Hadoop大数据学习–Hadoop3.1.3理论学习与搭建–实战精华帖
前言:
很多网友私信我,说想看我更新Hadoop,说官网都不说人话,初学者文档看不懂,今天,我们以白话视角看待Hadoop,通俗易懂,剑指Hadoop3.1.3,以白话文说大数据,以开源为精神,为更多想学习Hadoop的人,提供便利。
为什么要学习Hadoop
可以这么说,整个大数据的所有框架,Hadoop是最重要的,为什么呢,今天是要你想学大数据,Hadoop可以说,是必经之路,因为所有的框架如:Hive,Flume,Kafka,HBase,Spark,Flink等等都是基于Hadoop来玩转,它就像是盖楼的地基,有人说它是一个大型生态圈,我把它理解为JAVA中的大型装饰者模式,所有的框架都是在给它添砖加瓦,来增加它更加强大的功能,比如Hive,Spark,Flink加强了它的查询计算功能,HBase增加了存储功能,Flume,Kafka增加了传输功能,今天,我们以一个深刻的视角来看待它,来学习它是没毛病的,今天给大家带来的版本是Hadoop3.1.3,很多人说,太新了,但是我们要意识到,2.x.x都几年了,3.几的版本时代马上到来,我们也应该与时俱进了,可以说,和2.x.x没什么太大区别,多少还是有的,今天先带大家先入个门。总得先认识认识它们,知道他们都是干嘛的,我们后面才好学习。
Hadoop是什么
1.Hadoop是由Apache基金会开发的分布式基础架构
2.作用:主要解决海量数据存储,海量计算。
3.也是一个大型生态圈,让其他大型框架丰富它的功能,让它变的更强大
Hadoop版本
这个作为了解,Apache大厂用的多,毕竟时原生,CDH小厂用的多,维护起来比较好维护,剩下那一个作为了解。
1.Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
2.Cloudera Hadoop 简称CDH
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
3.Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
Hadoop特性
高可靠性:Hadoop底层维护多个数据副本,数据不会轻易丢失
高扩展性:说白了,就是可以搭建数以千计的Hadoop集群节点,这里说的节点,完全可以理解成一台服务器。
高效性:受MR(MapReduce)影响,加快任务处理,这里的MR,后面会说
高容错:说白了,任务没执行成功,好,我再来一遍。
Hadoop组成
首先,我们今天的目的明确,就是先了解Hadoop,必须了解它,我们后面会深入讲解,今天就是让大家有个概念,而且通俗易懂,哪里不会,下面留言。
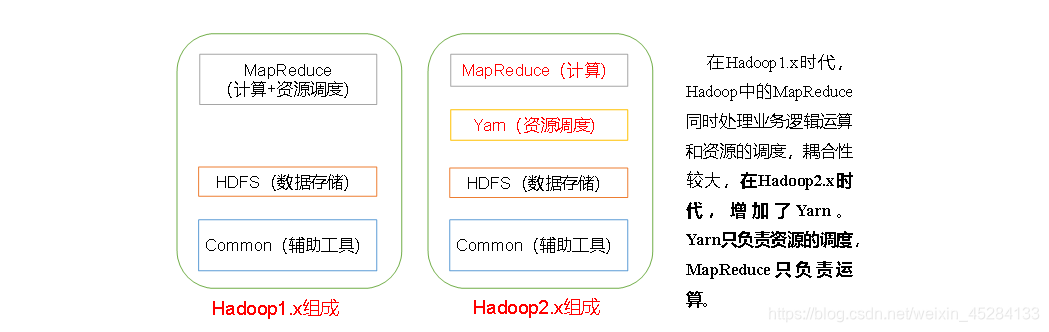
上面我们提到的MR(Mapreduce),在这里出现了,它时干嘛的呢,在整个Hadoop的里面它时负责计算的。
1.x.x版本计算和资源调度都是由MR来负责,而2.x.x版本,出了个Yarn,把资源调度分离出来,这样减少了MR的负荷,让它可以更专心的去做计算的活儿,提高效率,那么问题来了,我们3.x.x有什么新特性呢?有,而且很大,就是HA,我们后面慢慢讲它到底干嘛的。
Hadoop组成—HDFS架构
