简单的MapReduce实践
文章目录
操作环境
- 操作系统:Ubuntu 16.04
- JDK 版本:1.8
- Hadoop 版本:Hadoop 3.1.3
- Java IDE:Eclipse
我的 Hadoop安装目录是“/usr/local/hadoop”,环境变量 HDAOOP_HOME也是这个目录,在博客中看到“/usr/local/hadoop”这样的目录或环境变量 HADOOP_HOME,请记得转换为自己的 Hadoop安装目录。
实现文件合并和去重操作
对于两个输入文件,即文件 A 和文件 B,请编写 MapReduce 程序,对两个文件进行合并, 并剔除其中重复的内容,得到一个新的输出文件 C。
输入文件A 样例
hadoop
spark
flink
storm
s4
pig
hive
hbase
spark
sql
输入文件B 样例
model
view
controller
hadoop
spark
合并去重之后的输出文件C 样例如下
controller
flink
hadoop
hbase
hive
model
pig
s4
spark
sql
storm
view
我们先在 home目录下建立两个文件 A.txt、B.txt,并把样例内容输入进去。在之后的步骤中我们再上传这两个文件到 HDFS中。
新建项目
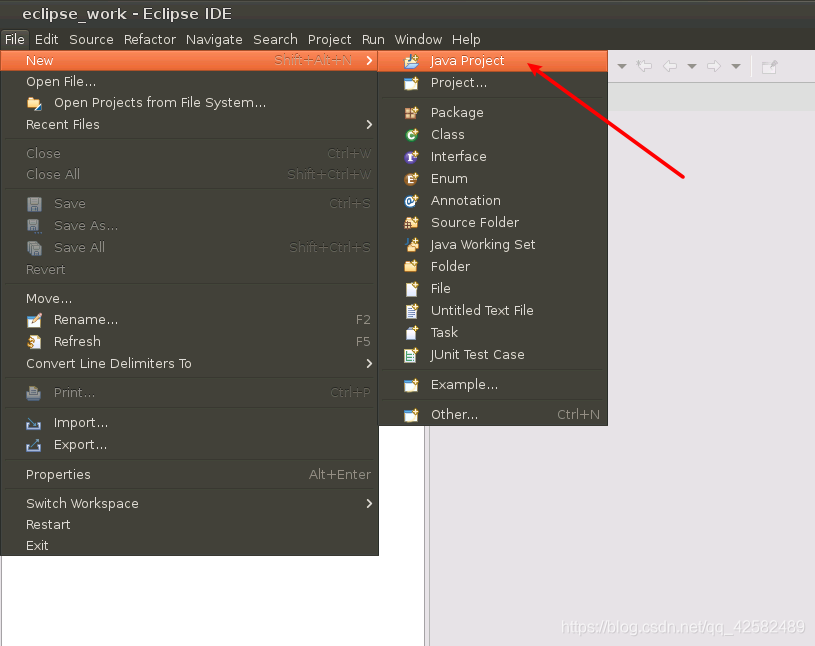
我们启动 Eclipse,在菜单栏选择 “File”->“New”->“Java Project”,创建一个新的 Java项目。
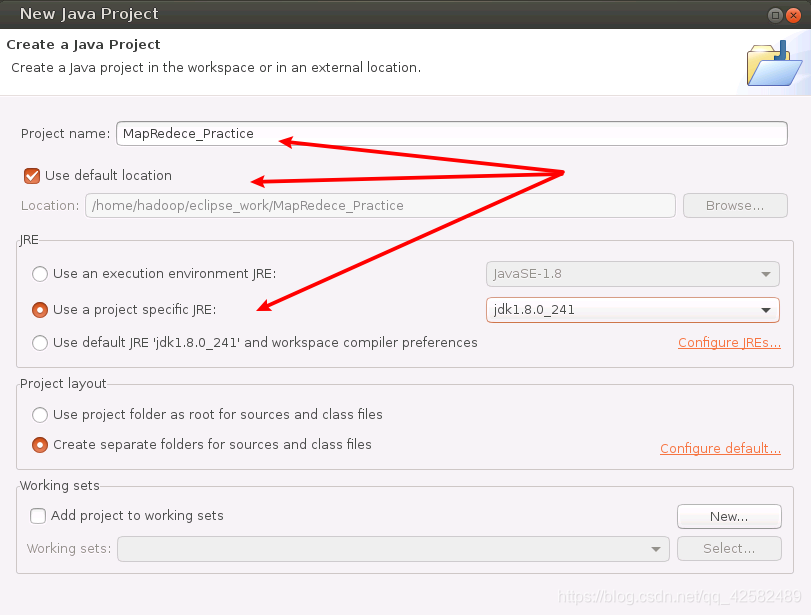
在“Project name”中输入工程名称,这里我们就叫“MapReduce_Practice”。勾选“Use defaul locationt”,让工程文件保存在我们设置的 Eclipse的工作区里。JRE部分选择“Use a project specific JRE”,使用我们自己安装的 JDK版本。然后点击“next”,进入下一步。
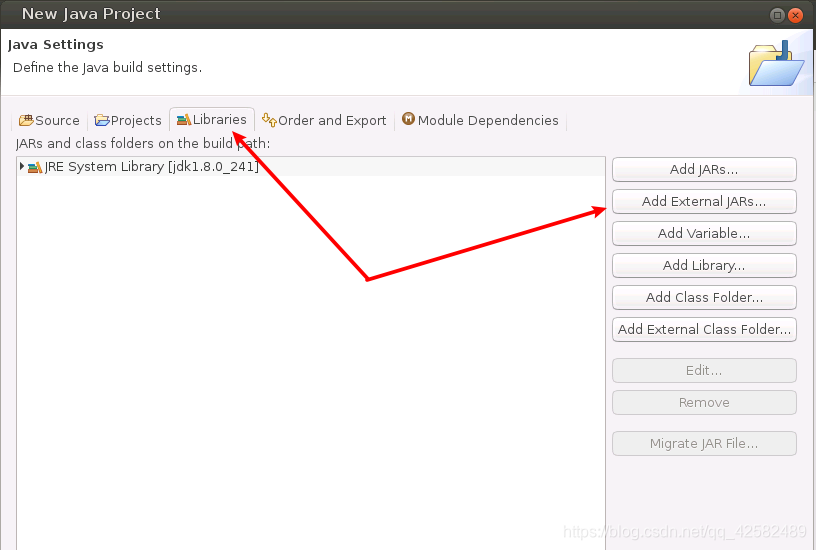
我们需要为项目导入必要的 JAR包,这些 JAR包中包含了可以访问 MapReduce的 Java API。JAR包的位置在“Hadoop安装目录/share/hadoop”目录下。比如我的是在“/usr/local/hadoop/share/hadoop”目录下,下面的操作中请选择到自己配置的 hadoop目录下导入 JAR包。
我们点击标题栏的“Libraries”,点击“Add Externtal JARs”
