一. Algorithm
本周做了82、83 两道题目。 83.
Remove Duplicates from Sorted List , 一道简单的有序链表元素去重。
基本思路就是遍历整个链表,然后对每一个 Node 的 valu 进行判断。因为是有序的,所以只要判断当前 Node 的 val 是否等于结果集中最后一个 node 的 val 即可。
每次执行都要有两次判断操作,其时间复杂度是 O(n)。运行结果在 1ms 之内,看统计大部分时间都在 0 ~ 2ms 之内完成,应该是没啥难度,大家实现都差不多吧。
public class Solution {
public ListNode deleteDuplicates(ListNode head) {
if (head == null) {
return head;
}
ListNode result = new ListNode(head.val);
ListNode tailNode = result;
while (head.next != null) {
head = head.next;
if (head.val != tailNode.val) {
ListNode nextNode = new ListNode((head.val));
tailNode.next = nextNode;
tailNode = nextNode;
}
}
return result;
}
public static void main(String[] args) {
}
}
第二道题是
82.
Remove Duplicates from Sorted List II, 是上一道题的改进版,要求得出的结果中的元素都是在原链表中只出现过一次的元素。
开始思路是,遍历整个链表,拿到所有无重复的 val,然后通过 val 列表构建新的链表。
public ListNode deleteDuplicates(ListNode head) {
if (head == null) {
return head;
}
ArrayList<Integer> valList = new ArrayList<>();
valList.add(head.val);
ArrayList<Integer> duplicatesVals = new ArrayList<>();
while (head.next != null) {
head = head.next;
if (valList.contains(head.val)) {
int index = valList.indexOf(head.val);
valList.remove(index);
duplicatesVals.add(head.val);
continue;
}else {
if (!duplicatesVals.contains(head.val)) {
valList.add(head.val);
}
}
}
if (valList.size() == 0) {
return null;
}
ListNode result = new ListNode(valList.get(0));
ListNode tailNode = result;
int len = valList.size();
for (int i = 1; i < len; i ++) {
ListNode node = new ListNode(valList.get(i));
tailNode.next = node;
tailNode = node;
}
return result;
}
开始的思路是,构建一个未重复值列表和一个重复值列表,如果链表中的某个 val 已经存在于重复值列表中就不添加进 未重复值列表,已经添加到重复值列表中的值会被移除。但这样做性能不好。改进一版后去掉了对于值列表的操作与判断,直接对链表中的 Node 与前后 Node 作 val 的比较,这样节省了对重复值列表和未重复值列表的操作,性能提高到了 1ms。代码如下:
public class Solution {
public ListNode deleteDuplicates(ListNode head) {
if (head == null) {
return head;
}
ArrayList<Integer> vals = new ArrayList<>();
if (head.next != null) {
if (head.val != head.next.val) {
vals.add(head.val);
}
}else {
vals.add(head.val);
return this.buildListNodeByList(vals);
}
int preVal = head.val;
while (head.next != null) {
ListNode next = head.next;
if (next.val != preVal) {
if (next.next == null || next.next.val != next.val) {
vals.add(next.val);
}
}
head = head.next;
preVal = next.val;
}
return this.buildListNodeByList(vals);
}
public ListNode buildListNodeByList(List<Integer> list) {
if (list.size() == 0) {
return null;
}
ListNode result = new ListNode(list.get(0));
ListNode tailNode = result;
int len = list.size();
for (int i = 1; i < len; i ++) {
ListNode node = new ListNode(list.get(i));
tailNode.next = node;
tailNode = node;
}
return result;
}
}
最主要的改变是在查找无重复元素的操作上,根据前后 Node 值进行判断。
二. Review
本周读了耗子哥专栏中推荐的 Docker Best Practice。简要总结如下:
镜像相关
- 对于镜像,尽可能的减少层数;我们知道每执行一次 RUN 命令都会构建新的一层,可以将命令合并到一个 RUN 中执行
- 通过 ARG 声明版本变量
- 运行时的环境变量声明,可以在 RUN 指令中执行 export 用于创建临时环境变量
- 使用标签指明版本
容器安全
- 不要使用非官方的镜像
- 不要执行不是自己编译的二进制文件
- 以只读模式启动镜像 docker run --read-only …
以上是自己简要整理的几点,最近开始针对 Docker 进行学习,一些地方看的还不是很理解,等学习一段时间后在回来复习一遍,应该会有更深的理解。
三. Tip
Django 查看 ORM 执行的 SQL
Django 框架最值得使用的地方应该就是它自带的 ORM 设计了,使用它可以很方便的执行数据库操作,但有时候需要针对某个数据库操作进行优化,这时候需要知道其具体的执行语句,此时其提供了 query 字段进行查看, 示例如下:
query = User.objects.all().filter(gender=1).query
In [6]: query = Order.objects.all().filter(status=1).query
In [7]: str(query)
Out[7]: 'SELECT `order`.`id`, `order`.`shop_id`,
FROM `order` WHERE `order`.`status` = 1 '
四. Share
最近读吴军老师出的 《见识》这本书,里面提到了一个 伪工作者 的概念,指的是:
每天看似忙碌,实则只是应对事务性工作(虽然存在,但对实际发展没有多大效果的工作)。
当自己没有对工作的重要程度、对公司发展的影响想清楚的时候,很容易陷入 “伪工作” 的状态,觉得一天到晚很忙,但最重要的事情却没有完成,还容易陷入一种自我觉得非常努力工作的情境。
将 “伪工作者” 概念延展开来,就是将时间浪费在不必要的事情上的场景。这样的例子在生活中比比皆是。可刷可不刷的朋友圈微博、可看可不看的群聊、各种八卦,都在撕扯着我们的时间。
对于自己而言,感受更深的是伪学习状态。最近一年因为各种知识付费的兴起,得到、蚂蚁私塾甚至是极客时间,各种各样的付费学习栏目不断出现,不断告诫你如果你不学习这个专栏仿佛就要落伍了。自己有一段时间因为这个陷入了一种极度焦虑的状态,不断的购买新的专栏(光极客时间专栏买了 19 个 o(╯□╰)o),不断阅读,但因为学习内容的增多,反而导致思考的时间变少,并且因为要看的东西增多,导致有一种时间压力摆在那,如果 20 分钟不把这个专栏的文章看完就没时间看下一个了。贪多嚼不烂,每天觉得看了很多内容,但实际内化掌握的内容寥寥无几。这种感觉又反过来加深了焦虑感,严重打乱了自己个工作学习节奏。)最近一个月因为这种焦虑状态连 ARTS 都没有保证按时完成= = )
最近在反思这个问题,与其焦虑、水过地皮湿使得自己整个陷入焦虑并且伪学习的状态,倒不如减少目标,专注于某个焦点集中精力的一个个去攻克。比如做好每周的 ARTS,哪怕一周一看一篇技术文章,将这篇文章彻底的搞明白反而比粗略的浏览十篇文章要强。
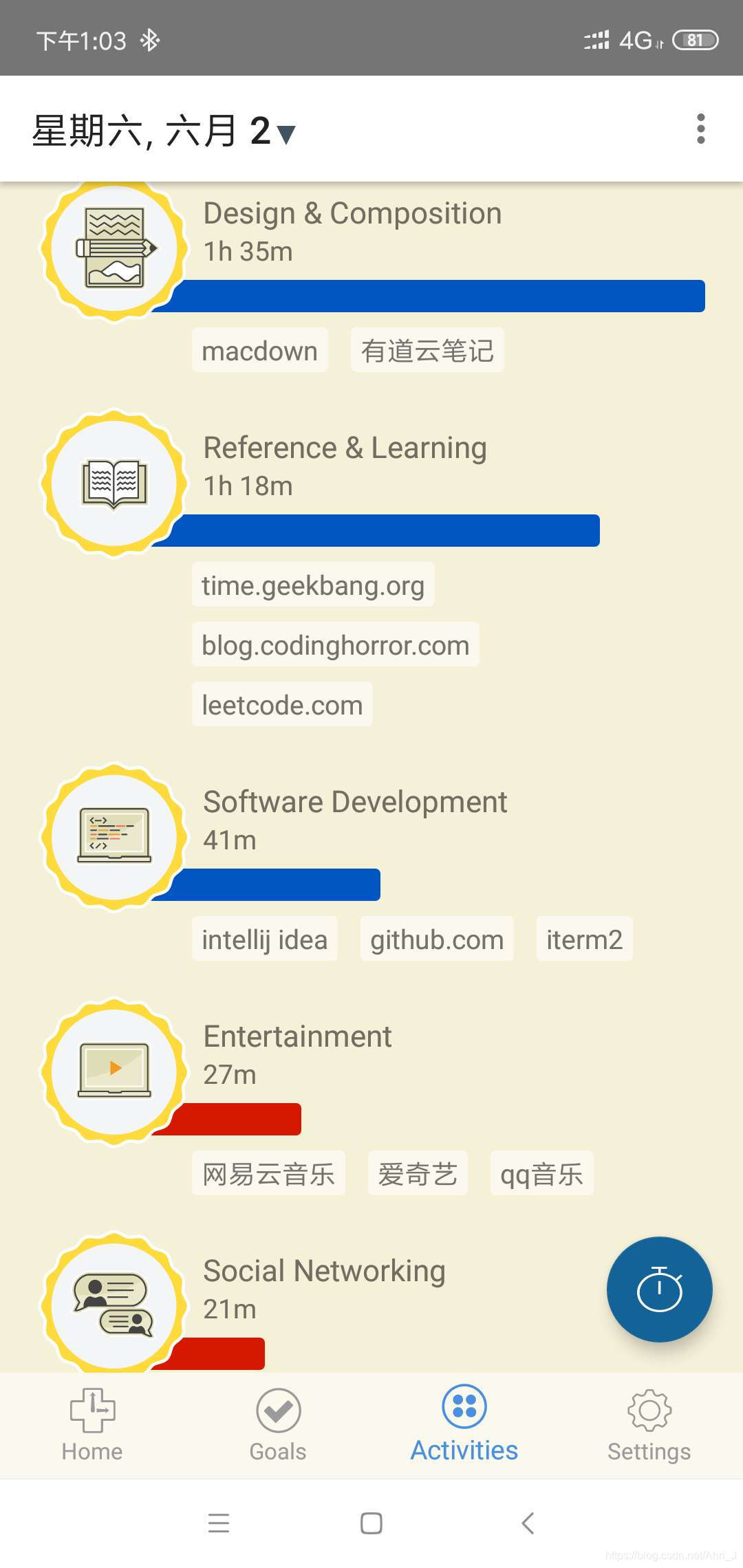
另外分析一个记录时间的软件 RescueTime。各端都有对应的客户端软件,可以精确记录每天在各个应用、网页上的使用时间。通过这个加上不使用电子设备时的自主记录,可以比较精确的统计自己每天、周、月在时间上的花费。下面是手机上的一个截图