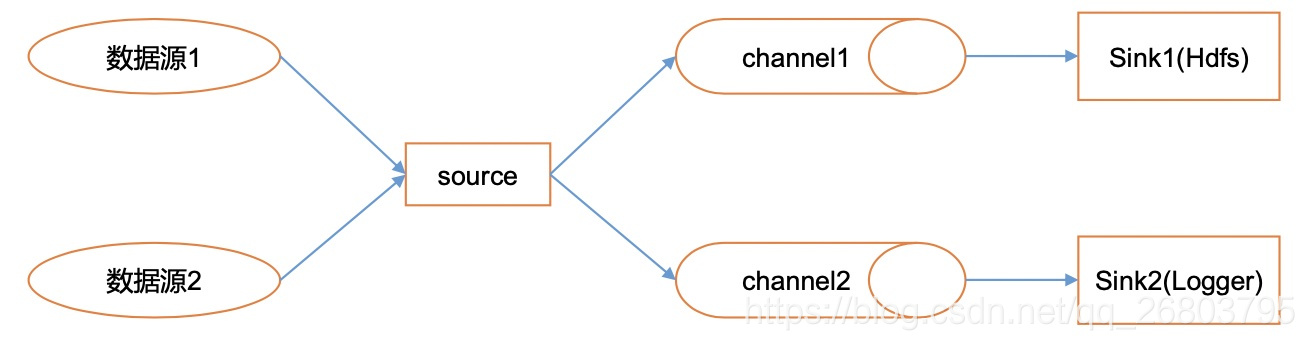
Channel Selectors主要功能是可以让不同的项目日志通过不同的channel流到不同的sink里去。Channel Selectors有两种类型:默认的Replicating Channel Selector和Multiplexing Channel Selector。
这两种selector的区别是:Replicating 会将source过来的events发往所有channel,但是Multiplexing可以选择该发往哪些Channel。
三、讲一讲你们之前怎么对flume调优的?
flume调优主要根据三个组件分为以下三个方面:
3.1、Source调优
**增加Source个数(使用Tair Dir这类Source时可增加FileGroups个数)可以增大Source的读取数据的能力。**例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件目录,同时配置好多个Source 以保证Source有足够的能力获取到新产生的数据。
batchSize参数决定Source一次批量运输到Channel的event条数,适当调大这个参数可以提高Source搬运Event到Channel时的性能。
3.2、Channel调优
虽然channel的type选择memory时Channel的性能最好,但是如果Flume进程意外挂掉可能会丢失数据。type选择file时Channel的容错性更好,但是性能上会比memory channel差。
使用file Channel时dataDirs配置多个不同盘下的目录可以提高性能。
checkpointDir 和 backupCheckpointDir 也尽量配置在不同硬盘对应的目录中,保证 checkpoint 坏掉后,可以快速使用backupCheckpointDir 恢复数据
Capacity 参数决定Channel可容纳最大的event条数。transactionCapacity 参数决定每次Source往channel里面写的最大event条数和每次Sink从channel里面读的最大event条数。transactionCapacity需要大于Source和Sink的batchSize参数。**
3.3、Sink调优
增加Sink的个数可以增加Sink消费event的能力。Sink也不是越多越好够用就行,过多的Sink会占用系统资源,造成系统资源不必要的浪费。
batchSize参数决定Sink一次批量从Channel读取的event条数,适当调大这个参数可以提高Sink从Channel搬出event的性能。
四、你熟悉flume的事务机制吗?
Flume的事务机制(类似数据库的事务机制):Flume使用两个独立的事务(flume ng开始,也就是1.X版本)分别负责从Soucrce到Channel,以及从Channel到Sink的事件传递。Source 到 Channel 是 Put 事务,Channel 到 Sink 是 Take 事务,比如spooling directory类型的source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到Channel且提交成功,那么Soucrce就将该文件标记为完成。同理,事务以类似的方式处理从Channel到Sink的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到Channel中,等待重新传递。
五、你们用Flume采集数据有丢失数据吗?
没有丢失,Channel存储可以存储在File中,数据传输自身有事务,只会出现很低的重复,不会有丢失。
六、追问,你怎么确定没有丢失数据呢?
主要考察怎么监控的flume,有两种回答方式:
- 如果是cdh集群,就是cdh监控来看,没有缺失。
- 如果是原生大数据集群环境,一般是使用的第三方监控框架Ganglia实时监控的flume。
七、你了解flume拦截器吗?有自定义过吗?
我们之前部署的flume有ETL拦截器和类型区分拦截器。 采用这两个拦截器主要是为了模块化开发和提高可移植性;但是性能会低一些。
自定义flume拦截器步骤如下:
- 实现Interceptor接口
- 重写如下四个方法:
- Initialize 初始化
- public Event intercept(Event event)处理单个Event
- public List intercept(List events) 处理多个 Event,在这个 方法中调用 Event intercept(Event event)
- close 方法
- 静态内部类实现Interceptor.Builder
八、你们flume sink数据到hdfs后,有没有出现大量小文件的情况?怎么处理的?
一般刚设计好,没有考虑完善的时候都是出现过的,可以从大量小文件对hdfs的影响入手,然后再讲解决方案。如下:
8.1、hdfs存入大量小文件,会带来的影响
- 元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属 组,权限,创建时间等,这些信息都保存在 Namenode 内存中。所以小文件过多,会占用 Namenode 服务器大量内存,影响 Namenode 性能和使用寿命;
- 计算层面:默认情况下MR会对每个小文件启用一个Map任务计算,非常影响计算性能,同时也影响磁盘寻址时间。
8.2、sink进hdfs大量小文件主要是如下原因造成的:
-
官方默认的这三个参数配置写入 HDFS 后会产生小文件,hdfs.rollInterval、hdfs.rollSize、 hdfs.rollCount;
比如hdfs.rollInterval=3600,hdfs.rollSize=134217728 , hdfs.rollCount =0,hdfs.roundValue=3600,hdfs.roundUnit=second在这几个参数的综合作用下,效果如下:
- tmp 文件在达到 128M 时会滚动生成正式文件;
- tmp 文件创建超 3600 秒时会滚动生成正式文件
- 举例:在 2020-04-03 06:26 的时侯 sink 接收到数据,那会产生如下 tmp 文件: /rople/20200403/file.202004030626.tmp 即使文件内容没有达到 128M,也会在07:26时滚动生成正式文件。
8.3、解决这个问题的方案
- 去掉round时间系列参数,并将rollSize和rollCount置0,表示不根据临时文件大小和event数量来滚动文件(滚动文件即指将HDFS上生成的以.tmp结尾的临时文件转换为实际存储文件)。当然,也可以调大rollSize参数(如调至100000000,表示100MB滚动文件,单位是bytes)。
- 设置
a1.sinks.k1.hdfs.minBlockReplicas=1,这样文件会因为所在块的复制而滚动文件。
