文章目录
不知道这算不算讽刺?上了这么多年学,也当了几年Java程序猿了,之前我竟然对Java中的对象一直都感到模糊不清:知道每一个对象会有对象头;知道对象头里会存放一些信息,但具体什么,说不清。。。
1 java对象布局(hotspot虚拟机)简介
在JVM中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。如下图所示:
术语可参考: http://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html
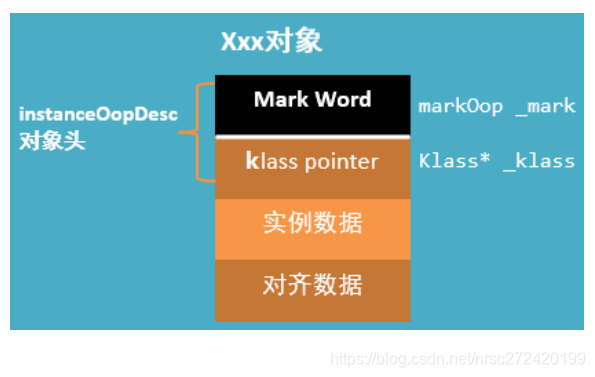
1.2 实例数据 — 可以没有
就是类中定义的成员变量。
1.3 对齐填充 — 有可能会没有
对齐填充并不是必然存在的,也没有什么特别的意义,他仅仅起着占位符的作用,由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说,就是对象的大小必须是8字节的整数倍。而对象头正好是8字节的倍数,因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
1.4 对象头
1.4.1 对象头在JDK(hotspot)源码中具体的体现
当一个线程尝试访问synchronized修饰的代码块时,它首先要获得锁,那么这个锁到底存在哪里呢?其实就存在锁对象的对象头中的。
HotSpot采用instanceOopDesc和arrayOopDesc来描述对象头, arrayOopDesc对象用来描述数组类型。instanceOopDesc的定义的在Hotspot源码的 instanceOop. hpp 文件(src/share/vm/oops/instanceOop.hpp)中, arrayOopDesc定义在arrayOop.hpp文件(src/share/vm/oops/arrayOop.hpp)中 — 本文对数组类型不过多描述。

instanceOopDesc的源码如下:
class instanceOopDesc : public oopDesc {
public:
// aligned header size.
static int header_size() { return sizeof(instanceOopDesc)/HeapWordSize; }
// If compressed, the offset of the fields of the instance may not be aligned.
static int base_offset_in_bytes() {
// offset computation code breaks if UseCompressedClassPointers
// only is true
return (UseCompressedOops && UseCompressedClassPointers) ?
klass_gap_offset_in_bytes() :
sizeof(instanceOopDesc);
}
static bool contains_field_offset(int offset, int nonstatic_field_size) {
int base_in_bytes = base_offset_in_bytes();
return (offset >= base_in_bytes &&
(offset-base_in_bytes) < nonstatic_field_size * heapOopSize);
}
};
从instanceOopDesc代码中可以看到 instanceOopDesc继承自oopDesc,oopDesc的定义载Hotspot源码中的 oop. hpp 文件(src/share/vm/oops/oop.hpp)中,其部分源码如下:
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
// Fast access to barrier set. Must be initialized.
static BarrierSet* _bs;
// 省略其他代码
};
上面的代码其实就可以和文章开头的图片对应起来了。
在普通实例对象中, oopDesc的定义包含两个成员,分别是 _mark和 _metadata
-
_mark表示对象标记、属于markOop类型,也就是接下来要讲解的Mark World,它记录了对象和锁、GC年龄等有关的信息。 -
_metadata表示类元信息,类元信息存储的是对象指向它的类元数据(Klass)的首地址,其中Klass表示普通指针、_compressed_klass表示压缩类指针。
总结一下:
对象头由两部分组成,一部分用于存储自身的运行时数据,称之为 Mark Word,另外一部分是类型指针,及对象指向它的类元数据的指针。
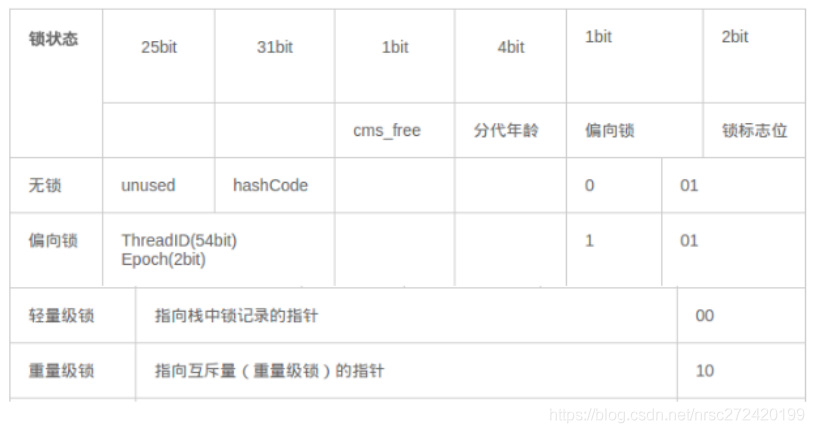
1.4.2 Mark Word
Mark Word用于存储对象自身的运行时数据,如哈希码( HashCode)、 GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,占用内存大小与虚拟机位长一致。 Mark Word对应的类型是 markOop 。源码位于markOop.hpp(src/share/vm/oops/markOop.hpp) 中。
markOop.hpp文件开头的注释里详细地描述了 Mark Word的存储结构,有兴趣的可以下载下来源码看一下:
源码地址:http://openjdk.java.net/ --> Mercurial --> jdk8 --> hotspot --> zip
当然如果下载不下来,也可以从我提供的源码里clone: https://github.com/nieandsun/concurrent-study.git
本文和其他博客里一样,将其总结为如下两张表格。
- 在32位虚拟机下, Mark Word是32bit大小的,其存储结构如下:

- 在64位虚拟机下, Mark Word是64bit大小的,其存储结构如下:
1.4.2 klass pointer
这一部分用于存储对象的类型指针,该指针指向它的类元数据, JVM通过这个指针确定对象是哪个类的实例。该指针的位长度为JVM的一个字大小,即32位的JVM为32位, 64位的JVM为64位。
如果应用的对象过多,使用64位的指针将浪费大量内存,统计而言, 64位的JVM将会比32位的JVM多耗费50%的内存。为了节约内存可以使用选项 -XX:+UseCompressedOops 开启指针压缩。开启该选项后,下列指针将压缩至32位:
- (1 )每个Class的属性指针(即静态变量)
- (2)每个对象的属性指针(即对象变量)
- (3)普通对象数组的每个元素指针
当然,也不是所有的指针都会被压缩,一些特殊类型的指针JVM不会优化,比如指向PermGen的Class对象指针(JDK8中指向元空间的Class对象指针)、本地变量、堆栈元素、入参、返回值和NULL指针等。
1.4.3 对象头大小的计算方式
对象头 = Mark Word + 类型指针(未开启指针压缩的情况下)
在32位系统中, Mark Word = 4 bytes,类型指针 = 4bytes,对象头 = 8 bytes = 64 bits;
在64位系统中, Mark Word = 8 bytes,类型指针 = 8bytes,对象头 = 16 bytes = 128bits;
2 对Java对象布局的证明
2.1 引入openjdk提供的jar包
首先需要引入如下jar包:
<!--查看java对象布局工具类-->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
2.2 Java对象布局的证明 — 64位JVM
有如下对象:
package com.nrsc.ch1.base.jmm.syn_study.deep;
public class JavaObj {
private int a;
}
可以使用下面的程序来打印上面对象的布局:
package com.nrsc.ch1.base.jmm.syn_study.deep;
import org.openjdk.jol.info.ClassLayout;
public class JavaObjTest {
public static void main(String[] args) {
JavaObj javaObj = new JavaObj();
//打印javaObj的对象布局
System.err.println(ClassLayout.parseInstance(javaObj).toPrintable());
}
}
打印结果如下: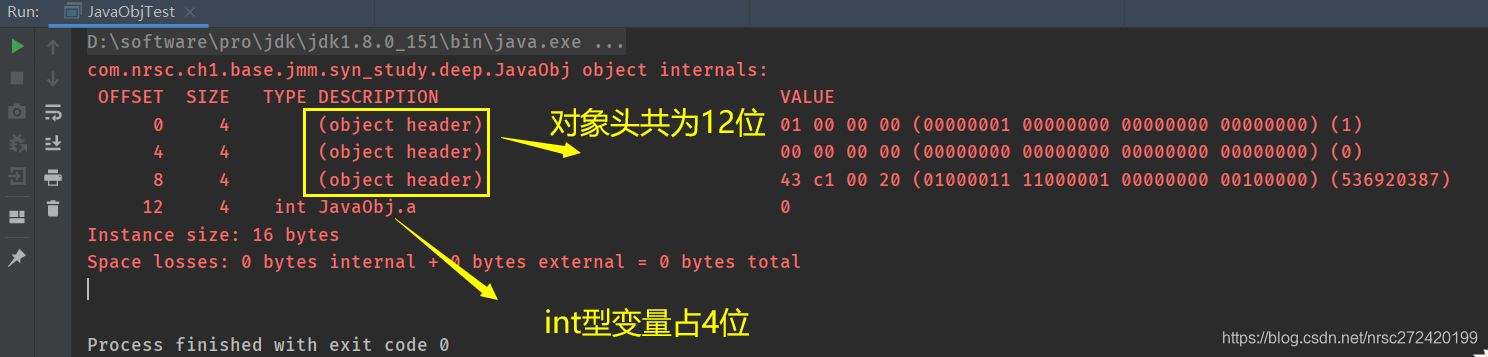
从上图可以看出:
- (1) 对齐填充确实可以没有—> 因为对象头 (12bytes)+ int类型变量(4bytes) = 16bytes,而16是8的倍数,所以无需对齐填充
- (2)对象头为12位,与1.4.3中所说的16位不一致 —> 原因是因为
JVM默认开启了指针压缩
可以指定如下JVM运行参数来关闭指针压缩:
-XX:-UseCompressedOops
关闭指针压缩的情况:

