开源实现
https://github.com/shihenw/convolutional-pose-machines-release(caffe版本)
https://github.com/psycharo/cpm (tensorflow版本,但是只有用pre-trained model做predict,没有training)
论文原文下载地址:https://www.researchgate.net/publication/301880946_Convolutional_Pose_Machines
论文阅读笔记:
思路:通过关键点的连线判断四肢的方向和位置(比如,手肘,肩膀,手腕,膝盖,脚踝,臀部等14个关键点)。(但是我觉得关键点的难度应该是在人体的姿势变化大,关键点不清晰和被遮挡等问题上)
摘要:姿势识别即关键点定位技术, a sequential architecture(序列化结构。把一个网络分成几个序列化的模块)组成卷积的网络,在特征图上进行一系列的操作。解决组合序列化的模块,一旦网络过长,可能会出现梯度消失的现象,可能会杀死前面的序列的问题。将训练结果在多个数据库上进行评估。
方法:
1. 序列化网络:

详见核心和特色:sequential网络架构。
2.Keypoint Localization
第一个Stage:14个特征图,就对应14个关键点,特征图预测每个点在图像中每一个部位的概率。
3.Sequential prediction:
感受野大小9*9,26*26,60*60..........,400*400(经过卷积之后,能看到的区域越来越大,可以更好地得到上下文信息,能看到更大的感受野,就有更高的准确率)分多个stage的好处就在于加卷积的时候,感受野越来越大。
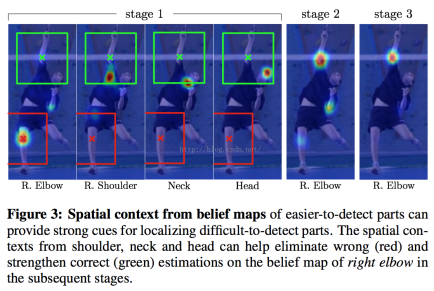
纠错:关键点之间是互相影响的,要分辨出不同的关键点,需要更大的感受野通过其他关键点信息判断关键点。
如何得到更大的感受野:
1)加更多的卷积层,网络越深,最后一层卷积层看到的越向前,获得的感受野更大。
2)增大kernel size。
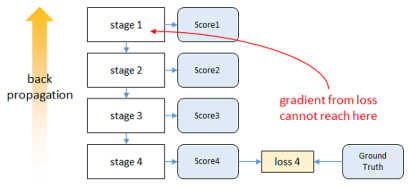
4.关于梯度下降的问题:
卷积层多了,就会出现梯度消失的问题。
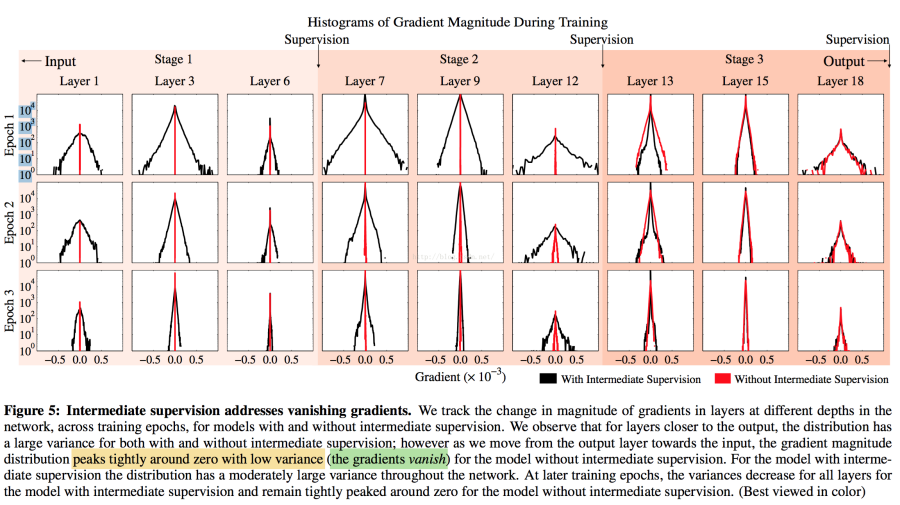
Intermediate Supervision方法:
红色是正常传,epoch是每一次迭代,传到Stage2梯度就无法再变化了。
我理解的Intermediate Supervision:每一个阶段的Stage都已经有一个结果了,得出每个Stage的Loss,Loss1,Loss2.Loss3,每一层都有一次监督,每一层都能有参数的更新。
5.训练:
1.Loss Function:

Grand Truth:一个点的坐标与标准的欧氏距离。
在每一个关键点的真实位置上,放置一个高斯响应。标定后生成label数据。
2.数据拓展:
为了丰富训练样本,对原始图片进行随机旋转缩放镜像。
论文核心思想和特色:
一.Sequential网络的架构:
1. 在每一个尺度下,计算各个部件的响应图
2. 对于每个部件,累加所有尺度的响应图,得到总响应图
3. 在每个部件的总响应图上,找出相应最大的点,为该部件位置
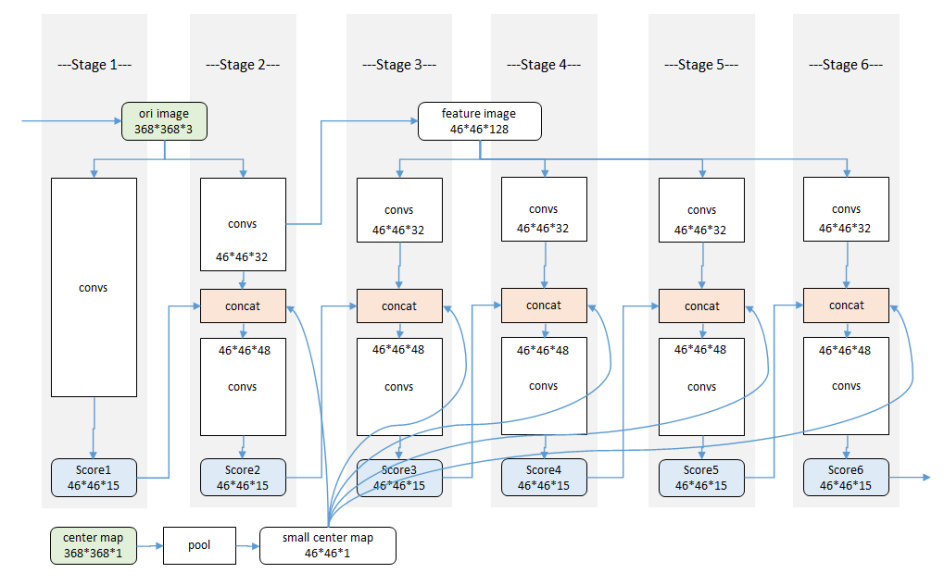
六个Stage,
第一个Stage:输入图像,经过卷积得到46*46*15(14+1,14为关键点,1为背景)的特征图。
第二个Stage:输入图像,经过卷积46*46*32(纹理特征),之后综合前一个Stage的结果进行连接。得到46*46*48(35+15+1(中心约束))之后再卷积得到,46*46*15.
第三个Stage之后:直接拿到第二个Stage的中间结果,卷积成46*46*128.分成四个46*46*32和前一个阶段性预测结果进行卷积。
Center Map:在人的周围加上一个高斯响应。Stage2之后都会有一个Center map的聚拢。提前生成的高斯函数模板,用来把响应归拢到图像中心。
二:.用各部件响应图来表达各部件之间的空间约束。
响应图和特征图一起作为数据在网络中传递。
三:中继监督: