- 消息中间件
- 消息中间件特点
- 消息中间件的传递模型
- Kafka介绍
- 安装部署Kafka集群
- 安装Yahoo kafka manager
- kafka-manager添加kafka cluster
一、消息中间件
消息中间件是在消息的传输过程中保存消息的容器。消息中间件在将消息从消息生产者到消费者时充当中间人的作用。队列的主要目的是提供路由并保证消息的传送;如果发送消息时接收者不可用,消息对列会保留消息,直到可以成功地传递它为止,当然,消息队列保存消息也是有期限的。
二、消息中间件特点
1. 采用异步处理模式
消息发送者可以发送一个消息而无须等待响应。消息发送者将消息发送到一条虚拟的通道(主题或者队列)上,消息接收者则订阅或者监听该通道。一条消息可能最终转发给一个或多个消息接收者,这些接收者都无需对消息发送者做出同步回应。整个过程是异步的。
- 比如用户信息注册。注册完成后过段时间发送邮件或者短信。
2. 应用程序和应用程序调用关系为松耦合关系
- 发送者和接收者不必要了解对方、只需要确认消息
- 发送者和接收者不必同时在线
比如在线交易系统为了保证数据的最终一致,在支付系统处理完成后会把支付结果放到信息中间件里通知订单系统修改订单支付状态。两个系统通过消息中间件解耦。
三、消息中间件的传递模型
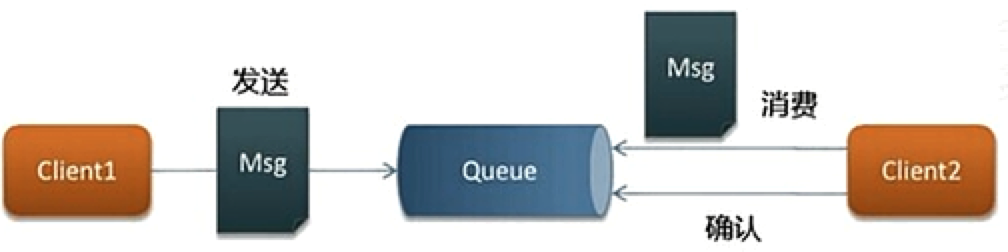
1. 点对点模型(PTP)
点对点模型用于消息生产者和消息消费者之间点对点的通信。消息生产者将消息发送到由某个名字标识的特定消费者。这个名字实际上对应于消费服务中的一个队列(Queue),在消息传递给消费者之前它被存储在这个队列中。队列消息可以放在内存中也可以是持久的,以保证在消息服务出现故障时仍然能够传递消息。
点对点模型特性:
- 每个消息只有一个消费者
- 发送者和接受者没有时间依赖
- 接受者确认消息接受和处理成功
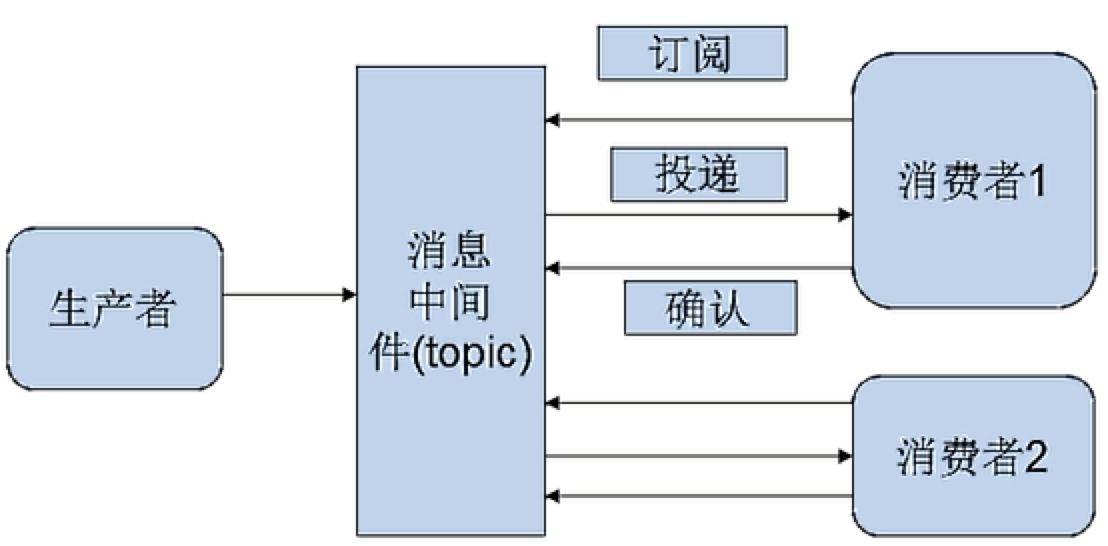
2. 发布—订阅模型(Pub/Sub)
发布者/订阅者模型支持向一个特定的消息主题生产消息。0或多个订阅者可能对接收来自特定消息主题的消息感兴趣。在这种模型下,发布者和订阅者彼此不知道对方。这种模式好比是匿名公告板。这种模式被概括为:多个消费者可以获得消息。在发布者和订阅者之间存在时间依赖性。发布者需要建立一个订阅(subscription),以便能够让消费者订阅。订阅者必须保持持续的活动状态以接收消息,除非订阅者建立了持久的订阅。在这种情况下,在订阅者未连接时发布的消息将在订阅者重新连接时重新发布。
