前言:
学校开了个线上创业课培训,依托的是第三方店铺平台进行授课和考试,不给word题库但是可以线上练习,那能不能把题库的内容爬取下来呢?
思路:
电脑登录微信pc端
fiddler分析
爬取考试网页api
requests请求获取json
写入csv
动手:
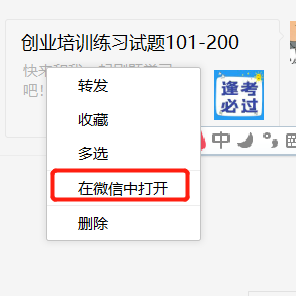
在微信pc端中用在微信中打开,因为用浏览器肯定限制了请求头为微信内置的请求头
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1295.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat',
 点击立即练习-交卷
点击立即练习-交卷
 打开Fiddler-点击查看解析-抓取来自微信的请求
打开Fiddler-点击查看解析-抓取来自微信的请求

找到来自wechat的真实请求网址,不多说,直接把header保存下来
header={
'Cache-Control': 'max-age=0',
'Accept': 'application/json',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.5;q=0.4',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1295.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat',
'X-Requested-With':'XMLHttpRequest',
'Content-Length':'185',
'Content-Type': 'application/x-www-form-urlencoded',
'Referer': 'https://appl0u0rcfq7859.h5.xiaoeknow.com/evaluation_wechat/practice/enter/wb_5e6fa59c8c845_cz016qLq',
'Origin': 'https://appl0u0rcfq7859.h5.xiaoeknow.com',
'Host': 'appl0u0rcfq7859.h5.xiaoeknow.com'
}
当然不能忘记了cookies

然后对cookie进行处理成字典形式:
Cookie=Cookie.split(';')
dict={}
for i in Cookie:
a=i.split('=')
dict[a[0]]=a[1]
{'ko_token': '***************', 'sajssdk_2015_cross_new_user': '1', 'sa_jssdk_2015_appl0u0rcfq7859': '%7B%22distinct_id%22%3A%22u_5e53690c59efc_MyN7iue94u%22%2C%22%24device_id%22%3A%22170fad24486507-0b3393d5380542-8011274-2073600-170fad24487437%22%2C%22props%22%3A%7B%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22170fad24486507-0b3393d5380542-8011274-2073600-170fad24487437%22%7D', 'Hm_lvt_17bc0e24e08f56c0c13a512a76c458fb': '1584756049', 'Hm_lpvt_17bc0e24e08f56c0c13a512a76c458fb':
'1584766252', 'sensorsdata2015jssdkcross': '%7B%22distinct_id%22%3A%22170fad24486507-0b3393d5380542-8011274-2073600-170fad24487437%22%2C%22%24device_id%22%3A%22170fad24486507-0b3393d5380542-8011274-2073600-170fad24487437%22%2C%22props%22%3A%7B%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D', 'dataUpJssdkCookie': '{"wxver":"7.0.5","net":"WIFI","sid":"1584756049206_merhds"}', 'bizData%5Bresource_id%5D': 'wb_5e6fa59c8c845_cz016qLq&bizData%5Bpage%5D'}
可以发现’Hm_lvt_17bc0e24e08f56c0c13a512a76c458fb’,'Hm_lpvt_17bc0e24e08f56c0c13a512a76c458fb’涉及了时间戳,不出意外应该是cookie的到期时间,经过转换发现短暂的时间内是不会到期,所以不用考虑(毕竟一会就爬取完了)
再来到fiddler,打开返回的json

可以发现题目已经出现了,好,直接开始请求
url='https://appl0u0rcfq7859.h5.xiaoeknow.com/evaluation_wechat/practices/get_question'
res=requests.post(url,headers=header,params=dict,verify=False)
a=res.json()
打印返回的json:
{'code': 0, 'msg': 'success', 'data': {}}
??msg显示请求成功,但是data里面却没有任何数据,啥情况,回过头来到fiddler中发现,一个api仅仅返回了10个题目,但是题库一次是100个题目,很明显,在请求种有参数要添加,通过分析header发现没有可以作为参数的标识
并且

每跨越10个题目都会请求一次

而且在请求头中有form表单的要求


在webform中可以发现果然有要携带的参数,分析请求的两次api,每一次都返回了10个题目,而且 ‘bizData[page_size]’ 'bizData[type]'两个参数在两个api中是没有变化的,page_size=10,很明显,这个参数是要求了请求的题目数量,所以:
data = {
'bizData[resource_id]':'wb_5e6fa5e192213_FtUmTibP',
'bizData[page_size]':100,
'bizData[type]':'practice'
}
重新请求:
res=requests.post(url,headers=header,params=dict,data=data,verify=False)
a=res.json()

成功返回题目!
写入json文件:
with open("F:Code/question.json","w") as f:
json.dump(a,f)
print("完成...")

