数据分析
使用pd读取,再使用np处理,np.min(数据,axis=)
其中min,max,median;最小,最大,中位数;aixs=0表示每列运算
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv.csv',header=0,\
encoding='gbk',dtype={'年龄':float})
sele_att=["年龄","身高"]
print('求最小值----')
print(np.min(df[sele_att],axis=0))
print('求最大值----')
print(np.max(df[sele_att],axis=0))
print('求最中位值----')
print(np.median(df[sele_att],axis=0))
'''
求最小值----
年龄 4.0
身高 160.0
dtype: float64
求最大值----
年龄 35.0
身高 180.0
dtype: float64
求最中位值----
[ 13. 175.]
'''
使用pandas自身函数处理,使用: df[列名列表].min(axis=)
axis的作用同np中相同,最大值max(),中位数median(),累加值cumsum(),总和sum(),分位数quantile(),describe()无参时,是对列数值型数据的描述,当describe(include=[“object”])时,统计所有对象
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv.csv',header=0,\
encoding='gbk',dtype={'年龄':float})
sele_att=["年龄","身高"]
print('求最小值----')
print(df[sele_att].min(axis=0))
print('求最大值----')
print(df[sele_att].max(axis=0))
print('求最中位值----')
print(df[sele_att].median(axis=0))
print('求每列累加值----')
print(df[sele_att].cumsum(axis=0))
print('求每列加和值----')
print(df[sele_att].sum(axis=0))
print('求每列分位数值----')
print(df[sele_att].quantile([0,0.2,0.5,1.0],axis=0))
print('对数值列的计算描述----')
print(df[sele_att].describe())
print('对所有列的对象描述----')
print(df.describe(include=['object']))
'''
求最小值----
年龄 4.0
身高 160.0
dtype: float64
求最大值----
年龄 35.0
身高 180.0
dtype: float64
求最中位值----
年龄 13.0
身高 175.0
dtype: float64
求每列累加值----
年龄 身高
0 20.0 180.0
1 55.0 350.0
2 78.0 510.0
3 83.0 685.0
4 89.0 865.0
5 93.0 1040.0
求每列加和值----
年龄 93.0
身高 1040.0
dtype: float64
求每列分位数值----
年龄 身高
0.0 4.0 160.0
0.2 5.0 170.0
0.5 13.0 175.0
1.0 35.0 180.0
对数值列的计算描述----
年龄 身高
count 6.000000 6.000000
mean 15.500000 173.333333
std 12.565827 7.527727
min 4.000000 160.000000
25% 5.250000 171.250000
50% 13.000000 175.000000
75% 22.250000 178.750000
max 35.000000 180.000000
对所有列的对象描述----
姓名 性别 地址
count 6 6 6
unique 6 2 6
top 小红 男 芬兰
freq 1 4 1
'''
分类汇总
首先,使用my_group=pd.groupby(by=依据的属性名列表)返回一个组对象,再对组对象处理my_group.mean() 等函数处理
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv.csv',header=0,\
encoding='gbk',dtype={'年龄':float})
groupde=df.groupby(by='身高')
print(groupde.mean())
print('--分割=='*3)
print(groupde.max())
print('--计数分割=='*3)
print(groupde.count())
print('--数据量分割=='*4)
print(groupde.size())
'''
年龄
身高
160 23.0
170 35.0
175 4.5
180 13.0
--分割==--分割==--分割==--分割==
姓名 年龄 性别 地址
身高
160 黑蛋 23.0 女 日本
170 狗子 35.0 男 加拿大
175 小红 5.0 男 韩国
180 王贵 20.0 男 美国
--分割==--分割==--分割==--分割==
姓名 年龄 性别 地址
身高
160 1 1 1 1
170 1 1 1 1
175 2 2 2 2
180 2 2 2 2
--分割==--分割==--分割==--分割==
身高
160 1
170 1
175 2
180 2
dtype: int64
'''
聚合函数agg(),针对相同索引的统计mean,sum,max等以及自己定义的函数
给每一列的属性同样的统计运算
建立好分组后(groupby())的变量设为grouped,使用**groupe.agg([np.mean,np.sum])**将组的数据可进行mean、sum等运算,数据列下会出现新的agg()的列属性。如下图所示,因为求平均与和只能用于数值型数据,除了数字的年龄(成为索引),另外就是

df=pd.read_csv('my_csv.csv',header=0,encoding='gbk',dtype={'年龄':float})
print(df)
'''
姓名 年龄 性别 地址 身高
0 王贵 20.0 男 美国 180
1 狗子 35.0 男 加拿大 170
2 黑蛋 23.0 女 日本 160
3 小五 5.0 男 韩国 175
4 李四 4.0 男 朝鲜 180
5 小红 4.0 女 芬兰 175
'''
# names 表示多个列的属性名称
names=["姓名","年龄","身高","地址"]
# df[names]产生一个以“年龄”作为索引的包含names中几个属性列
grouped= df[names].groupby('年龄')
#索引不变,求出几个属性列的平均值与和
print(grouped.agg([np.mean,np.sum]))
'''
身高
mean sum
年龄
4.0 177.5 355
5.0 175.0 175
20.0 180.0 180
23.0 160.0 160
35.0 170.0 170
'''
#对筛选后的数据进行loc,这个loc是对列的分层
print(grouped.agg([np.mean,np.sum]).loc[[4,5],('身高',['mean','sum'])])
'''
身高
mean sum
年龄
4.0 177.5 355
5.0 175.0 175
'''
给每一列的属性不同的统计运算(字典)
在agg()中使用字典作为参数可以对不同列进行最小、最大、平均的不同的计算,下面就对年龄的最大、最小,对体重的最大,身高的平均

import pandas as pd
import numpy as np
df=pd.read_csv('my_csv.csv',header=0,\
encoding='gbk',dtype={'年龄':float})
print(df)
names=["id","姓名","年龄","身高","体重"]
grouped= df[names].groupby('id')
print(grouped.agg({'年龄':(np.max,np.min),'体重':np.max,\
'身高':np.mean}))
自己定义的函数
自己定义函数doub_out(),作用:将一组数据累加后再乘以2
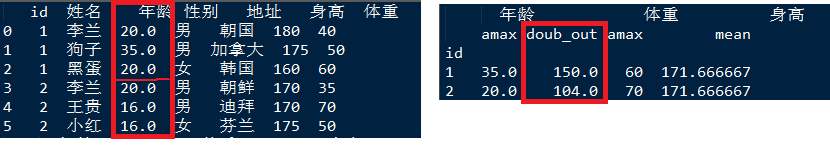
import pandas as pd
import numpy as np
def doub_out(data): #自己建立的运算函数
return(data.sum()*2)
df=pd.read_csv('my_csv.csv',header=0,\
encoding='gbk',dtype={'年龄':float})
print(df)
names=["id","姓名","年龄","身高","体重"]
grouped= df[names].groupby('id')
print(grouped.agg({'年龄':(np.max,doub_out),'体重':np.max, '身高':np.mean}))
