栈帧
不再赘述。
1.局部变量分布
编译器的第一个任务是,计算出函数的局部变量所需的空间。编译器的第二个任务,则是确定这些变量是否可在CPU寄存器中分配,或者它们是否必须在程序栈上分配。 至于具体的分配方式,既与函数的调用方无关,也与被调用的函数无关。值得注意的是,通过检查函数的源代码,通常无法确定函数的局部变量布局。

使用栈指针引用栈帧变量的函数
计算得出,局部变量最少需要76字节的栈空间( 3个4字节整数和1个64字节缓冲区)。 如图6-3所示是一个用于调用demo_ stackframe的栈帧实现,假设它并没有使用帧指针寄存器(因此栈指针ESP作为帧指针)。进入demo_ stackframe时, 可以使用下面的一行“序言”配置这个栈帧:

- 上图中saved eip即为返回地址
生成利用栈指针计算所有变量引用的函数需要编译器做更多工作,因为栈指针会频繁变化,编译器必须确保它在引用栈帧中的任何变量时始终使用了正确的偏移量 。
以对demo_stackframe函数中bar的调用代码为例:

根据图6-3中的偏移量,➊处的push准确地将局部变量y压人栈中。初看起来,似乎❷处的push错误地再次引用了局部变量y。但是,因为我们处理的是一个基于ESP的帧,且➊处的push修改ESP,所以每次ESP发生改变,图6-3中的所有偏移量都会临时进行调整。于是,在➊之后,❷处的push中正确引用的局部变量z的新偏移量变为[esp+4]。在分析使用栈指针引用栈帧变量的函数时,你必须小心,注意栈指针的任何变化,并对所有未来的变量偏移量进行相应调整。使用栈指针引用所有栈帧变量的好处在于: 所有其他寄存器仍可用于其他目的。
demo_ stackframe完成后,它需要返回调用方。最终,需要使用ret指令从栈顶弹出所需返回地址,并将其插人指令指针寄存器(此时为EIP)中。在弹出返回地址之前,需要从栈项删除局部变量,以便在ret指令执行时,栈指针正确地指向所保存的返回地址。 这个特殊函数的“尾声”如下所示:

一下讲的为重点:
由于专门使用一个寄存器作为帧指针,并通过一段代码在函数入口点配置了帧指针,因此,计算局部变量偏移量的工作变得更加轻松。在x86程序中, EBP 寄存器通常专门用作帧指针。默认情况下,多数编译器会生成代码以使用帧指针,而无视规定应使用栈指针的选项。 例如,GNU gcc/g+ +提供了- fomit- frame-pointer编译器选项,可生成不依赖于固定帧指针寄存器的函数。
使用帧指针引用栈帧变量的函数:
为了解使用专用帧指针的demo_ stackframe栈帧的结构,我们以下面这段“序言”代码为例:

上述编号为③ ④ ⑤
(一下基于32位程序:)
❸处的push指令保存 当前调用方使用的EBP的值。遵循用于Intel 32位处理器的系统V应用
程序二进制接口( System V Application Binary Interface ) 的函数可以修改EAX、ECX和EDX
寄存器,但需要为所有其他寄存器保留调用方的值。因此,如果希望将EBP作为帧指针,那么,在修改它之前,必须保存EBP的当前值,并且在返回调用方时恢复调用方EBP的值。如果需要为调用方保存其他寄存器(如ESI或EDI),编译器可能会在保存EBP的同时保存这些寄存器,或者推迟保存操作,直到局部变量已经得到分配。因此,栈帧中并没有用于存储被保存寄存器的标准位置。
EBP被保存后,就可以对其进行修改,使它指向当前的栈顶位置。这由④处的mov指令来完成,它将栈指针的当前值复制到EBP中。最后,和在非基于EBP的栈帧中一样,局部变量的空间在❺处分配。得到的栈帧布局如图6-4所示。
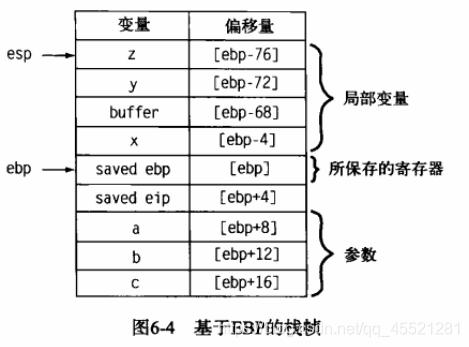
- 上图中saved eip即为返回地址
使用一个专用的帧指针,所有变量相对于帧指针寄存器的偏移量都可以很容易地计算出来(ebp不像esp那样变化)。许多时候,正偏移量用于访问函数参数,而负偏移量则用于访问局部变量。 使用专用的帧指针,我们可以自由更改栈指针,而不至影响帧内其他变量的偏移量。现在,对函数bar的调用可以按以下方式执行:

以上编号为⑥
在执行⑥处的push指令后,栈指针已经发生改变,但这不会影响到随后的push指令对局部变量z的访问。最后,函数完成其操作后,使用帧指针需要一段稍有不同的“尾声”代码,因为在返回前,必须恢复调用方的帧指针。在检索帧指针的初始值之前,必须从栈中清除局部变量。 不过,由于当前的帧指针指向最初的帧指针,这个任务可轻松完成。在使用EBP作为帧指针的x86程序中,下面的代码是一段典型的“尾声"代码:
由于这项操作十分常见,因此,x86体系结构提供了leave指令,以轻松完成这个任务。

其他处理器体系结构使用的寄存器和指令肯定会有所不同,但构建栈帧的基本过程并无明显差异。无论是何种体系结构,你都需要熟悉典型的“序言”和“尾声”代码,以便迅速开始分析函数中你更感兴趣的代码。
2.IDA 栈视图
很明显,栈帧是一个运行时概念,没有栈和运行中的程序,栈帧就不可能存在。话虽如此,但这并不意味着你在使用IDA之类的工具进行静态分析时,就可以忽略栈帧的概念。 二进制文件中包含配置每个函数的栈帧所需的全部代码。通过仔细分析这段代码,我们可以深入了解任何函数的栈帧的结构,即使这个函数并未运行。
实际上,IDA中的一些最复杂的分析,就是为了专门确定IDA反汇编的每个函数的栈帧的布局。 在初始分析过程中, IDA会记住每一项push或pop操作,以及其他任何可能改变栈指针的算术运算,如增加或减去常量,尽其所能去监控栈指针在函数执行过程中的行为。这项分析的第一个目标是确定分配给函数栈帧的局部变量区域的具体大小。 其他目标包括:确定某函数是否使用一个专用的帧指针(例如,通过识别push ebp/mov ebp. esp序列),以及识别对函数栈帧内变量的所有内存引用。例如,如果IDA在demo_ stackframe的正文中发现以下指令:

看它就知道,函数的第一个参数(此时为a )被加载到EAX寄存器中(见图6-4 )。
通过仔细分析栈帧的结构,IDA能够区分 访问函数参数 (位于被保存的返回地址之下)的内存引用及 访问局部变量 (位于被保存的返回地址之上)的引用。IDA还会采取额外的步骤,确定栈帧内的哪些内存位置被直接引用。例如,虽然图6-4中栈帧的大小为96字节,但我们只会看到7个变量(4个局部变量和3个参数)被引用。
了解函数的行为通常归结为了解该函数操纵的数据的类型。在阅读反汇编代码清单时,查看函数的栈帧细目,是你了解函数所操纵的数据的第一个机会。 IDA为任何函数栈帧都提供了两种视图:1.摘要视图 和 2.详细视图。为了解这两种视图,我们以下面使用gcc编译的demo_ stack frame函数为例:

在这个例子中,我们分别为变量x和y提供了初始值c和b,为变量z提供了初始值常量10。另外,64字节局部数组buffer的第一个字符被初始化为字母’A’。这个函数对应的IDA反汇编代码如下:
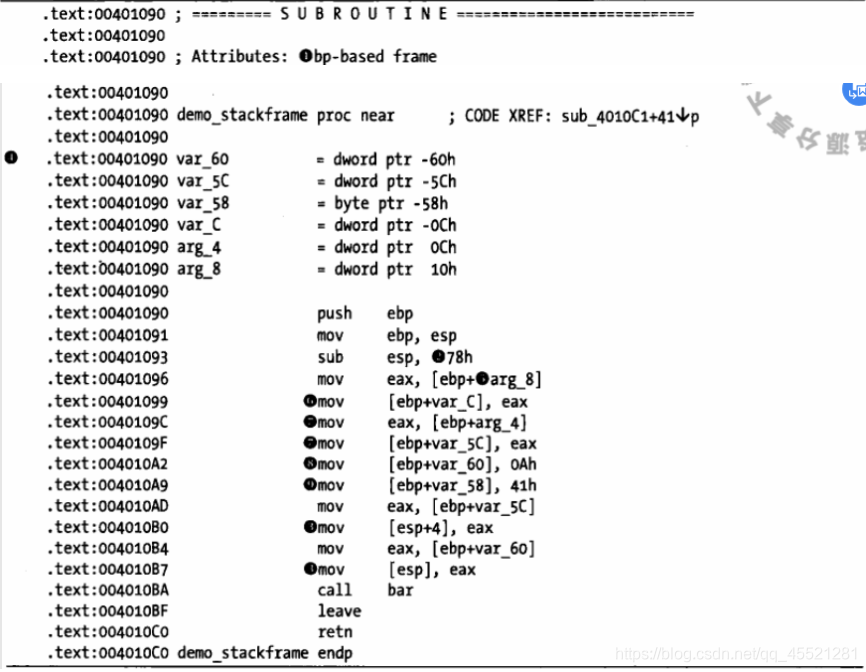
以上编号从上到下依次为①④②⑤⑥⑦⑦⑧⑨③③
下面我们介绍以上代码中的许多内容,以逐步熟悉IDA的反汇编代码。
重要:
首先从①开始,基于对函数“序言”代码的分析,IDA认为这个函数使用EBP寄存器作为栈指针。
从位置②得知,gcc 在栈帧中分配了120字节( 78h等于120 )的局部变量空间,这包括用于向❸处的bar传递两个参数的8字节;但是,它仍然远大于我们前面估算的76字节,这表示编译器有时会用额外的字节填补局部变量空间,以确保栈帧内的特殊对齐方式。
从④开始,IDA提供了一个 摘要栈视图,列出了栈帧内被直接引用的每一个变量/参数,以及变量/参数的大小和它们与帧指针的偏移距离。 IDA会根据变量相对于被保存的返回地址的位置,为变量取名。局部变量位于被保存的返回地址之上,而函数参数则位于被保存的返回地址之下。局部变量名称以var_为前缀,后面跟一个表示变量与被保存的帧指针之间距离(以字节为单位)的十六进制后缀。在本例中,局部变量var_ C是一个4字节( dword)变量,它位于所保存的帧指针之上,距离为12字节( [ebp-0Ch] )。
函数参数名则以arg_为前缀,后面跟一个表示其与最顶端的参数之间的相对距离的十六进制后缀。因此,最顶端的4字节参数名为arg_0,而随后的参数则分别为arg_4、arg_8、arg_C,以此类推。在这个特例中,arg_0并未列出,因为函数没有使用参数a。 由于IDA无法确定任何对[ebp+8] (第一个参数的位置) 的内存引用,所以arg_0并未在摘要栈视图中列出。迅速浏览一下摘要栈视图即可发现,许多栈位置都没有命名,因为在程序代码中找不到对这些位置的直接引用。

IDA反汇编代码清单与我们前面执行的栈帧分析之间的一个重要区别在于,在反汇编代码清单中无法找到类似于[ebp-12]的内存引用。相反,IDA已经用与栈视图中的符号对应的符号名称,以及它们与帧指针的相对偏移量替代了所有常量偏移量。这样做是为了确保IDA生成更高级的反汇编代码。与处理数字常量相比,处理符号名称更容易一些。 实际上,为方便我们记忆栈变量的名称,IDA允许任意修改任何栈变量的名称,稍后介绍这一一点。 摘要栈视图则是从IDA生成的名称到它们对应的 栈帧偏移量 之间的一个“地图”。 例如,在反汇编代码清单中出现内存引用[ebp+arg_8]的地方,可以使用[ebp+10h]或[ebp+16]代替(即基址+偏移/位移地址)。 看到这里,我竟豁然开朗。
如果你更希望看到数字偏移量,IDA会乐于为你显示。右击⑤处的arg_8,将会出现如图6-5所示的上下文菜单,它提供了几个可用于更改显示格式的选项。

