核心概念:
Tensorflow的计算模型-计算图
如果说TensorFlow的第一个词Tensor表明了它的数据结构,那么Flow则体现了它的计算模型。Flow翻译成中文就是“流”,它直观地表达了张量之间通过计算相互转化的过程。TensorFlow是一个通过计算图的形式来表述计算的编程系统,TensorFlow中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。
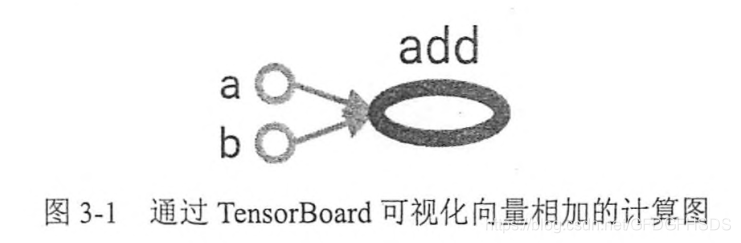
图3-1展示了通过TensorBoard”画出来的第2章中两个向量相加样例的计算图。如果一个运算的输入依赖于另一个运算的输出,那么这两个运算有依赖关系。在图3-1中,a和b这两个常量不依赖任何其他计算。而add 计算则依赖读取两个常量的取值。于是在图3-1中可以看到有一条从a到add的边和一条从b到add的边。在图3-1中,没有任何计算依赖add的结果,于是代表加法的节点add没有任何指向其他节点的边。这就是tensorflow的基本计算模型。
张量:
从TensorFlow的名字就可以看出张量(tensor)是一个很重要的概念。在TensorFlow程序中,所有的数据都通过张量的形式来表示。从功能的角度上看,张量可以被简单理解为多维数组。其中零阶张量表示标量(scalar),也就是一个数;第一阶张量为向量(vector),也就是一个一维数组;第n阶张量可以理解为一个n维数组。但张量在TensorFlow中的实现并不是直接采用数组的形式,它只是对TensorFlow中运算结果的引用。在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。一个张量中主要保存了三个属性:名字(name)、维度(shape)和类型(type)。张量的第一类用途是对中间计算结果的引用。当一个计算包含很多中间结果时,使用张量可以太大提高代码的可读性。张量的第二类用途是当计算图构造完成之后,张量可以用来获得计算结果,也就是得到真实的数字。这个要怎么获取呢?
会话:
答案就是会话(Sess)。意思就是先定义所有的计算,但是我先不执行,然后在TensorFlow程序的第二步声明一个会话(session),并通过会话计算结果,当会话定义完成之后就可以开始真正运行定义好的计算了。
在这里,要注意的是,像神经网络这么多的参数,或者参数变量之间存在依赖关系时,单个调用的方案就比较麻烦了。我不可能一个一个去定义,去初始化吧,为了解决这个问题,TensorFlow提供了一种更加便捷的方式来完成变量初始化过程。下面的程序展示了通过tf.initialize_all_variables函数实现初始化所有变量的过程。
init_op=tf.initialize_all_variables()
sess.run(init_op)
通过tf.all_variables函数可以拿到当前计算图上所有的变量。拿到计算图上所有的变量有助于持久化整个计算图的运行状态。
占位符placeholder:
我们知道,如果每轮迭代中选取的数据都要通过常量来表示,那么TensorFlow的计算图将会太大。因为每生成一个常量,TensorFlow都会在计算图中增加一个节点。一般来说,一个神经网络的训练过程会需要经过几百万轮甚至几亿轮的迭代,这样计算图就会非常大,而且利用率很低。为了避免这个问题,TensorFlow 提供了placeholder机制用于提供输入数据。placeholder相当于定义了一个位置,这个位置中的数据在程序运行时再指定。这样在程序中就不需要生成大量常量来提供输入数据,而只需要将数据通过placeholder传入TensorFlow 计算图。在placeholder定义时,这个位置上的数据类型是需要指定的。和其他张量一样,placeholder的类型也是不可以改变的。placeholder中数据的维度信息可以根据提供的数据推导得出,所以不一定要给出。tensorflow里对于暂时不进行赋值的元素有一个称呼叫占位符。所谓占位符,先占位,等需要时再赋值。下面表示给a赋予一个32位浮点数。具体多少,不知道,等到需要赋值的时候才知道。具体代码为:
1 import tensorflow as tf
2 a = tf.placeholder(tf.float32)
赋值feed_dict:
在新的程序中计算前向传播结果时,需要提供一个feed_dict来指定x的取值。feed_dict是一个字典(map),在字典中需要给出每个用到的placeholder的取值。如果某个需要的placeholder没有被指定取值,那么程序在运行时将会报错。在tensorflow中当我们使用占位符,tf.placeholder()后,tf.placeholder()需要批量化传值,那么这时候feed_dict排上用场。将之前的占位符连起来的具体代码为:
a = tf.placeholder(tf.float32)
sess.run(a)
b = tf.placeholder(tf.float32)
multiply = tf.multiply(a,b)
sess.run(multiply,feed_dict={a:8,b:2})
16.0
sess.close()
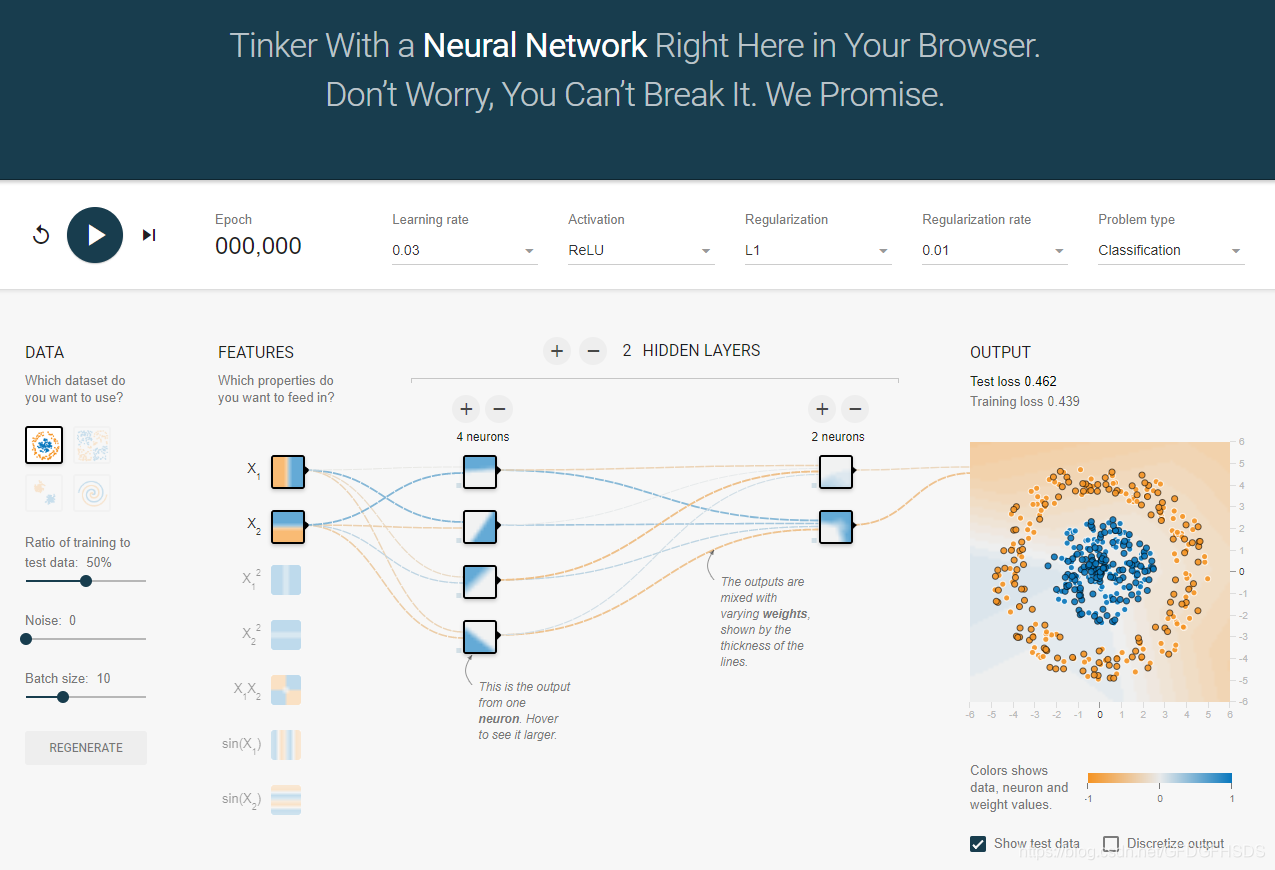
TensorFlow 游乐场
通过一个网页浏览器就可以训练的简单神经网络并实现了可视化训练过程的工具。神奇吧。搜TensorFlow 游乐场就出来了。
TensorBoard 可视化:
TensorBoard是TensorFlow的可视化工具,它可以通过TensorFlow程序运行过程中输出的日志文件可视化TensorFlow程序的运行状态。TensorBoard和TensorFlow 程序跑在不同的进程中,TensorBoard会自动读取最新的TensorFlow日志文件,并呈现当前TensorFlow程序运行的最新状态。以下代码展示了一个简单的TensorFlow程序,在这个程序中完成了TensorBoard日志输出的功能。用TensorFlow计算图的可视化结果。TensorFlow会将所有的计算以图的形式组织起来。TensorBoard可视化得到的图并不仅是将TensorFlow计算图中的节点和边直接可视化,它会根据每个TensorFlow计算节点的命名空间来整理可视化得到的效果图,使得神经网络的整体结构不会被过多的细节所淹没。除了显示TensorFlow计算图的结构,TensorBoard 还可以展示TensorFlow计算节点上的其他信息。