\u7ec4\u5efa\u56e2\为utf-8格式,幸好,python自动转码。
分析json:

取第一个题目可以发现,correct_answer键对应了正确的选项,option对应了ABCD的选项,并且correct_answer参数和选项option对应的id是一致的,即正确的答案,那我们就来一个判断:
for i in range(100):
ques=question['data']['practice_list'][i]['content']
ques=ques.replace('<p>','').replace('</p>','')
for n in range(4):
if question['data']['practice_list'][i]['option'][n]['id']==question['data']['practice_list'][i]['correct_answer'][0]:
answer=question['data']['practice_list'][i]['option'][n]['describ']
print(f'题目 {ques}\n答案 {answer}')
找到当前题目correct_answer=option对应的id

然后我们写入csv中:
for i in range(100):
ques=question['data']['practice_list'][i]['content']
ques=ques.replace('<p>','').replace('</p>','')
for n in range(4):
if question['data']['practice_list'][i]['option'][n]['id']==question['data']['practice_list'][i]['correct_answer'][0]:
answer=question['data']['practice_list'][i]['option'][n]['describ']
data=[[ques,answer]]
with open('./quest3.csv', 'a+',newline='') as f:
w = csv.writer(f)
w.writerows(data)
print('完成!')

OK,考试时候直接ctrl+f查询对应题目即可!
完整代码:
import requests,json
url='https://appl0u0rcfq7859.h5.xiaoeknow.com/evaluation_wechat/practices/get_question '
header={
'Cache-Control': 'max-age=0',
'Accept': 'application/json',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.5;q=0.4',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1295.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat',
'X-Requested-With':'XMLHttpRequest',
'Content-Length':'185',
'Content-Type': 'application/x-www-form-urlencoded',
'Referer': 'https://appl0u0rcfq7859.h5.xiaoeknow.com/evaluation_wechat/practice/enter/wb_5e6fa59c8c845_cz016qLq',
'Origin': 'https://appl0u0rcfq7859.h5.xiaoeknow.com',
'Host': 'appl0u0rcfq7859.h5.xiaoeknow.com'
}
Cookie='ko_token=**********************;\
sajssdk_2015_cross_new_user=1;\
sa_jssdk_2015_appl0u0rcfq7859=%7B%22distinct_id%22%3A%22u_5e53690c59efc_MyN7iue94u%22%2C%22%24device_id%22%3A%22170fad24486507-0b3393d5380542-8011274-2073600-170fad24487437%22%2C%22props%22%3A%7B%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22170fad24486507-0b3393d5380542-8011274-2073600-170fad24487437%22%7D;\
Hm_lvt_17bc0e24e08f56c0c13a512a76c458fb=1584756049;\
Hm_lpvt_17bc0e24e08f56c0c13a512a76c458fb=1584766252;\
sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22170fad24486507-0b3393d5380542-8011274-2073600-170fad24487437%22%2C%22%24device_id%22%3A%22170fad24486507-0b3393d5380542-8011274-2073600-170fad24487437%22%2C%22props%22%3A%7B%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D;\
dataUpJssdkCookie={"wxver":"7.0.5","net":"WIFI","sid":"1584756049206_merhds"};\
bizData%5Bresource_id%5D=wb_5e6fa59c8c845_cz016qLq&bizData%5Bpage%5D=1&bizData%5Bpage_size%5D=10&bizData%5Btype%5D=practice'
Cookie=Cookie.split(';')
dict={}
for i in Cookie:
a=i.split('=')
dict[a[0]]=a[1]
print(dict)
data = {
'bizData[resource_id]':'wb_5e6fa5e192213_FtUmTibP',
'bizData[page_size]':100,
'bizData[type]':'practice'
}
res=requests.post(url,headers=header,params=dict,data=data,verify=False)
a=res.json()
with open("F:Code/3.json","w") as f:
json.dump(a,f)
print("加载入文件完成...")
import json,csv
with open("../3.json",'r') as load_f:
load_dict = json.load(load_f)
question=load_dict
for i in range(100):
ques=question['data']['practice_list'][i]['content']
ques=ques.replace('<p>','').replace('</p>','')
for n in range(4):
if question['data']['practice_list'][i]['option'][n]['id']==question['data']['practice_list'][i]['correct_answer'][0]:
answer=question['data']['practice_list'][i]['option'][n]['describ']
data=[[ques,answer]]
with open('./quest3.csv', 'a+',newline='') as f:
w = csv.writer(f)
w.writerows(data)
print('完成!')