在这个特例中,由于可以对照源代码,我们可以利用反汇编窗口中的一系列线索,将IDA生成的变量名称与源代码中使用的名称对应起来。
(1)首先,demo_stackframe使用 了3个参数: a、b和c。它们分别与变量arg_0、 arg_4和arg_8对应(尽管arg_0因没有被引用而被反汇编代码清单忽略了)。
(2)局部变量x由参数c初始化。因此,var_C与x对应,因为x由⑥处的arg_ 8初始化。
(3)同样,局部变量y由参数b初始化。因此,var_5C与y对应,因为y由❼处的arg_4初始化。
(4)局部变量z与var_ 60对应,因为它由❽处的值10初始化。
(5) 64字节的字符数组buffer从var_58处开始,因为buffer[0]由❾处的A ( ASCII 0x41 )初
始化。
(可能后定义的先入栈吧)
(6)调用bar的两个变量被转移到③处的栈中,而非压人栈。这是当前版本( 3.4及更高版本)的gcc的典型做法。IDA认可这一约定并 选择不为栈帧顶部的两项创建局部变量引用。除摘要栈视图外,IDA还提供一个详细栈帧视图,这种视图会显示一个栈帧所分配到的每一个字节。 双击任何与某一给定的栈帧有关的变量名称,即可进入 详细视图。在前一个列表中, 双击var_C将打开如图6-6所示的栈帧视图( 按ESC键关闭该窗口)。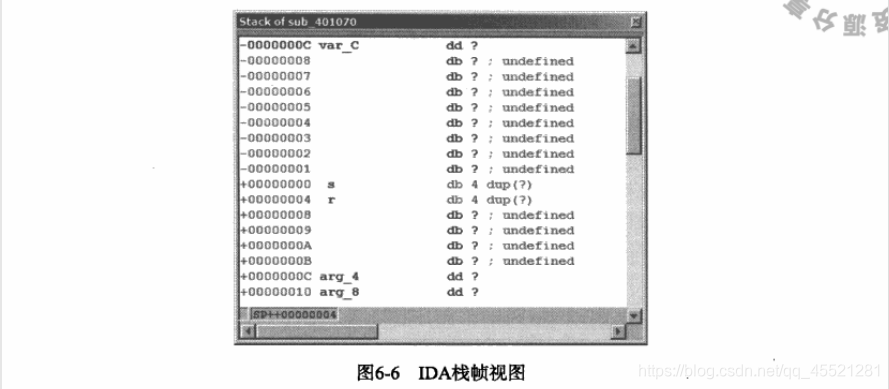
**由于详细视图显示栈帧中的每一个字节,它占用的空间会比 摘要视图 (仅列出被引用的变量) 多许多。**图6-6中显示的栈帧部分共跨越32字节,但它仅占整个栈帧的一小部分。注意,函数仅为直接引用的字节分配了名称。例如,与arg_0对应的参数a,在demo_stackframe中从未被引用。 由于 没有内存引用 可供分析,IDA选择不处理栈中的对应字节,它们的偏移量由+00000008至+0000000B。 另一方面,在反汇编代码清单中,arg_4在⑦处被直接引用,且其内容被加载到32位EAX寄存器中。 基于有32位数据被转移这一事实, IDA得出推断, arg_4是一个4字节变量, 并将其标记如此 ( db定义一个存储字节,dw定义两个存储字节,也叫做字; dd定义4个存储字节,也叫做双字)。
图6-6中显示的两个特殊值分别为s和r (前面均带有空格)。这些伪变量是IDA表示被保存的返回地址(r)和被保存的寄存器值(s,在本例中,s仅代表EBP)的特殊方法。 由于需要显示栈帧中的每一个字节,为体现完整性,这些值也包含在栈帧视图中。
栈帧视图有利于我们深入分析编译器的内部工作机制。在图6-6中,很明显,编译器在保存的帧指针s与局部变量x( var_C )之间额外插人了8字节。在栈帧中,这些字节的偏移量为 -00000001至-00000008。另外,对与摘要视图中列出的每一个变量有关的偏移量进行几次算术运算,即可发现:编译器给位于var_58的字符缓冲区分配了76字节(而非源代码中的64字节)。 如果你是一名编译器开发者,或者愿意深人分析gcc的源代码,否则,你只能推测编译器如此分配这些额外字节的原因。多数情况下,你可以将分配这些额外字节的原因归结成为对齐所做的填补,而且这些字节通常不会影响程序的行为。 毕竟,如果程序员要求64字节,却得到76字节,程序应该不会表现出不同的行为,特别是程序员使用的字节没有超出所请求的64字节的情况下。另方面,如果你是一名破解程序开发人员,并且知道可以使这个特殊的缓冲区溢出,那么,你应该认识到,你至少得提供76字节(就编译器而言,这是缓冲区的有效大小),否则你希望看到的事就不会发生。
—————————————————————————————————————————————————————————————
以上内容参考《IDA pro权威指南》