Hadoop中HDFS到底干嘛的,答:存数据的。HDFS中主要包含三大块NameNode,DataName,SecondaryNameNode三部分。
1. NameNode:存储文件元数据的,元数据包含了,文件名,文件目录结构,文件属性,文件权限,文件和DataNode的映射关系等等,说白了,它就是记录文件在哪的
3. DataNode:在本地系统中,存储文件块数据的,说白了,它才是真正存储数据的。
4. SecondaryNameNode:帮助NameNode复活的,但是代替不了NameNode,说白了有一天NameNode坏了,它作用就出来了。
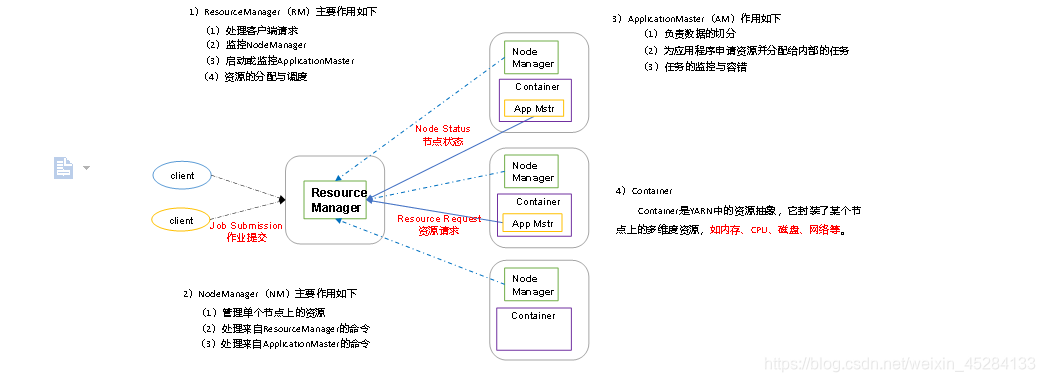
Hadoop组成—Yarn架构
Yarn
作用:负责资源调度,说白了,今天上面讲的MR处理数据呢,它处理完了得提交任务吧?告诉集群我处理完数据了,这个时候就得告诉谁?告诉Yarn,Yarn才会让它执行任务,执行完了,数据才会真正的处理,算和处理两码事,MR负责算,算完了,Yarn提供环境什么内存啊,CPU等等,让MR任务上来跑一圈,看看处理结果对不对。就这么点事儿。
Hadoop组成—MR(MapReduce)架构
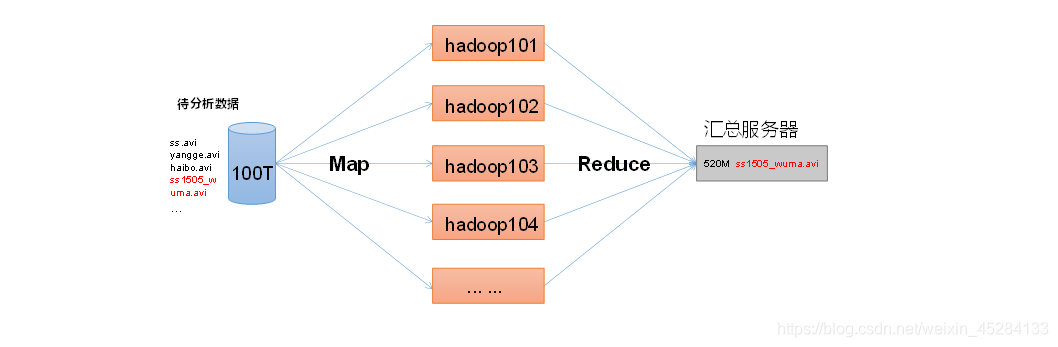
MR将计算分为两个阶段:Map一个阶段,Reduce一个阶段
Map:主要负责并行处理输入数据
Reduce:主要负责对Map阶段数据结果进行汇总
Hadoop-----生态圈成员
看到这里别懵,上面讲的什么MR,HDFS,Yarn都是Hadoop里面的儿子闺女,底下展示的,你可以理解成都是Hadoop兄弟,都是丰富Hadoop的东西,这个慢慢熟悉,这些框架的运用,我会持续更新,希望大家能一点一点认识他们
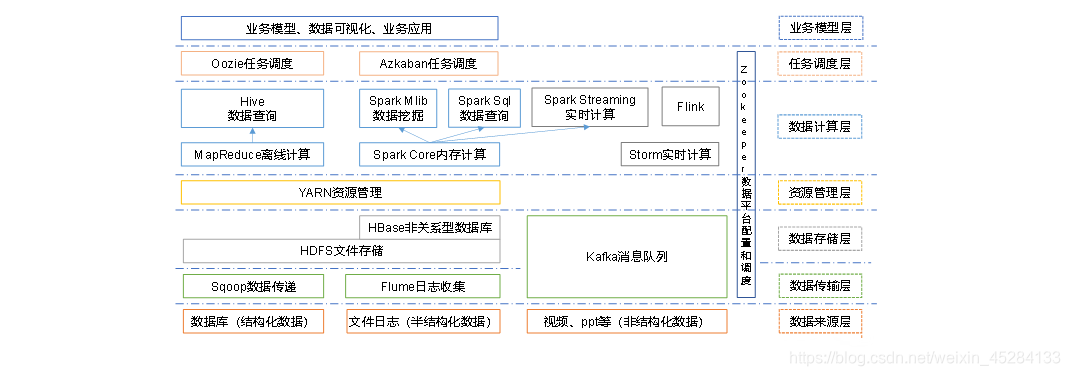
图中涉及技术名词解释如下:
Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一
关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
HBase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Zookeeper(zk):它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
Hadoop3.1.3—运行环境搭建
1.单机模式:Hadoop单机能不能玩,能玩,差很多意思,毕竟Hadoop是分布式玩起来才像那么回事,这里单机模式作为了解,也作为今天,我们的测试。看看Hadoop到底能不能用。
2.伪分布式:Hadoop伪分布式怎么回事,说白了,就是在一台机子上配置很多节点,拿一台机器当集群那么干。
3.完全分布式:这个才是重点,以前看博客上搭建,第一步骤不细致,要么就是复制粘贴过来,第二步骤不对,我们后面讲解,完全分布式,而且是高效搭建,什么叫高效,就是能用一步解决的事儿我们绝对不用第二步。充分达到稳准狠。
前期工作自己准备一下,不会可以看我前几篇文章,有教怎么配置虚拟机
1.准备一台干净的虚拟机,要求能连上XShell的,IP地址配置好,防火墙关闭!!重点是主机映射配置好,这样你克隆过去之后,就不用一台一台的配置了

