python 字符串的内置方法
| 方法 | 含义 |
|---|---|
| isalnum() | 如果字符串至少有一个字符且所有字符都是字母或数字,则返回True,否则返回False |
| isalpha() | 如果字符串至少有一个字符且所有字符都是字母,则返回True,否则返回False |
| isdecimal() | 如果字符串只包含十进制数字,则返回True,否则返回False |
| isdigit() | 如果字符串只包含数字,则返回True,否则返回False |
| islower() | 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回True,否则返回False |
| isnumeric() | 如果字符串中只包含数字字符,则返回True,否则返回False |
| isspace() | 如果字符串中只包含空格,则返回True,否则返回False |
| istitle() | 如果字符串是标题化(所有单词都是大写开头,其余都是小写),则返回True,否则返回False |
| isupper() | 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写,则返回True,否则返回False |
| join(str) | 以字符串作为分隔符,插入到str中的所有字符之间 |
| ljust(len) | 返回一个左对齐的字符串,并使用空格填充至长度为len的新字符 |
| lower() | 转换字符串中所有大写字符为小写 |
| zfill(len) | 返回长度为len的字符串,原字符串右对齐,前边用0填充 |
| upper() | 转换字符串中的所有小写字符为大写 |
| translate() | 根据table的规则转换字符串中的字符 |
| title() | 返回标题化(所有单词都是以大写开头,其余都是小写)的字符串 |
| swapcase() | 翻转字符串的大小写 |
| strip([chars]) | 删除字符串前边的和后边所有空格,chars参数可以定制删除的字符,可选 |
| startswith(prefix[,start[,end]]) | 检查字符串是否以prefix开头,如果是,则返回True,否则返回False。start和end参数可以指定范围检查,可选 |
| splitlines(([keepends])) | 按照’\n’分隔,返回一个包含各行作为元素的列表,如果keepends参数指定,则返回前keepends行 |
| split(sep=None,maxsplit=-1) | 不带参数默认是以空格作为分隔符切片字符串,如果maxsplit参数有设置,则仅分隔maxsplit个子字符串,返回切片后的子字符串拼接的列表 |
| rstrip() | 删除字符串末尾的空格 |
| rpartition(sub) | 类似于partition()方法,不过是从右边开始查找 |
| rjust(len) | 返回一个右对齐的字符串,并使用空格填充至长度为len的新字符串 |
| rindex(sub[,start[,end]]) | 类似于index()方法,不过是从右边开始查找 |
| rfind(sub[,start[,end]]) | |
| replace(old,new[,count]) | 把字符串中的old子字符串替换成new子字符串,如果count指定,则替换不超过count次 |
| partition(sub) | 找到子字符串sub,把字符串分成一个3元祖(pre_sub,sub,fol_sub),如果字符串中不包含sub,则返回(原字符,’’,’’) |
| lstrip() | 去掉字符串左边的所有空格 |
| index(sub[,start[,end]]) | 跟find方法一样,不过如果sub不在string中会产生一个异常 |
| find(sub[,start[,end]]) | 检测sub是否包含在字符串中,如果有则返回索引值,否则返回-1,start和end参数表示范围 |
| capitalize() | 把字符串的第一个字符改为大写 |
| casefold() | 把整个字符串的所有字符改为小写 |
| count(sub[,start[,end]]) | 返回sub在字符串里边出现的次数,start和end参数表示范围 |
| center(len) | 将字符串居中,并使用空格填充至长度为len的新字符串 |
| encode(encoding=‘utf-8’) | 用encoding指定的编码格式对字符串进行编码 |
| endswith(sub[,start[,end]]) | 检查字符串是否以sub子字符串结束,如果是,返回True,否则返回False,start和end参数表示范围 |
| expandtabs([tabsize=8]) | 把字符串的tab符号(\t)转换为空格,如不指定参数,默认的空格数是tabsize=8 |
例子:
print(''.isalnum())
print('123'.isalnum())
print('123_'.isalnum())
print('abc'.isalnum())
print('abc_'.isalnum())

print(''.isalpha())
print('abd'.isalpha())
print('abd_'.isalpha())
print('123'.isalpha())

print('123'.isdecimal())
print('1230x64'.isdecimal())

print('123'.isdigit())
print('1230x64'.isdigit())
print(' '.isdigit())

print('axcd'.islower())
print('Axcd'.islower())

print('1232124'.isnumeric())
print('1232124 '.isnumeric())
print('csdn'.isnumeric())
print('<$-$>'.isnumeric())

print(' '.isspace())
print(''.isspace())

print('Python Java C'.istitle())
print('PYthon Java C'.istitle())
print('python java c'.istitle())

print('CSDN'.isupper())
print('CSDn'.isupper())
print('csdn'.isupper())

print('_'.join('CSDN'))

print('$-$'.ljust(6))
print('$-$'.rjust(6))
print('CSDN'.lower())
print('CSDn'.lower())

print('CSDN'.zfill(6))
print('csdn'.upper())
print('Csdn'.upper())

print('python java c mpsql'.title())
print('CsDn_cSdN'.swapcase())
print(' CSDN '.strip())
print('CSDN'.strip('C'))
print('CSDN'.strip('N'))

print('CSDN_csdn'.startswith('cs'))
print('CSDN_csdn'.startswith('cs',5))
print('CSDN_csdn'.startswith('cs',4))
print('CSDN\ncsdn\ncs'.splitlines())
print('CSDN\ncsdn\ncs'.split('\n'))
print('CSDN csdn cs'.split())

print('CSDN_csdn'.partition('cs'))
print('CSDN_CSdn'.partition('cs'))
print('CSDN_csdn'.rpartition('cs'))
print('CSDN_CSdn'.rpartition('cs'))

print('csdn_CSDN'.replace('csdn','CsDn'))
print('csdn_CSDN_csdn'.find('CSDN'))
print('csdn_CSDN_csdn'.rfind('csdn'))
print('csdn_CSDN_csdn'.find('abc'))
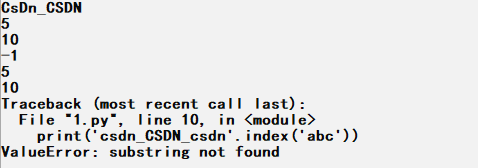
print('csdn_CSDN_csdn'.index('CSDN'))
print('csdn_CSDN_csdn'.rindex('csdn'))
print('csdn_CSDN_csdn'.index('abc'))
print('csdn_CSDN'.capitalize())
print('csdn_CSDN'.casefold())
print('cs_cs_cs'.count('cs'))
print('cs_cs_cs'.count('ab'))
print('cs_cs_cs'.count('cs',3,5))
print('cs_cs_cs'.count('cs',3))