2.3 Mark Word中hashCode的证明
从2.2中的输出结果来看,并没有1.4.2小结表中所说的hashCode —》这是因为要使用了该对象的hashCode()方法,才会将该对象的hashCode存到对象头里。
要想看到对象的对象头里存放的hashCode打印对象布局的程序就应该这样写了:
package com.nrsc.ch1.base.jmm.syn_study.deep;
import org.openjdk.jol.info.ClassLayout;
public class JavaObjTest {
public static void main(String[] args) {
JavaObj javaObj = new JavaObj();
//调用javaObj的hashCode方法
int hashCode = javaObj.hashCode();
//将hashCode转为16进制,因为打印的对象头里可以看出16进制的存储数据
System.out.println(Integer.toHexString(hashCode));
//打印javaObj的对象布局
System.err.println(ClassLayout.parseInstance(javaObj).toPrintable());
}
}
打印结果如下:

可以看到对象头里确实存放了对象的hashCode。
同时要注意将该图与1.4.2中64位JVM Mark Word的存储结构相对应。 —> 为了方便对比,我在下面在接该表贴一遍吧:

同时为了更清楚的显示出hashCode确实占了31位,且确实在那个位置 。我在画完上图后又对程序做了稍许改动,将hashCode的2进制也打印了出来
- code如下:
package com.nrsc.ch1.base.jmm.syn_study.deep;
import org.openjdk.jol.info.ClassLayout;
public class JavaObjTest {
public static void main(String[] args) {
JavaObj javaObj = new JavaObj();
//调用javaObj的hashCode方法
int hashCode = javaObj.hashCode();
//将hashCode转为16进制,因为打印的对象头里可以看出16进制的存储数据
System.out.println(Integer.toHexString(hashCode));
//将hashCode转为2进制,因为打印的对象头里也可以看出2进制的存储数据
System.out.println(Integer.toBinaryString(hashCode));
//打印javaObj的对象布局
System.err.println(ClassLayout.parseInstance(javaObj).toPrintable());
}
}
- 打印结果如下
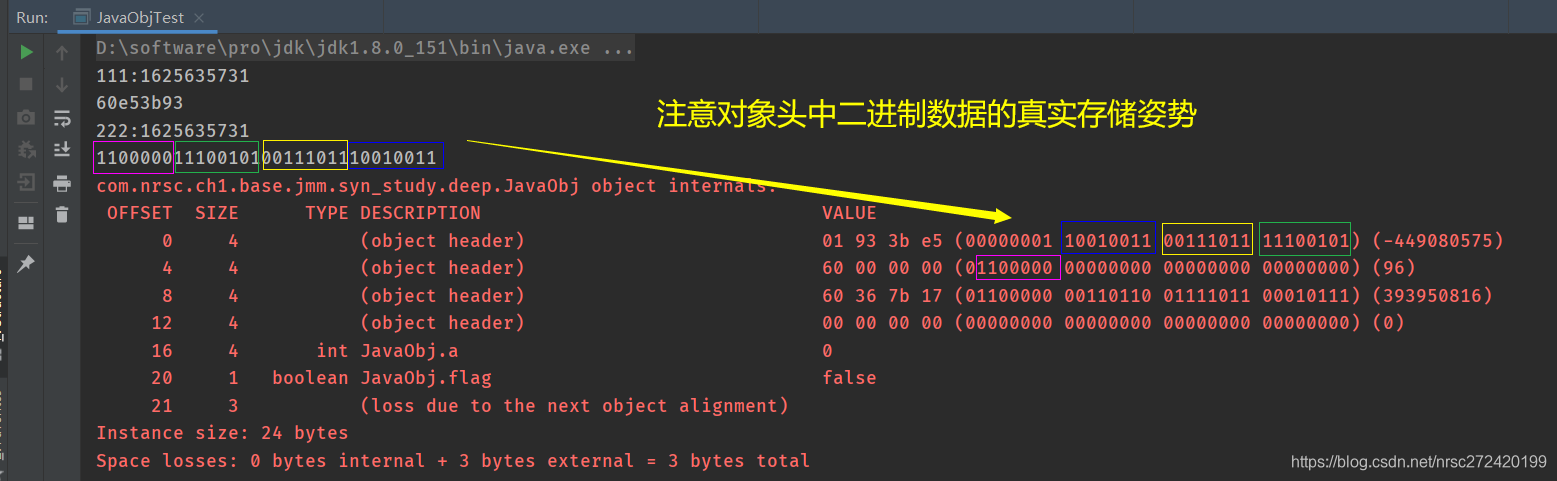
注意:由于大小端的问题,需要注意对象头中二进制数据的真实存储姿势。
有没有感觉读完这篇文章,接下来对synchronized关键字锁升级的过程,我们都可以进行证实了☺☺☺
end