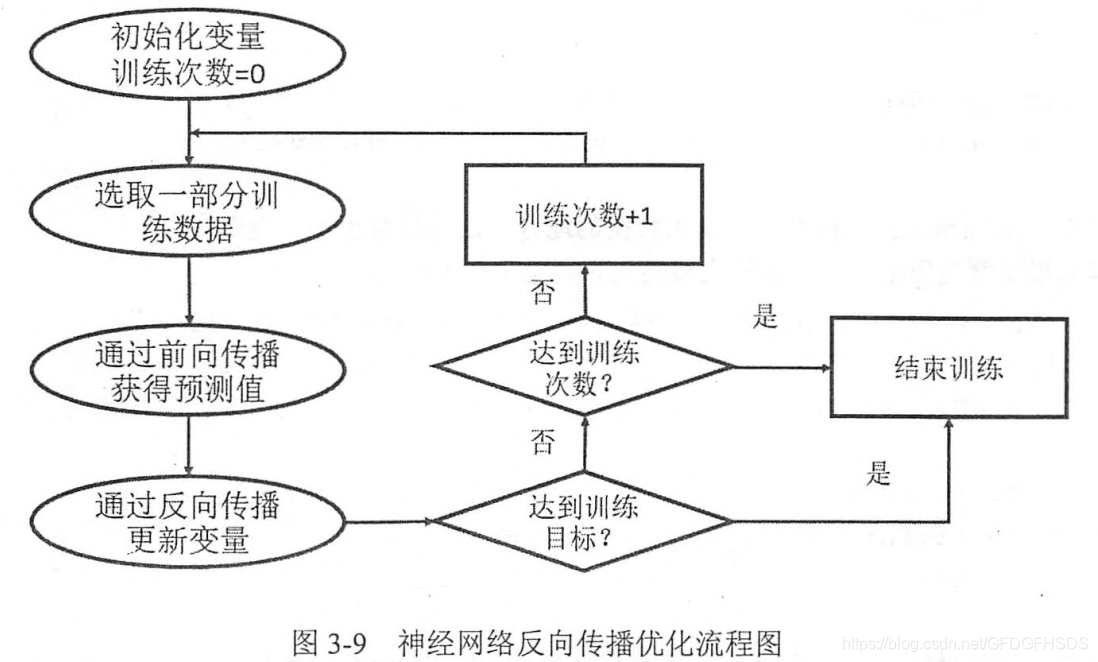
理解了核心概念之后来具体了解下使用tensorflow训练神经网络模型的步骤:
1.定义神经网络的结构和前向传播的输出结果。
2.定义损失函数以及选择反向传播优化的算法。
3.生成会话(tf.Session)并且在训练数据上反复运行反向传播优化算法。
 几个核心步骤,简单总结下
几个核心步骤,简单总结下
1.输入
输入有两种方案定义, 一是 使用 常量定义一个输入,
x = tf.constant([[0.7, 0.9]])
实际训练和推断时, 输入数据很多,所以使用常量的开销就非常大,。所以提供了 第二种 方案, 即 placeholder , 定义一个位置, 需要填充输入数据时, 往 这个位置 填充即可。
x = tf.placeholder(tf.float32, shape=(1, 2), name=“input”)
2 权重变量
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
3 前向网络
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
注意: x 既可以是 某个常量,也可以是 某个 placeholder
4 建立会话
sess = tf.Session()
5 初始化变量的两种方法
1:
init_op = tf.global_variables_initializer() //初始化所有变量
sess.run(init_op)
2:
sess.run(w1.initializer)
sess.run(w2.initializer)
6 运行: 将会话和网络输出关联起来
sess.run(y) // 使用常量提供输入
或者sess.run(y, feed_dict={x: [[0.7,0.9],[0.1,0.4],[0.5,0.8]]}) // 使用placeholder提供输入
完整神经网络样例程序如下;
#1 定义权重和输入
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
x = tf.placeholder(tf.float32, shape=(None, 2), name=“x-input”)
y_= tf.placeholder(tf.float32, shape=(None, 1), name=‘y-input’)
#2 定义前向传播过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
y = tf.sigmoid(y)