其实消息中间件,像MySQL其实也可以作为消息中间件,只要你把消息中间件原理搞清楚,你会发现目前所有的存储,包括NoSQL,只要支持顺序性东西的,就可以作为一个消息中间件。就看你怎么去利用它了。就像redis里面那个队列list,就可以作为一个消息队列。
发布—订阅模型特性:
- 每个消息可以有多个订阅者
- 客户端只有订阅后才能接收到消息
- 持久订阅和非持久订阅
(1) 发布者和订阅者有时间依赖
接收者和发布者只有建立订阅关系才能收到消息。
(2) 持久订阅
订阅关系建立后,消息就不会消失,不管订阅者是否在线。
(3) 非持久订阅
订阅者为了接收消息,必须一直在线
当只有一个订阅者时约等于点对点模式。
大部分情况下会使用持久订阅。常用的消息队列有Kafka、RabbitMQ、ActiveMQ、metaq等。
四、Kafka介绍
Kafka是一种分布式消息系统,由LinkedIn使用Scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础,具有高水平扩展和高吞吐量。
目前越来越多的开源分布式处理系统如Apache flume、Apache Storm、Spark、Elasticsearch都支持与Kafka集成。
五、安装部署Kafka集群
1. 环境信息
| 主机名 | 操作系统版本 | IP地址 | 安装软件 |
| log1 | CentOS 7.0 | 114.55.29.86 | JDK1.7、kafka_2.11-0.9.0.1 |
| log2 | CentOS 7.0 | 114.55.29.241 | JDK1.7、kafka_2.11-0.9.0.1 |
| log3 | CentOS 7.0 | 114.55.253.15 | JDK1.7、kafka_2.11-0.9.0.1 |
2. 安装JDK1.7
3台机器都需要安装JDK1.7。
 安装JDK7
安装JDK7
3. 安装集群
需要先安装好Zookeeper集群,见之前的文章《Zookeeper介绍及安装部署》。
(1)创建消息持久化目录
[root@log1 ~]# mkdir /kafkaLogs
(2)下载解压kafka,版本是kafka_2.11-0.9.0.1
[root@log1 local]# wget http://mirrors.cnnic.cn/apache/kafka/0.9.0.1/kafka_2.11-0.9.0.1.tgz [root@log1 local]# tar zxf kafka_2.11-0.9.0.1.tgz
(3)修改配置
[root@log1 local]# cd kafka_2.11-0.9.0.1/config/ [root@log1 config]# vim server.properties
- 修改broker.id

- 修改kafka监听地址

注意: advertised.host.name参数用来配置返回的host.name值,把这个参数配置为IP地址。这样客户端在使用java.net.InetAddress.getCanonicalHostName()获取时拿到的就是ip地址而不是主机名。
- 修改消息持久化目录

- 修改zk地址

- 添加启用删除topic配置

- 关闭自动创建topic
是否允许自动创建topic。如果设为true,那么produce,consume或者fetch metadata一个不存在的topic时,就会自动创建一个默认replication factor和partition number的topic。默认是true。
auto.create.topics.enable=false

(4)把log1的配置好的kafka拷贝到log2和log3上
[root@log1 local]# scp -rp kafka_2.11-0.9.0.1 [email protected]:/usr/local/ [root@log1 local]# scp -rp kafka_2.11-0.9.0.1 [email protected]:/usr/local/
(5)log2和log3主机上创建消息持久化目录
[root@log2 ~]# mkdir /kafkaLogs [root@log3 ~]# mkdir /kafkaLogs
(6)修改log2配置文件中的broker.id为1,log3主机的为2
[root@log2 config]# vim server.properties

4. 启动集群
log1主机启动kafka:

[root@log1 ~]# cd /usr/local/kafka_2.11-0.9.0.1/ [root@log1 kafka_2.11-0.9.0.1]# JMX_PORT=9997 bin/kafka-server-start.sh -daemon config/server.properties &
log2主机启动kafka:
[root@log2 ~]# cd /usr/local/kafka_2.11-0.9.0.1/ [root@log2 kafka_2.11-0.9.0.1]# JMX_PORT=9997 bin/kafka-server-start.sh -daemon config/server.properties &
log3主机启动kafka:
[root@log3 ~]# cd /usr/local/kafka_2.11-0.9.0.1/ [root@log3 kafka_2.11-0.9.0.1]# JMX_PORT=9997 bin/kafka-server-start.sh -daemon config/server.properties &
5. 脚本定期清理logs下的日志文件
默认kafka是按天切割日志的,而且不删除:
这里写一个简单的脚本来清理这些日志,主要是清理server.log和controller.log。

[root@log1 ~]# cd /usr/local/kafka_2.11-0.9.0.1/ [root@log1 kafka_2.11-0.9.0.1]# vim clean_kafkalog.sh #!/bin/bash ###Description:This script is used to clear kafka logs, not message file. ###Written by: jkzhao - [email protected] ###History: 2016-04-18 First release. # log file dir. logDir=/usr/local/kafka_2.11-0.9.0.1/logs # Reserved 7 files. COUNT=7 ls -t $logDir/server.log* | tail -n +$[$COUNT+1] | xargs rm -f ls -t $logDir/controller.log* | tail -n +$[$COUNT+1] | xargs rm -f ls -t $logDir/state-change.log* | tail -n +$[$COUNT+1] | xargs rm -f ls -t $logDir/log-cleaner.log* | tail -n +$[$COUNT+1] | xargs rm –f
赋予脚本执行权限:
[root@log1 kafka_2.11-0.9.0.1]# chmod +x clean_kafkalog.sh
周期性任务策略:每周日的0点0分去执行这个脚本。
[root@log1 logs]# crontab -e 0 0 * * 0 /usr/local/kafka_2.11-0.9.0.1/clean_kafkalog.sh
把清理日志的脚本拷贝到第二台和第三台主机:
[root@log1 kafka_2.11-0.9.0.1]# scp -p clean_kafkalog.sh [email protected]:/usr/local/kafka_2.11-0.9.0.1 [root@log1 kafka_2.11-0.9.0.1]# scp -p clean_kafkalog.sh [email protected]:/usr/local/kafka_2.11-0.9.0.1
6. 停止kafka命令
[root@log1 ~]# /usr/local/kafka_2.11-0.9.0.1/bin/kafka-server-stop.sh
7. 测试集群
(1)log1主机上创建一个名为test的topic
[root@log1 kafka_2.11-0.9.0.1]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
(2)log2和log3主机上利用命令行工具创建一个consumer程序
[root@log2 kafka_2.11-0.9.0.1]# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning [root@log2 kafka_2.11-0.9.0.1]# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
(3)log1主机上利用命令行工具创建一个producer程序
[root@log1 kafka_2.11-0.9.0.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
log1主机上终端输入message,然后到log2和log3主机的终端查看:


8. 创建生产环境topic
如果kafka集群是3台,我们创建一个名为business的Topic,如下:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 3 --topic business
注意:为Topic创建分区时,--partitions(分区数)最好是broker数量的整数倍,这样才能使一个Topic的分区均匀的分布在整个Kafka集群中。
9. Kafka常用命令
(1)启动kafka
nohup bin/kafka-server-start.sh config/server.properties > /dev/null 2>&1 &
(2)查看topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
(3)控制台消费
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic middleware --from-beginning
- 消息中间件
- 消息中间件特点
- 消息中间件的传递模型
- Kafka介绍
- 安装部署Kafka集群
- 安装Yahoo kafka manager
- kafka-manager添加kafka cluster
一、消息中间件
消息中间件是在消息的传输过程中保存消息的容器。消息中间件在将消息从消息生产者到消费者时充当中间人的作用。队列的主要目的是提供路由并保证消息的传送;如果发送消息时接收者不可用,消息对列会保留消息,直到可以成功地传递它为止,当然,消息队列保存消息也是有期限的。
二、消息中间件特点
1. 采用异步处理模式
消息发送者可以发送一个消息而无须等待响应。消息发送者将消息发送到一条虚拟的通道(主题或者队列)上,消息接收者则订阅或者监听该通道。一条消息可能最终转发给一个或多个消息接收者,这些接收者都无需对消息发送者做出同步回应。整个过程是异步的。
- 比如用户信息注册。注册完成后过段时间发送邮件或者短信。
2. 应用程序和应用程序调用关系为松耦合关系
- 发送者和接收者不必要了解对方、只需要确认消息
- 发送者和接收者不必同时在线
比如在线交易系统为了保证数据的最终一致,在支付系统处理完成后会把支付结果放到信息中间件里通知订单系统修改订单支付状态。两个系统通过消息中间件解耦。
三、消息中间件的传递模型
1. 点对点模型(PTP)
点对点模型用于消息生产者和消息消费者之间点对点的通信。消息生产者将消息发送到由某个名字标识的特定消费者。这个名字实际上对应于消费服务中的一个队列(Queue),在消息传递给消费者之前它被存储在这个队列中。队列消息可以放在内存中也可以是持久的,以保证在消息服务出现故障时仍然能够传递消息。
点对点模型特性:
- 每个消息只有一个消费者
- 发送者和接受者没有时间依赖
- 接受者确认消息接受和处理成功
2. 发布—订阅模型(Pub/Sub)
发布者/订阅者模型支持向一个特定的消息主题生产消息。0或多个订阅者可能对接收来自特定消息主题的消息感兴趣。在这种模型下,发布者和订阅者彼此不知道对方。这种模式好比是匿名公告板。这种模式被概括为:多个消费者可以获得消息。在发布者和订阅者之间存在时间依赖性。发布者需要建立一个订阅(subscription),以便能够让消费者订阅。订阅者必须保持持续的活动状态以接收消息,除非订阅者建立了持久的订阅。在这种情况下,在订阅者未连接时发布的消息将在订阅者重新连接时重新发布。
其实消息中间件,像MySQL其实也可以作为消息中间件,只要你把消息中间件原理搞清楚,你会发现目前所有的存储,包括NoSQL,只要支持顺序性东西的,就可以作为一个消息中间件。就看你怎么去利用它了。就像redis里面那个队列list,就可以作为一个消息队列。
发布—订阅模型特性:
- 每个消息可以有多个订阅者
- 客户端只有订阅后才能接收到消息
- 持久订阅和非持久订阅
(1) 发布者和订阅者有时间依赖
接收者和发布者只有建立订阅关系才能收到消息。
(2) 持久订阅
订阅关系建立后,消息就不会消失,不管订阅者是否在线。
(3) 非持久订阅
订阅者为了接收消息,必须一直在线
当只有一个订阅者时约等于点对点模式。
大部分情况下会使用持久订阅。常用的消息队列有Kafka、RabbitMQ、ActiveMQ、metaq等。
四、Kafka介绍
Kafka是一种分布式消息系统,由LinkedIn使用Scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础,具有高水平扩展和高吞吐量。
目前越来越多的开源分布式处理系统如Apache flume、Apache Storm、Spark、Elasticsearch都支持与Kafka集成。
五、安装部署Kafka集群
1. 环境信息
| 主机名 | 操作系统版本 | IP地址 | 安装软件 |
| log1 | CentOS 7.0 | 114.55.29.86 | JDK1.7、kafka_2.11-0.9.0.1 |
| log2 | CentOS 7.0 | 114.55.29.241 | JDK1.7、kafka_2.11-0.9.0.1 |
| log3 | CentOS 7.0 | 114.55.253.15 | JDK1.7、kafka_2.11-0.9.0.1 |
2. 安装JDK1.7
3台机器都需要安装JDK1.7。
安装JDK7
3. 安装集群
需要先安装好Zookeeper集群,见之前的文章《Zookeeper介绍及安装部署》。
(1)创建消息持久化目录
[root@log1 ~]# mkdir /kafkaLogs
(2)下载解压kafka,版本是kafka_2.11-0.9.0.1
[root@log1 local]# wget http://mirrors.cnnic.cn/apache/kafka/0.9.0.1/kafka_2.11-0.9.0.1.tgz [root@log1 local]# tar zxf kafka_2.11-0.9.0.1.tgz
(3)修改配置
[root@log1 local]# cd kafka_2.11-0.9.0.1/config/ [root@log1 config]# vim server.properties
- 修改broker.id
- 修改kafka监听地址
注意: advertised.host.name参数用来配置返回的host.name值,把这个参数配置为IP地址。这样客户端在使用java.net.InetAddress.getCanonicalHostName()获取时拿到的就是ip地址而不是主机名。
- 修改消息持久化目录
- 修改zk地址
- 添加启用删除topic配置
- 关闭自动创建topic
是否允许自动创建topic。如果设为true,那么produce,consume或者fetch metadata一个不存在的topic时,就会自动创建一个默认replication factor和partition number的topic。默认是true。