2.克隆三台虚拟机,将IP更改
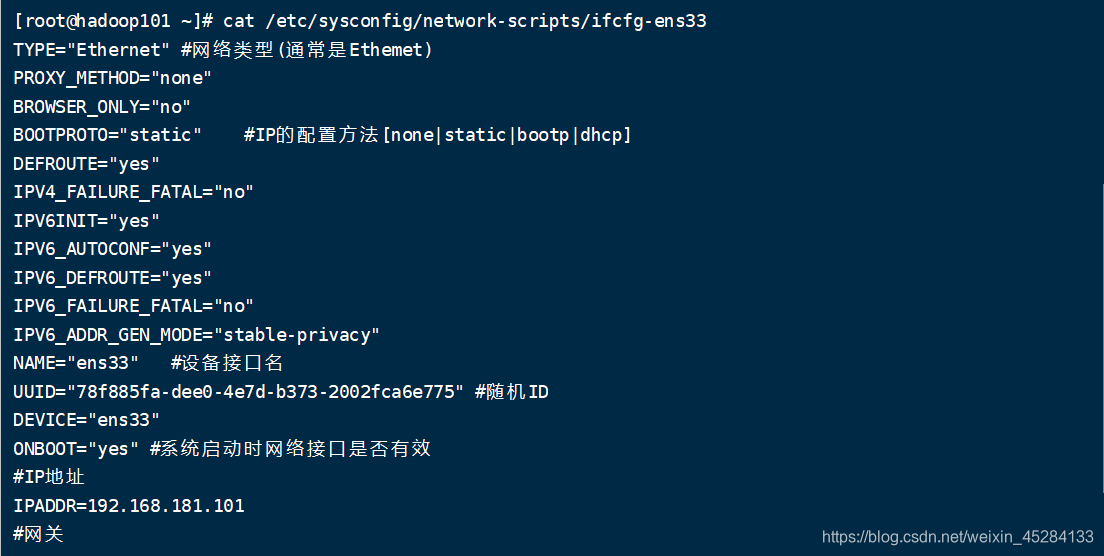
更改主机名

3.克隆虚拟机要求配置:内存4G,硬盘50G,安装必要环境(最小化安装),图形化也可以都行,最小化容易出一些乱七八招的问题
4.)修改window10的主机映射文件(hosts文件)

