未经允许禁止转载,转载请联系作者。
目录
4.4 findFirst/anyMatch/max/min等其他方法
一:什么是 Stream
1.1 简介
java8新添加了一个特性:流Stream。Stream和I/O流不同,它更像具有Iterable的集合类,但行为和集合类又有所不同,它是对集合对象功能的增强,让开发者能够以一种声明的方式处理数据源(集合、数组等),它专注于对数据源进行各种高效的聚合操作(aggregate operation)和大批量数据操作 (bulk data operation)。
举个例子,只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream是一种对 Java 集合运算和表达的高阶抽象。Stream API将处理的数据源看做一种Stream(流),Stream(流)在Pipeline(管道)中传输和运算,支持的运算包含筛选、排序、聚合等,当到达终点后便得到最终的处理结果。
几个关键概念:
- 元素 Stream是一个来自数据源的元素队列,Stream本身并不存储元素。
- 数据源(即Stream的来源)包含集合、数组、I/O channel、generator(发生器)等。
- 聚合操作 类似SQL中的filter、map、find、match、sorted等操作
- 管道运算 Stream在Pipeline中运算后返回Stream对象本身,这样多个操作串联成一个Pipeline,并形成fluent风格的代码。这种方式可以优化操作,如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代 不同于java8以前对集合的遍历方式(外部迭代),Stream API采用访问者模式(Visitor)实现了内部迭代。
- 并行运算 Stream API支持串行(stream() )或并行(parallelStream() )的两种操作方式。
1.2 Stream API的特点:
- Stream API的使用和同样是java8新特性的lambda表达式密不可分,可以大大提高编码效率和代码可读性。
- Stream API提供串行和并行两种操作,其中并行操作能发挥多核处理器的优势,使用fork/join的方式进行并行操作以提高运行速度。
- Stream API进行并行操作无需编写多线程代码即可写出高效的并发程序,且通常可避免多线程代码出错的问题。
和以前的Collection操作不同, Stream操作有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
为什么选择Stream呢?体验函数式编程带来的便捷!减少你的代码!
Stream的操作是建立在函数式接口的组合上的,函数式接口,对于Java来说就是接口内只有一个公开方法的接口。Java8提供了很多函数式接口,一般都使用注解@FunctionalInterface声明,有必要一些函数式接口。
二 Stream流的创建
stream的类图关系:

2.1 通过Collection 接口函数
Java8 中的 Collection 接口被扩展, 供了两个获取流的方法:
1. default Stream< E> stream() : 返回一个顺序流
List<String> strings = Arrays.asList("test", "lucas", "Hello", "HelloWorld", "武汉加油");
Stream<String> stream = strings.stream();
2. default Stream< E> parallelStream() : 返回一个并行流
List<Employee> list = new ArrayList<>();
Stream<Employee> stream = list.stream();
Stream<Employee> parallelStream = list.parallelStream();并行流是多线程方式,需要考虑线程安全问题。
2.2 通过Stream
2.2.1通过Stream:由值创流
Stream<String> stream = Stream.of("test", "lucas", "Hello", "HelloWorld", "武汉加油");2.2.2 通过Stream:函数创流
可以使用Stream的静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。
1. 迭代:public static< T> Stream< T> iterate(final T seed, final UnaryOperator< T> f)
2. 生成:public static< T> Stream< T> generate(Supplier< T> s)
例子:
// 迭代
Stream<Integer> stream3 = Stream.iterate(0, (x) -> x + 2).limit(2);
stream3.forEach(System.out::println);