auto.create.topics.enable=false
(4)把log1的配置好的kafka拷贝到log2和log3上
[root@log1 local]# scp -rp kafka_2.11-0.9.0.1 [email protected]:/usr/local/ [root@log1 local]# scp -rp kafka_2.11-0.9.0.1 [email protected]:/usr/local/
(5)log2和log3主机上创建消息持久化目录
[root@log2 ~]# mkdir /kafkaLogs [root@log3 ~]# mkdir /kafkaLogs
(6)修改log2配置文件中的broker.id为1,log3主机的为2
[root@log2 config]# vim server.properties
4. 启动集群
log1主机启动kafka:
[root@log1 ~]# cd /usr/local/kafka_2.11-0.9.0.1/ [root@log1 kafka_2.11-0.9.0.1]# JMX_PORT=9997 bin/kafka-server-start.sh -daemon config/server.properties &
log2主机启动kafka:
[root@log2 ~]# cd /usr/local/kafka_2.11-0.9.0.1/ [root@log2 kafka_2.11-0.9.0.1]# JMX_PORT=9997 bin/kafka-server-start.sh -daemon config/server.properties &
log3主机启动kafka:
[root@log3 ~]# cd /usr/local/kafka_2.11-0.9.0.1/ [root@log3 kafka_2.11-0.9.0.1]# JMX_PORT=9997 bin/kafka-server-start.sh -daemon config/server.properties &
5. 脚本定期清理logs下的日志文件
默认kafka是按天切割日志的,而且不删除:
这里写一个简单的脚本来清理这些日志,主要是清理server.log和controller.log。
[root@log1 ~]# cd /usr/local/kafka_2.11-0.9.0.1/ [root@log1 kafka_2.11-0.9.0.1]# vim clean_kafkalog.sh #!/bin/bash ###Description:This script is used to clear kafka logs, not message file. ###Written by: jkzhao - [email protected] ###History: 2016-04-18 First release. # log file dir. logDir=/usr/local/kafka_2.11-0.9.0.1/logs # Reserved 7 files. COUNT=7 ls -t $logDir/server.log* | tail -n +$[$COUNT+1] | xargs rm -f ls -t $logDir/controller.log* | tail -n +$[$COUNT+1] | xargs rm -f ls -t $logDir/state-change.log* | tail -n +$[$COUNT+1] | xargs rm -f ls -t $logDir/log-cleaner.log* | tail -n +$[$COUNT+1] | xargs rm –f
赋予脚本执行权限:
[root@log1 kafka_2.11-0.9.0.1]# chmod +x clean_kafkalog.sh
周期性任务策略:每周日的0点0分去执行这个脚本。
[root@log1 logs]# crontab -e 0 0 * * 0 /usr/local/kafka_2.11-0.9.0.1/clean_kafkalog.sh
把清理日志的脚本拷贝到第二台和第三台主机:
[root@log1 kafka_2.11-0.9.0.1]# scp -p clean_kafkalog.sh [email protected]:/usr/local/kafka_2.11-0.9.0.1 [root@log1 kafka_2.11-0.9.0.1]# scp -p clean_kafkalog.sh [email protected]:/usr/local/kafka_2.11-0.9.0.1
6. 停止kafka命令
[root@log1 ~]# /usr/local/kafka_2.11-0.9.0.1/bin/kafka-server-stop.sh
7. 测试集群
(1)log1主机上创建一个名为test的topic
[root@log1 kafka_2.11-0.9.0.1]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
(2)log2和log3主机上利用命令行工具创建一个consumer程序
[root@log2 kafka_2.11-0.9.0.1]# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning [root@log2 kafka_2.11-0.9.0.1]# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
(3)log1主机上利用命令行工具创建一个producer程序
[root@log1 kafka_2.11-0.9.0.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
log1主机上终端输入message,然后到log2和log3主机的终端查看:
8. 创建生产环境topic
如果kafka集群是3台,我们创建一个名为business的Topic,如下:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 3 --topic business
注意:为Topic创建分区时,--partitions(分区数)最好是broker数量的整数倍,这样才能使一个Topic的分区均匀的分布在整个Kafka集群中。
9. Kafka常用命令
(1)启动kafka
nohup bin/kafka-server-start.sh config/server.properties > /dev/null 2>&1 &
(2)查看topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
(3)控制台消费
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic middleware --from-beginning