进入hosts文件,添加如下配置,ip地址自己更改一下,和自己的一样。

关闭防火墙

创建一个自己的用户
命令: sudo useradd xxx(名字自己起)
sudo passwd xxxxxx
配置xxx用户具备root权限
sudo vi /etc/sudoers
配置如下:
我的是atguigu,你们随意。

在/opt/目录下创建module,software文件夹,用于我们存放各个框架的压缩包还有存放解压后的框架包,命令是mkdir module,mkdir software

修改module,software的所有者权限命令
sudo chown 自己用户名:自己用户名 /opt/module
sudo chown 自己用户名:自己用户名 /opt/software
安装JDK,Hadoop
1.将Linux的JDK1.8安装包上传到softwart目录下,如果是CentOS7图形化界面的朋友们注意一下,看一下是不是系统已经默认安装了JDK1.8,有的话卸载掉,这个卸载我就不说了,考考大家自己解决问题的能力,要学会面向百度编程,实在不会,底下留言。Hadoop3.1.3也上传过去

2.将上传的JDK1.8还有Hadoop3.1.3解压到/opt/module文件夹下,以后我们的module就是装解压后的文件的
解压命令:tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module

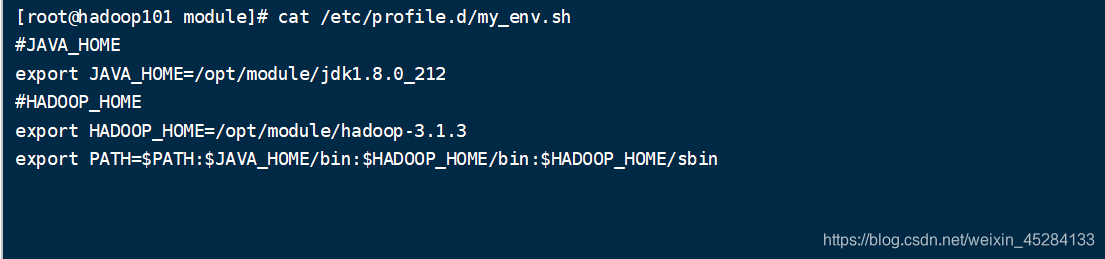
3.配置JDK还有Hadoop的环境变量,这里我们可以自己创建个文件,或者直接到profile里也行,看你们自己,我是自己创建的一个文件作演示,环境变量千万别配置错了,配置错了容易系统崩了,这里很重要,如果系统崩了,就强行用bin,然后bin进去,再更改环境变量。改好了就好了。
新建:sudo vim /etc/profile.d/my_env.sh
添加如下内容:
给你们演示一下,环境变量配置错了崩了之后什么样,千万别学!!!!!
给你们演示一下,环境变量配置错了崩了之后什么样,千万别学!!!!!
给你们演示一下,环境变量配置错了崩了之后什么样,千万别学!!!!!
就是什么都不管用了,一定要重视起来这个问题。
重启XShell,让环境变量生效
重启过后,直接输入java,javac两个命令敲回车,看一下java配置好了没,出现如下页面,就说明成功了。
直接在命令行输入Hadoop敲回车,成功了如下图
这样我们JDK和Hadoop3.1.3就安装好了,那么我们来检测一下他们是不是好用
检测JDK版本java -version