#3 定义损失函数和 优化算法
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))
+ (1 - y_) * tf.log(tf.clip_by_value(1 - y, 1e-10, 1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#4 获取输入数据
#这一步 要么是训练数据 要么 是处于测试目的,构造一些
#5 创建一个会话 来 执行 整个训练过程
with tf.Session() as sess:
for i in range(STEPS):
sess.run([train_step, y, y_], feed_dict={x: X[start:end], y_: Y[start:end]})
total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y}) // 这个调用是看当前的损失函数情况
#隐含层 Demo
def inference(input_tensor, weights1, biases1, weights2, biases2):
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
Tensorflow API
tf.where(tf.greater(y, y_), (y - y_) * loss_more, (y_ - y) * loss_less)
#类似 C 语言的 条件表达式, 三个输入
tf.train.exponential_decay(0.1, global_step, 100, 0.96, staircase=True)
#指数衰减的学习率
#每训练100次, 学习率乘以 0.96
tf.contrib.layers.l2_regularizer(lambda1)(var)
#对var 计算正则项,避免 过拟合
tf.train.ExponentialMovingAverage(0.99, step)
#滑动平均模型
训练时: 不断保持和 更新 各个 参数 滑动平均值(也就是影子变量)
验证和测试时: 参数(比如权重)的值 使用滑动平均值
#变量管理
with tf.variable_scope(“foo”):
v = tf.get_variable(“v”, [1], initializer=tf.constant_initializer(1.0))
在名字为 foo的名字空间内 创建名字为 v 的变量
with tf.variable_scope(“foo”, reuse=True):
#此时 tf.get_variable 获取已经创建的变量, 如果不存在,那么报错
with tf.variable_scope(“foo”, reuse=None):
with tf.variable_scope(“foo”, reuse=False):
#此时 tf.get_variable 创建新的变量, 如果同名变量存在, 那么报错