System.out.println("-------------");
// 生成
Stream<Double> generateA = Stream.generate(new Supplier<Double>() {
@Override
public Double get() {
return java.lang.Math.random();
}
});
Stream<Double> generateB = Stream.generate(()-> java.lang.Math.random());
Stream<Double> generateC = Stream.generate(java.lang.Math::random).limit(4);
generateC.forEach(System.out::println);
//执行结果
0
2
-------------
0.0064617087705397536
0.24943325913078163
0.9396182936441738
0.031970039813425166这种函数创建方法较少使用,但也因场景而异。上例可以直观理解并加深印象:Stream流和Lambda表达式的结合多么的重要!代码因此简洁易懂。
三 Stream流的中间操作之常用用法
Stream有很多中间操作,多个中间操作可以连接起来形成一个流水线,每一个中间操作就像流水线上的一个工人,每人工人都可以对流进行加工,加工后得到的结果还是一个流,除非流水线上触发终止操作,否则中间操作不会执行任何的处理! 而在终止操作时一次性全部处理,称为“惰性求值”。
这些中间操作就是我们经常用到的一些Stream的接口用法:

3.1 filter方法
filter 方法通过设置条件对元素进行过滤并得到一个新流(就是你去选择过滤流中的元素)。
例子,以下代码片段使用 filter 方法过滤掉空字符串:
public static void main(String[] args) {
List<String> strings = Arrays.asList("test", "lucas", "Hello", "HelloWorld", "武汉加油");
strings.stream().filter(string -> !string.isEmpty()).forEach(System.out::println);
}
运行结果
test
lucas
Hello
HelloWorld
武汉加油3.2 concat方法
concat方法将两个Stream连接在一起,合成一个Stream。若两个输入的Stream都时排序的,则新Stream也是排序的;若输入的Stream中任何一个是并行的,则新的Stream也是并行的;若关闭新的Stream时,原两个输入的Stream都将执行关闭处理。
例子:
Stream.concat(Stream.of(1, 4, 3), Stream.of(2, 5))
.forEach(integer -> System.out.print(integer + " "));运行结果
1 4 3 2 5 3.3 map方法
| 方法 | 描述 |
| map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。 |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。 |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。 |
| flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
map 方法用于映射每个元素到对应的结果。
例子,以下代码片段使用 map 输出了元素对应的平方数:
List<String> strings = Arrays.asList("test", "lucas", "Hello","HelloWorld", "武汉加油");
strings.stream()
.filter(string -> !string.isEmpty())
.map(String::length)
.forEach(System.out::println);
//运行结果
4
5
5
10
4我们略看下map的源码:
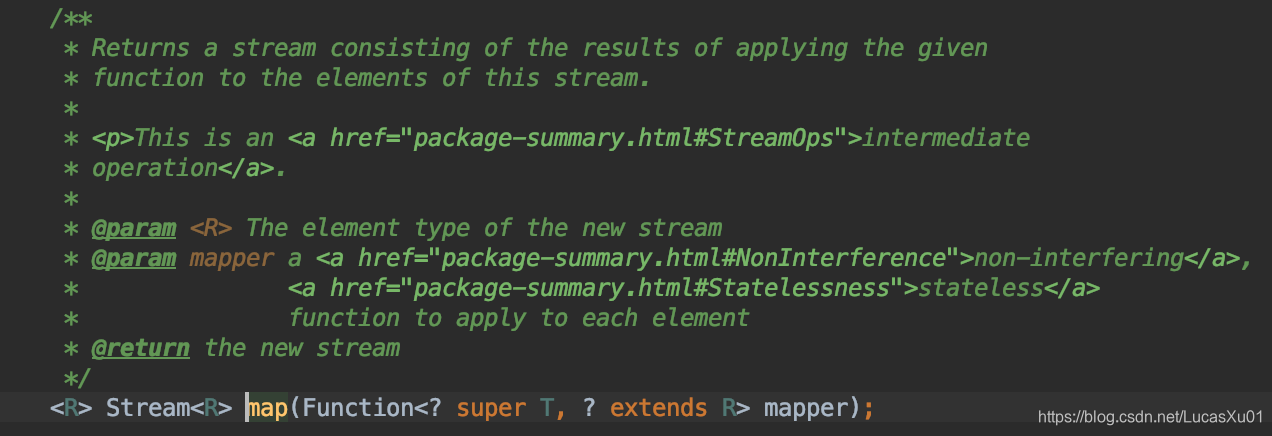
这边需要强调的一点是,Function是java8新增的函数式接口,map需要传入一个Function的实现,这边又直接利用Lambda表达式完美地让我们只去关注map()括号中的函数而省略了很多繁杂的接口实现的书写(比如上例的String::length,看到“::"不要疑惑,Java 8的另一个特点“引用方法”就是用的冒号“::”来进行方法的调用)。
3.4 flatMap方法
flatMap方法与map方法类似,map方法会再创建一个新的Stream,而flatmap()是将原Stream的元素取代为转换的Stream。
