一、简介
ROW_NUMBER、RANK、DENSE_RANK都是排名函数,在MySQL8.0以上版本中,已经支持这些函数,而8.0以下版本还未支持这些函数,这些函数到底有什么作用又有什么区别呢?我们通过SQL语句实现这些函数,并理解这些函数的作用和区别。
- ROW_NUMBER是对数据进行排序,当出现相同数值时,排序序号增加;即不存在相同排名,排名序号连续。
- RANK是跳跃排序,例如:一个第一名,两个第二名,那么接下来就是第四名;即存在相同排名,但排序序号不连续。
- DENSE_RANK是连续的排序,两个第二名仍然跟着第三名;即存在相同排名,排名序号连续。
二、创建数据
#创建score表格
#包含四列:学生编号(id),学生姓名(name),课程成绩(score)
create table soton_exercises.jscore
(id int not null auto_increment,name char(20) not null,score int, primary key(id));
#插入数据
insert into soton_exercises.jscore(name,score) values
('张三',98),
('李四',95),
('麻子',93),
('小红',75),
('王二',95),
('小强',75),
('小华',53),
('小李',48),
('小明',75);
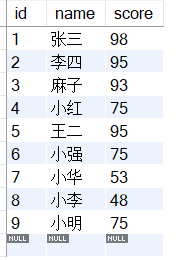
数据如下:
三、代码实现
1 ROW_NUMBER
ROW_NUMBER是对数据进行排序,当出现相同数值时,排序序号增加,不存在相同排名。
ROW_NUMBER的使用方法为:
ROW_NUMBER() OVER(PARTITION BY Colums1 ORDER BY colums2)
ROW_NUMBER实现:
select id,name,score,@currank :=@currank+1 as rank
from jscore,(select @currank :=0)q
order by score desc,id desc;
效果如下:

相同score值拥有不同排序号,排序号依次递增,不存在相同排名。
2 RANK
RANK()是跳跃排序,例如:一个第一名,两个第二名,那么接下来就是第四名,排序序号不连续。
RANK()的使用方法:
RANK() OVER(PARTITION BY colums1 ORDER BY colums2)
RANK实现:
select id,name,score,rank from
(select id,name,score,
@currank := if(@prerank=score,@currank,@incrank) as rank,
@incrank := @incrank+1,
@prerank := score
from jscore,(select @currank :=0,@prerank:=null,@incrank:=1)q
order by score desc,id desc)r;
效果如下:
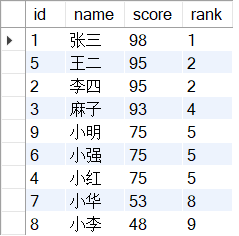
当score值相同时,排名相同,但因为两个95分,93分排名变为第4名,排名序号不连续。
3 DENSE_RANK
DENSE_RANK() 是连续的排序,两个第二名仍然跟着第三名即,即存在相同排名,排名序号连续。
DENSE_RANK() 的使用方法:
DENSE_RANK() OVER(PARTITION BY Colums1 ORDER BY colums2)
DENSE_RANK实现:
select id,name,score,rank from
(select id,name,score,
@currank := if(@prerank=score,@currank,@currank:=@currank+1) as rank,
@prerank:=score
from jscore,(select @currank :=0,@prerank:=null)q
order by score desc,id desc)r;
效果如下:
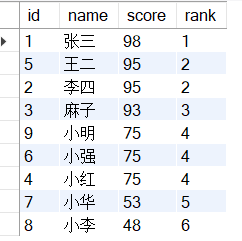
当score值相同时,排名相同,随着score值的减少,排名序号增加,但不像RANK出现序号跳跃。
4 PARTITION BY的解释
在ROW_NUMBER、RANK、DENSE_RANK的代码如下:
ROW_NUMBER() OVER(PARTITION BY Colums1 ORDER BY colums2);
RANK() OVER(PARTITION BY colums1 ORDER BY colums2);
DENSE_RANK() OVER(PARTITION BY Colums1 ORDER BY colums2);
我们知道order by columns2 是根据columns2进行排序,相当于我们例子中的order by score;但是partition by是什么呢?
partition by columns1相当于根据columns1进行区分,即把columns1的值相同的columns2的值进行排序,也就是根据columns1的值将数据分成不同的组,然后各组之内再按照columns2的值进行分开排序,不同组之间的排序只受组内columns2的值得影响,而不受其他组的影响,这一条是可选的,可以省略PARTITION BY Colums1这一句。