在新的弹窗中,我们通过选择上面的文件目录,进入“/usr/local/hadoop/share/hadoop”目录,记住是进入自己的Hadoop安装目录。
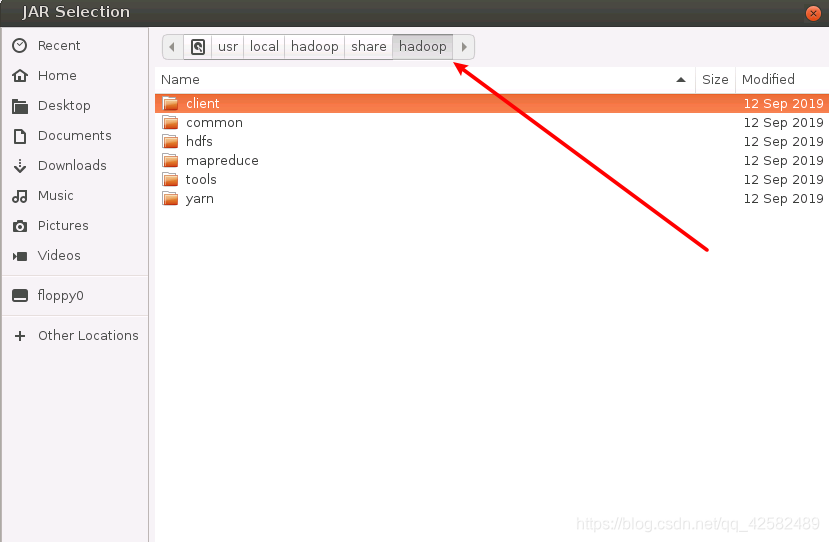
我们需要向 Java工程中添加以下 JAR包:
- “/usr/local/hadoop/share/hadoop/common”目录下的所有 JAR包,即 hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar和、haoop-kms-3.1.3.jar,不包括 jdiff、lib、sources、webapps四个文件夹。
- “/usr/local/hadoop/share/hadoop/common/lib”目录下的所有 JAR包
- “/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有 JAR包。同样地,不包括 jdiff、lib、sources、webapps四个文件夹。
- “/usr/local/hadoop/share/hadoop/mapreduce/lib”目录下的所有 JAR包
我们分四次操作,把需要的 JAR包全部导入进来(lib目录下的 JAR包太多,我们可以使用 Ctrl+A快捷键进行全选)。所需的 JAR包全部添加完毕以后,我们点击右下角的“Finish”,完成 Java工程的创建。
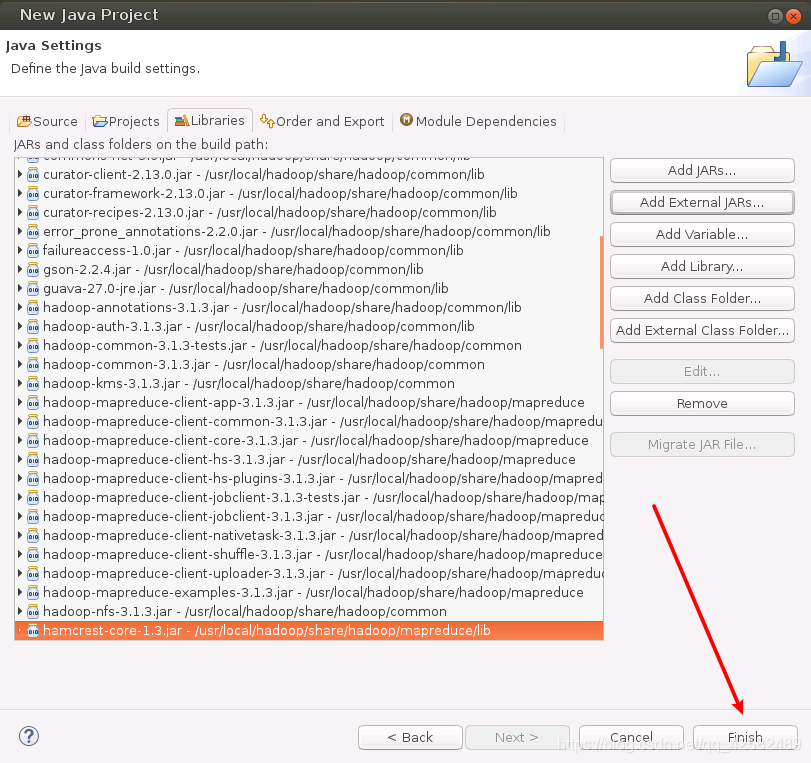
新建Java程序
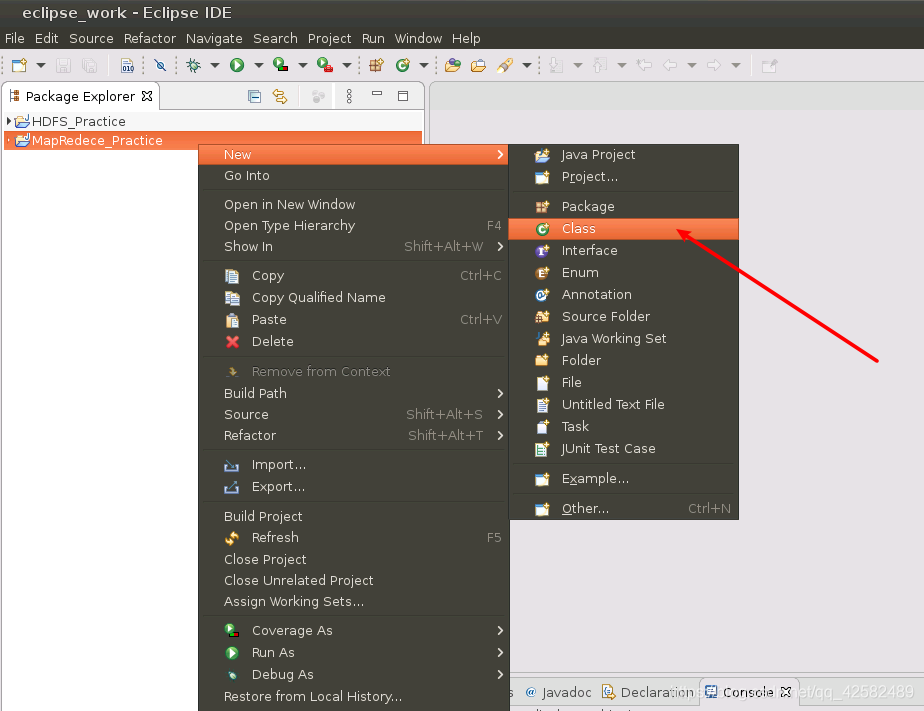
我们开始新建一个 Java程序,在 Eclipse界面左侧找到我们刚才创建的项目,点击鼠标右键,选择“New”->“Class”。
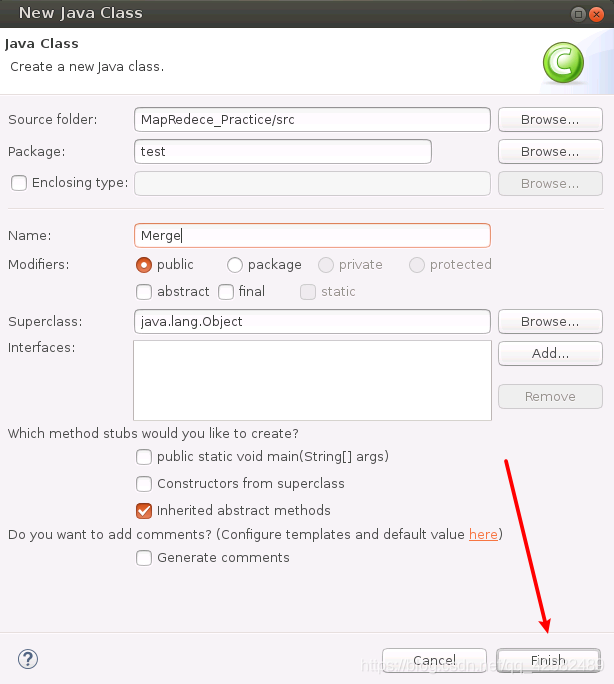
在“Package”中填入包名,这里我们填“test”。在“Name”中输入程序的名字,这里我们就叫“Merge”。其他的设置都保持默认,点击“finish”。
界面如下
接下来,我们就开始编写实现文件合并和去重操作的 MapReduce程序了。
这个程序比较简单,就分为 Map和 Reduce两步。
- 在 Map中,直接记录每一个单词即可,将输入中的 value复制到输出数据的 key上。
- 在 Reduce中更简单,直接根据 key来划分的,相同的 key放在一起,将输入中的 key复制到输出数据的 key上,写一次 context即可。
