Python在众多编程语言中有着很多强大的依赖库支持,能用很简短的代码完成很复杂的事情。
最近复仇者联盟4非常火爆,而且口碑炸裂。因此,作者运用Python对此电影做了一些简单的分析。分析的具体流程如下:
1.数据获取:使用爬虫在豆瓣网上获取信息
2.数据清洗:清洗html中的标签
3.数据展示:把数据以图片的形式展现出来
第一部分(数据获取)
这是爬虫中要用到的依赖库,这里就不展开了(因为都是爬虫基础)
获取数据的第一步就是分析网页
打开豆瓣(https://movie.douban.com/subject/26100958/comments?start=20&limit=20&sort=new_score&status=P 链接飞机票)
分析网页最直接的就是按F12,这里以一般的浏览器为例。
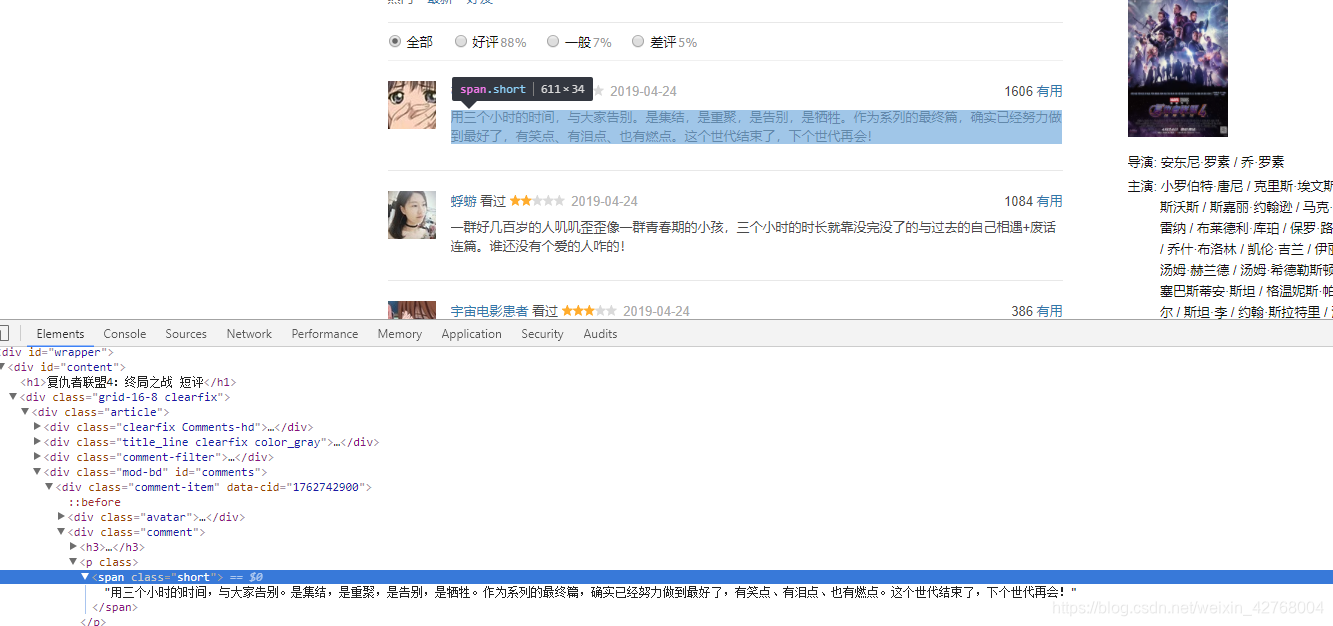
这里我们可以看到评论这一部分在网页中的标签是“span”,对应的属性是“short”,而且通过手动点击分析到它的页面跳转的时候,链接唯一变化的是其中的“start=”后面的值,因此要爬取多页数据的话就要控制这个数值了。
因此有以下代码:

因为爬取豆瓣多页数据是需要页数跳转以及header检测的,还有简单的反检测time来控制访问的时间。这样我们就把短评部分的标签以及内容爬取了。下面就是清洗这些数据,只要我们想要的文字。
第二部分(数据清洗):
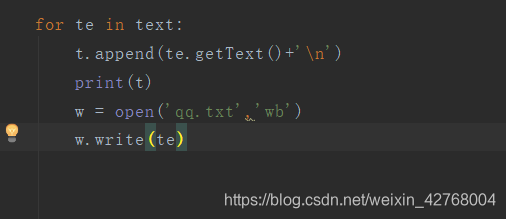
这是一种常用的或去文字的方法,并且写入txt中。
上面两部分算是前期准备吧,完整的代码如下:
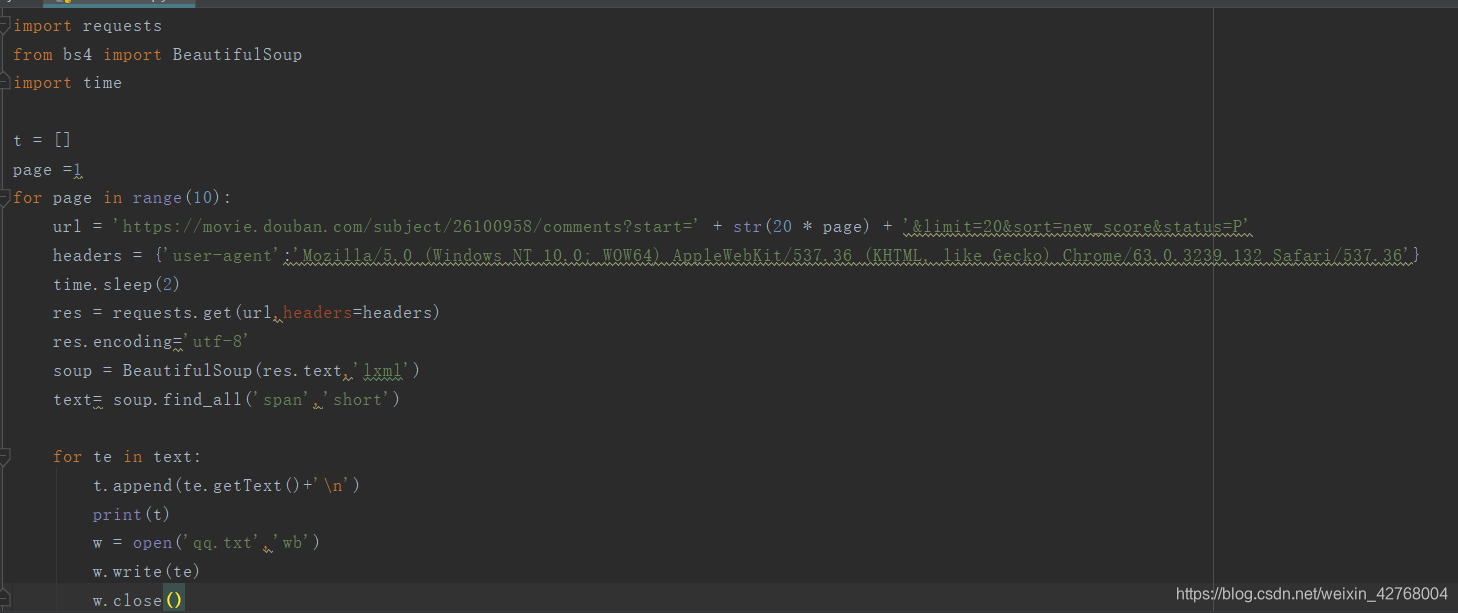
第三部分(数据展示):
为了绘制云图,这里用了比较流行且很强大的一个库 WordCloud
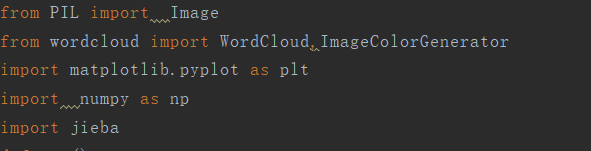
wordcloud:绘制词云的依赖库
jieba:因为wordcloud不支持中文,所以jieba用于中文划分
其他库函数就不做特别说明了,都是图片展示的依赖库
首先把刚从豆瓣爬取的数据读取:
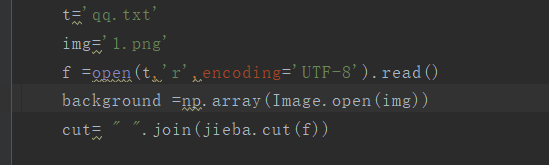
t=‘qq.txt’ 就是刚我们爬取的评论然后写入txt的数据
img则是云图的背景图
cut就是jieba的中文划分功能
然后是绘制云图
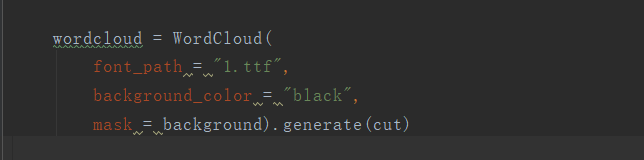
font_path是电脑字体的一种,这里可以更改。
下面是绘制云图的完整代码:
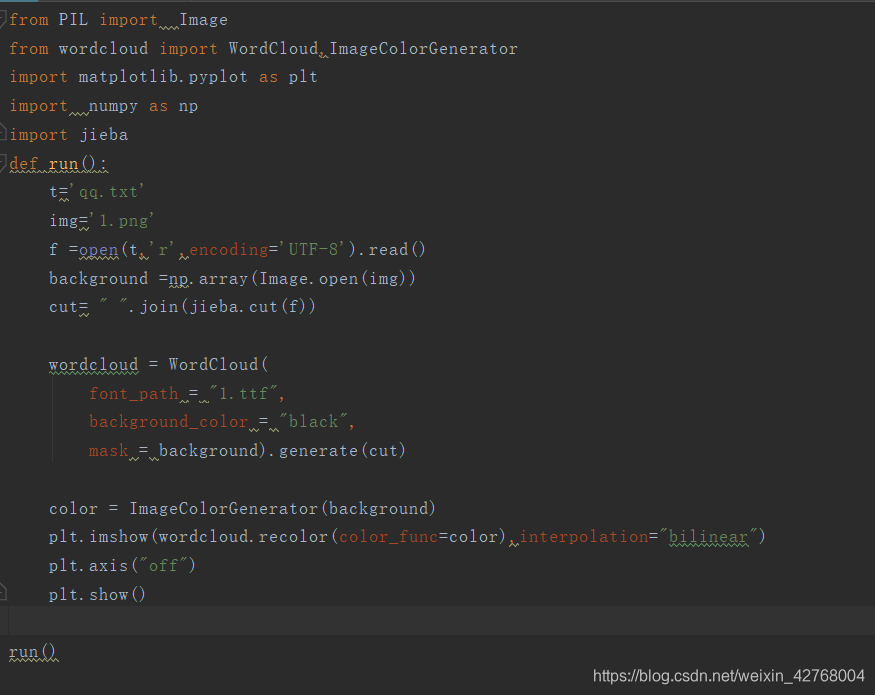
运行上面代码就有以下效果图:

背景图为:

这是作者的第一篇博客(处女作),可能会有不够好的地方。欢迎留言!