检测Hadoop最好的方法就是用一用,但是我们得先看看Hadoop的目录结构,都是干嘛的,然后我们就去用官方案例去检测,我们进入Hadoop3.1.3
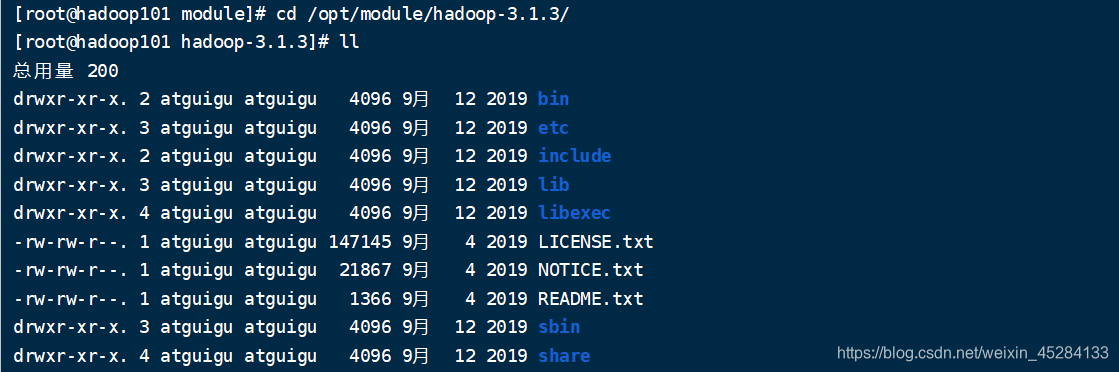
重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
官方案例WordCount
什么是WordCount,在大数据领域里,WordCount就相当于JAVA中的HelloWorld一样,这个我们肯定是要走一波的。
1.创建一个wcinput文件夹
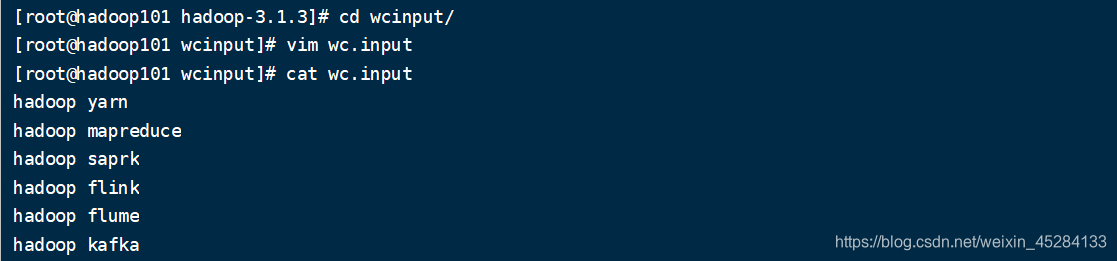
2.在wcinput文件夹下面,编辑文件wc.input,添加内容如下:
3.在Hadoop3.1.3中执行命令

命令讲解:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
hadoop:我们要启动hadoop
jar:启动hadoop中的jar包,后面接jar包路径
share中的Hadoop下的mapreduce程序中的mapreduce这个包
执行的程序名字叫wordcount,执行wxinput文件夹下的文件,执行结果记录到wcoutput文件夹中。
执行完毕了,我们去看一下wcoutput里面有没有文件,看看是否执行成功。

果然有文件,0000结尾的是文件执行完毕后的内容,而下面_SUCCESS代表的是执行成功的意思。
我们打开看一下它是不是我们之前输入的那些东西呢?
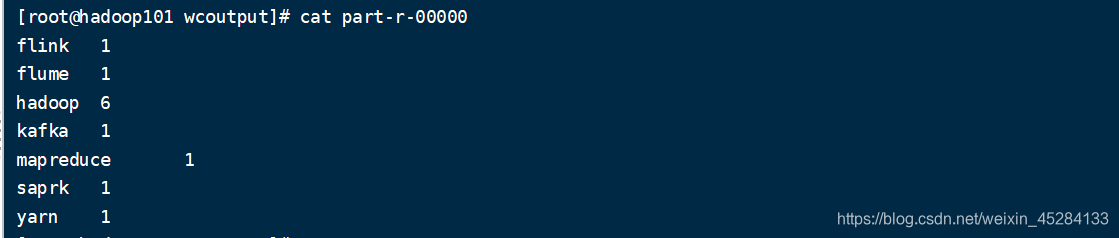
我们发现,不仅仅把我们输入的东西给呈现出来了,还帮我们算了每个单词出现了几次,证明,我们这一次,Hadoop3.1.3安装的非常成功
下一期,我们详细讲解Hadoop3.1.3的分布式集群搭建。我们下一期见。