package test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Merge {
/*对A,B两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C*/
//重载map函数
public static class Map extends Mapper<Object, Text, Text, Text>{
private static Text text = new Text();
public void map(Object key, Text value, Context context)throws IOException,InterruptedException{
text = value;
context.write(text, new Text(""));
}
}
//重载reduce函数
public static class Reduce extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values, Context context)throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
System.setProperty("HADOOP_USER_NAME", "hadoop");
String[] otherArgs = new String[] {"input", "output"};
if(otherArgs.length != 2) {
System.err.println("Usage: Merge <in> <out>");
System.exit(2);
}
try {
Job job = Job.getInstance(conf, "Merge and duplicate removal");
job.setJarByClass(Merge.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
打包程序
下面我们需要把刚才编写的 Java程序打成 JAR包,部署到 Hadoop平台上去运行。
我们在 Hadoop目录下,使用命令行创建一个 myapp目录,用来存放打好的 JAR包。
cd $HADOOP_HOME
mkdir myapp
我们回到 Eclipse,在左侧的“Package Explorer”面板中,找到我们的工程“MapReduce_Practice”,点击鼠标右键,在弹出的选项中选择“Export”。
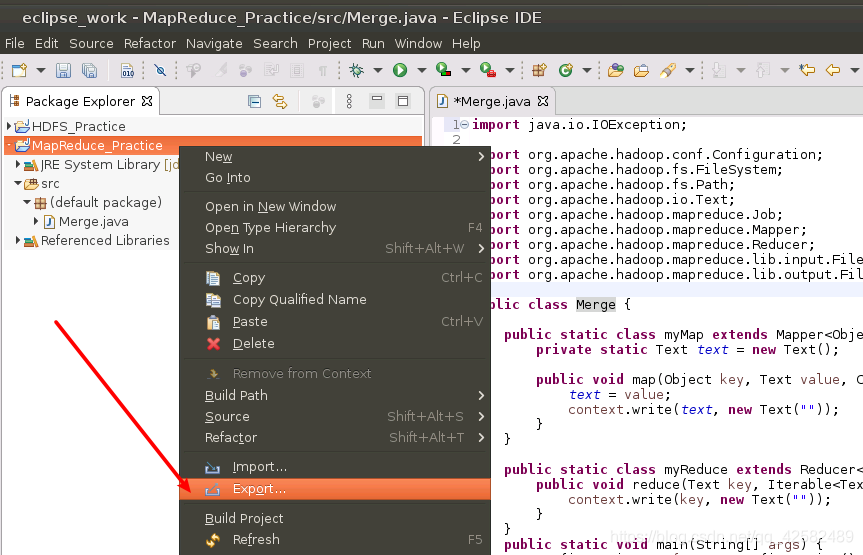
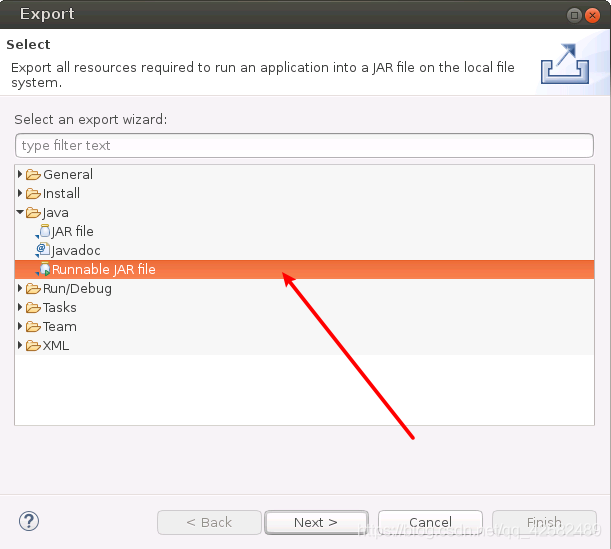
在弹出的窗口中选择“Java”->“Runnable JAR file”,点击“Next”。
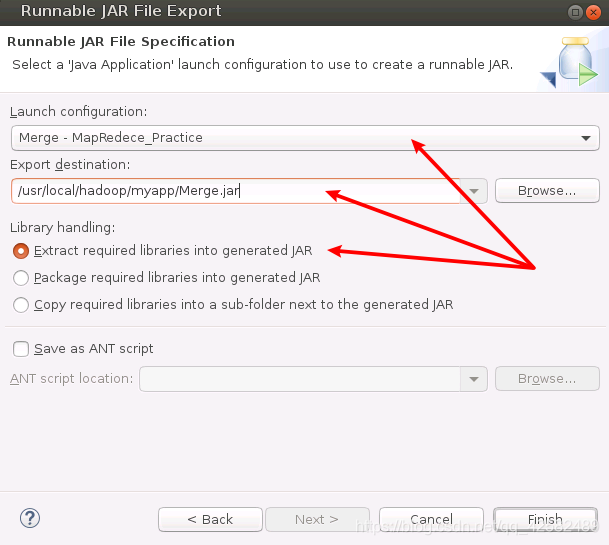
将下列三项配置完成,然后点击“Finish”。
- “Launch configuration”用于设置 JAR包被部署时运行的主类,我们需要在下拉列表中选择刚才编写的“Merge”。
- “Export destination”用于设置 JAR包保存的位置,这里我们直接就设置为刚才新建的 myapp目录,即“/usr/local/hadoop/myapp/Merge.jar”。
- “Library handling”用于设置打包的方式,我们选择“Extract required libraries into generated JAR”。
如果想知道打包方式之间的具体区别,请参考这篇博客 eclipse 导出可运行jar包时三种Library handling的区别,这里我们记住选择“Extract required libraries into generated JAR”就可以了。
点击“Finish”之后,系统会弹出警告,忽略掉即可,直接点击下方的“OK”按钮,将程序进行打包。
打包完成后,会弹出一个警告窗口进行提示,点击“OK”即可。
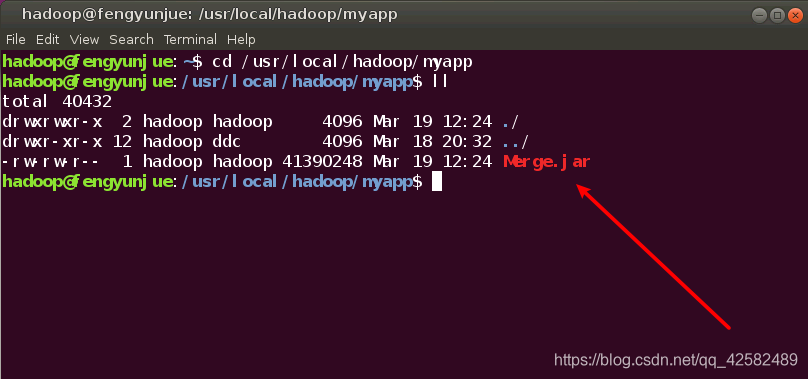
到这一步,我们已经成功把 Java程序打包为 JAR包并放置在了指定目录,我们可以在终端中进行查看。
cd /usr/local/hadoop/myapp
ll
运行程序
运行 JAR包之前,我们需要做三步准备工作。
第一步,打开 Terminal终端,用命令行启动 Hadoop进程
cd $HADOOP_HOME
./sbin/start-dfs.sh
第二步,删除用户目录下之前存在的 input、output文件夹(如果没有这两个文件夹则跳过这一步)
cd $HADOOP_HOME
./bin/hdfs dfs -rm -r input
./bin/hdfs dfs -rm -r output
第三步,在用户目录下建立 input文件夹,并将之前创建的 A.txt、B.txt文件上传到 input文件夹中
cd $HADOOP_HOME
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ~/A.txt input
./bin/hdfs dfs -put ~/B.txt input
准备工作完成后,我们就可以使用 hadoop jar来运行 JAR包了
cd $HADOOP_HOME
./bin/hadoop jar ./myapp/Merge.jar input output
记住,这里我们不需要建立 output文件夹,hadoop运行过程中会自动建立的。
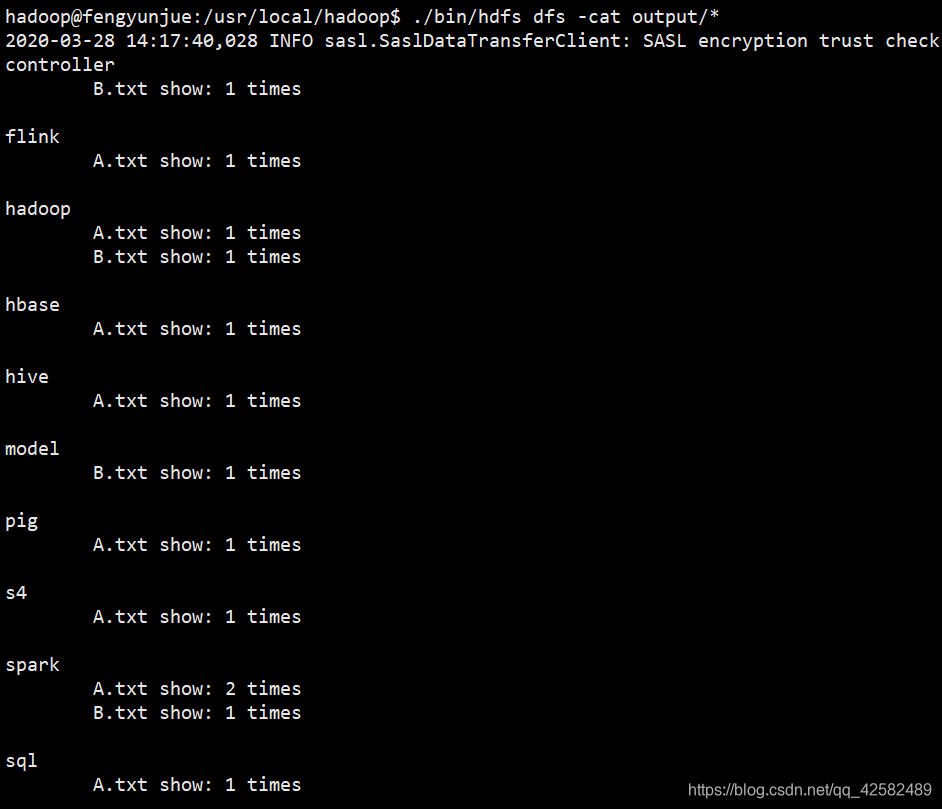
运行结束后,输入文件的合并和去重结果就写入 output文件夹中了,我们可以输入命令查看结果
./bin/hdfs dfs -cat output/*
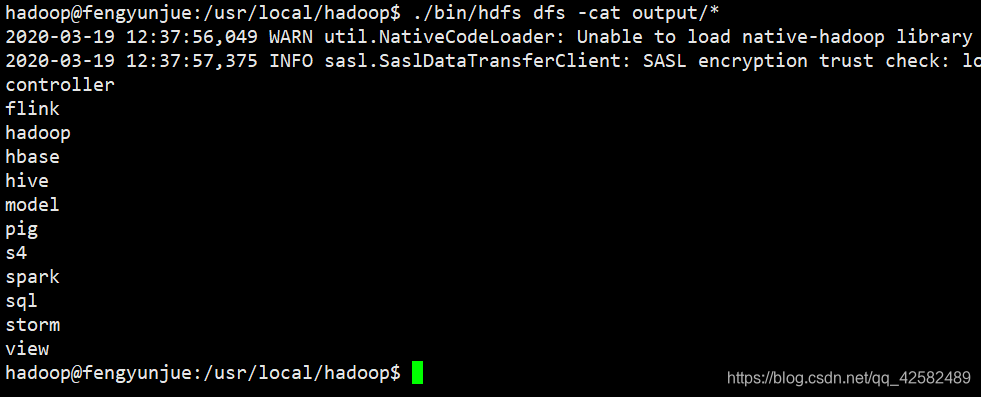
可以看到,文件的合并和去重操作顺利完成。由于 Hadoop的设定,如果要再次运行 Merge.jar程序,必须先删除 output文件夹。
实现文件的倒排索引
编写 MapReduce 程序,实现对多个输入文件的内容建立倒排索引,输出单词到文档的映射关系及单词在该文档中的出现次数。
我们建立一个新的 class,名称为 ReverseIndex,包名还是 test。这里我们主要讲解代码,具体的操作细节自行参考上面的文件合并。输入数据仍然采用 input文件夹中的 A.txt、B.txt。
这个程序比文件合并稍微复杂一些。需要记录文件名,还要统计单词在文件中出现的次数。我们分为三步进行,Map-Combiner-Reduce。
第一步,Map
因为需要输出单词到文档的映射关系及单词在该文档中的出现次数,所以我们需要获取文件的名称。在 Map中,通过 FileSplit获取文件的完整路径,切割掉最后一个“/”之前的字符,就得到了文件的名称。然后,用“–”作为连接符,将单词和文件名放在一起作为key值,value值就填为1。
public static class myMap extends Mapper<Object, Text, Text, Text>{
public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String filePath = fileSplit.getPath().toString();
String fileName = filePath.substring(filePath.lastIndexOf("/")+1);
context.write(new Text(value+"--"+fileName), new Text("1"));
}
}
第二步,Combiner
