在爬取一些网站的时候,结合from lxml import etree库中etree.HTML()可以构造一个符合xpath语法的html文本,为了方便,我们可以F12-copy xpath获取该元素在网页中的xpath语法,但是其复制的为绝对路径,在某些时候是无法定位出元素的。
HTML(text, parser = None, base_url = None)
从字符串常量解析HTML文档。返回根节点(或解析器目标返回的结果)。此函数可用于在Python代码中嵌入“ HTML文字”。
https://lxml.de/api/lxml.etree-module.html#HTML
以爬取研招网院校库(https://yz.chsi.com.cn/sch/)为例子
1:使用copy xpath方法
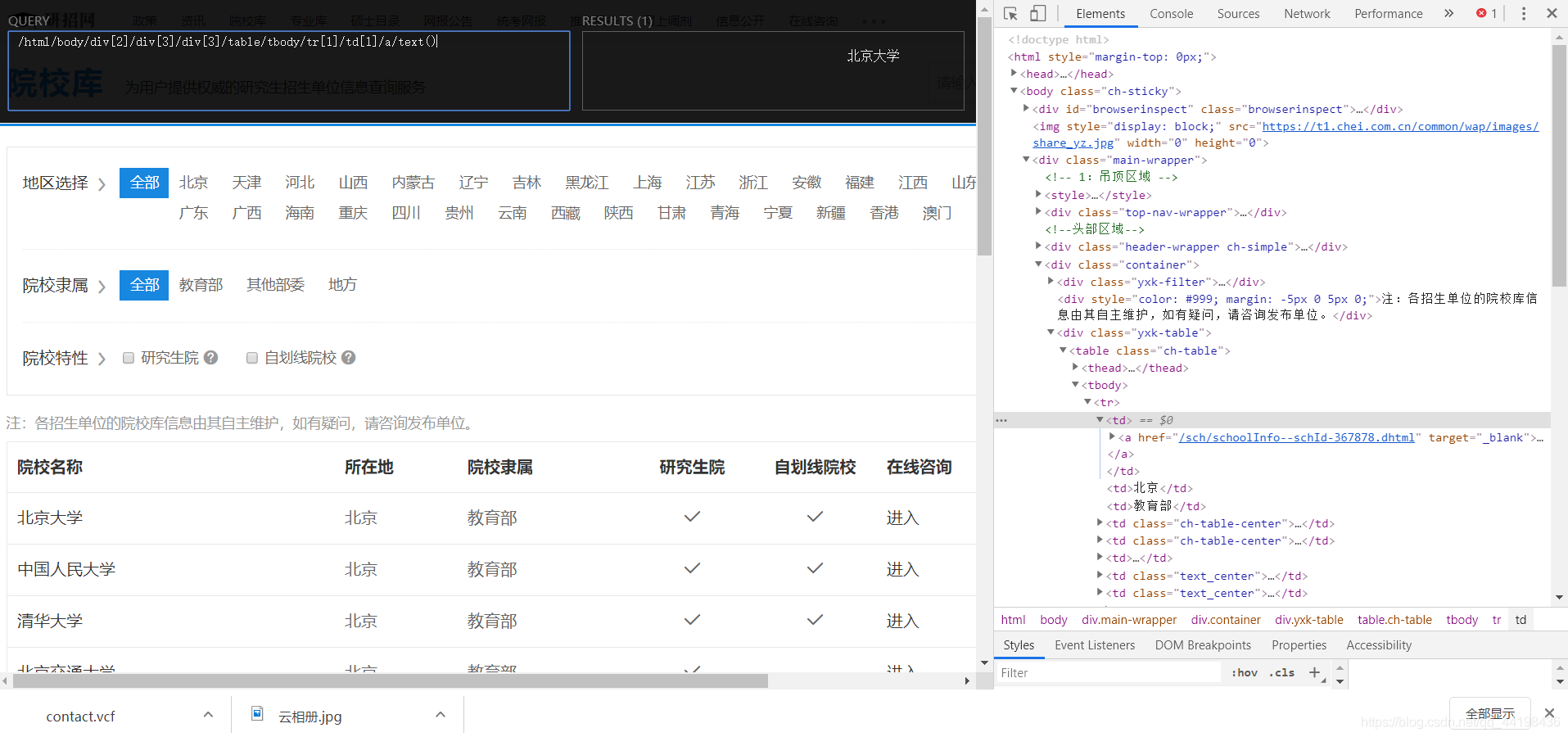
这是xpath(绝对路径):
/html/body/div[2]/div[3]/div[3]/table/tbody/tr[1]/td[1]/a/text()
import requests
from lxml import etree
url='https://yz.chsi.com.cn/sch/'
res=requests.get(url).text
if len(res)>100:#是否解析出text
print('解析成功')
dom=etree.HTML(res)
text=dom.xpath('/html/body/div[2]/div[3]/div[3]/table/tbody/tr[1]/td[1]/a/text()')
print(text)

是一个空列表,但在xpath helper中可以解析出北京大学,说明xpath是对的。
2:使用相对路径:

xpath语法[需要手写]:
//*[@class="yxk-table"]/table/tbody/tr[1]/td[1]/a/text()
import requests
from lxml import etree
url='https://yz.chsi.com.cn/sch/'
res=requests.get(url).text
if len(res)>100:#是否解析出text
print('解析成功')
dom=etree.HTML(res)
text=dom.xpath('//*[@class="yxk-table"]/table/tbody/tr[1]/td[1]/a/text()')
print(text)

使用相对路径时候则可以解析出文本