在 Combiner中进行预处理,统计单词在文件中出现的次数。将单词和文件名拆分开,word[0]是单词,word[1]是文件名。设置key值为单词,设置value值为文件名加次数。
public static class myCombiner extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException,InterruptedException{
int sum = 0;
for(Text v:values) {
sum++;
}
String[] word = key.toString().split("--");
context.write(new Text(word[0]), new Text(word[1]+" show: "+sum+" times"));
}
}
第三步,Reduce
MapReduce固定的输出格式中会在 value的开头加 tab制表符,我们需要调整一下输出格式。在 Reduce中,给 value加入适当的回车符和制表符。之前经过了 myCombiner类的预处理,可以直接输出了。key值就是单词,value值是文件名加单词次数。
public static class myReduce extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException,InterruptedException{
StringBuilder wordIndex = new StringBuilder();
for(Text v:values) {
wordIndex.append(v.toString()).append("\n\t");
}
context.write(new Text(key.toString()+"\n"), new Text(wordIndex.toString()));
}
}
配置参数
在主函数中配置必要的参数。指定 Conf配置项,设置 Job的使用类和输出类型,设置文件的输入输出路径,并使用 try-catch语句来处理异常。
这里我们有一个优化,如果文件路径下存在 output文件夹则自动删除,这样避免了每次手动删除 output文件夹的麻烦。
//指定Conf配置项
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
System.setProperty("HDAOOP_USER_NAME", "hadoop")
try {
//设置Job
Job job = Job.getInstance(conf, "ReverseIndex");
job.setJarByClass(ReverseIndex.class);
job.setMapperClass(myMap.class);
job.setCombinerClass(myCombiner.class);
job.setReducerClass(myReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置文件路径
Path input = new Path("/user/hadoop/input");
Path output = new Path("/user/hadoop/output");
//自动删除output文件夹
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)) {
fs.delete(output, true);
}
FileInputFormat.addInputPath(job, input);
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true)?0:1);
} catch (Exception e) {
e.printStackTrace();
System.exit(1);
}
总体代码
package test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReverseIndex {
public static class myMap extends Mapper<Object, Text, Text, Text>{
public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String filePath = fileSplit.getPath().toString();
String fileName = filePath.substring(filePath.lastIndexOf("/")+1);
context.write(new Text(value+"--"+fileName), new Text("1"));
}
}
public static class myCombiner extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException,InterruptedException{
int sum = 0;
for(Text v:values) {
sum++;
}
String[] word = key.toString().split("--");
context.write(new Text(word[0]), new Text(word[1]+" show: "+sum+" times"));
}
}
public static class myReduce extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException,InterruptedException{
StringBuilder wordIndex = new StringBuilder();
for(Text v:values) {
wordIndex.append(v.toString()).append("\n\t");
}
context.write(new Text(key.toString()+"\n"), new Text(wordIndex.toString()));
}
}
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
System.setProperty("HDAOOP_USER_NAME", "hadoop")
try {
Job job = Job.getInstance(conf, "ReverseIndex");
job.setJarByClass(ReverseIndex.class);
job.setMapperClass(myMap.class);
job.setCombinerClass(myCombiner.class);
job.setReducerClass(myReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path input = new Path("/user/hadoop/input");
Path output = new Path("/user/hadoop/output");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)) {
fs.delete(output, true);
}
FileInputFormat.addInputPath(job, input);
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true)?0:1);
} catch (Exception e) {
e.printStackTrace();
System.exit(1);
}
}
}
最终执行结果如下