如果转换函数生产的Stream为null,应由空Stream取代。
flatMap有三个对于原始类型的变种方法,分别是:flatMapToInt,flatMapToLong和flatMapToDouble。
Stream.of(1, 2, 3)
.flatMap(integer -> Stream.of(integer * 10))
.forEach(System.out::println);
// 10,20,30
传给flatMap中的表达式接受了一个Integer类型的参数,通过转换函数,将原元素乘以10后,生成一个只有该元素的流,该流取代原流中的元素。
3.5 Stream中的reduce方法
reduce方法有三个重载的方法。
第一个方法
接受一个BinaryOperator类型的lambada表达式, 常规应用方法如下
Optional<T> reduce(BinaryOperator<T> accumulator);例子
List<Integer> numList = Arrays.asList(1,2,3,4,5);
int result = numList.stream().reduce((a,b) -> a + b ).get();
System.out.println(result);第二个方法
与第一个方法的实现的唯一区别是它首次执行时表达式第一次参数并不是stream的第一个元素,而是通过签名的第一个参数identity来指定。
T reduce(T identity, BinaryOperator<T> accumulator);例子
List<Integer> numList = Arrays.asList(1,2,3,4,5);
int result = numList.stream().reduce(0,(a,b) -> a + b );
System.out.println(result);其实这两种实现几乎差别,第一种比第一种仅仅多了一个字定义初始值罢了。 此外,因为存在stream为空的情况,所以第一种实现并不直接方法计算的结果,而是将计算结果用Optional来包装,我们可以通过它的get方法获得一个Integer类型的结果,而Integer允许null。第二种实现因为允许指定初始值,因此即使stream为空,也不会出现返回结果为null的情况,当stream为空,reduce为直接把初始值返回。
第三个方法
第三种方法的用法相较前两种稍显复杂,由于前两种实现有一个缺陷,它们的计算结果必须和stream中的元素类型相同,如上面的代码示例,stream中的类型为int,那么计算结果也必须为int,这导致了灵活性的不足,甚至无法完成某些任务, 比入我们咬对一个一系列int值求和,但是求和的结果用一个int类型已经放不下,必须升级为long类型,此实第三签名就能发挥价值了,它不将执行结果与stream中元素的类型绑死。
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);例子
List<Integer> numList = Arrays.asList(1, 2, 3, 4, 5, 6);
ArrayList<String> result = numList.stream().reduce(new ArrayList<String>(), (a, b) -> {
a.add("int转成string:" + Integer.toString(b));
return a;
}, (a, b) -> null);
System.out.println(result);
//[int转成string:1, int转成string:2, int转成string:3, int转成string:4, int转成string:5, int转成string:6]
如果你使用了parallelStream reduce操作是并发进行的,为了避免竞争,每个reduce线程都会有独立的result combiner的作用在于合并每个线程的result得到最终结果。
BinaryOperator是供多线程使用的,如果不在Stream中声明使用多线程,就不会使用子任务,自然也不会调用到该方法。另外多线程下使用BinaryOperator的时候是需要考虑线程安全的问题。
3.6 peek方法
peek方法生成一个包含原Stream的所有元素的新Stream,同时会提供一个消费函数(Consumer的实例),新Stream每个元素被消费的时候都会优先执行给定的消费函数,具体可看Consumer函数。
Stream.of(1, 2, 3)
.peek(integer -> System.out.println("peek中优先执行的消费函数:这是" + integer))
.forEach(System.out::println);运行结果:
peek中优先执行的消费函数:这是1
1
peek中优先执行的消费函数:这是2
2
peek中优先执行的消费函数:这是3
33.7 limit/skip方法
limit 返回 Stream 的前面 n 个元素;
skip 则是扔掉前 n 个元素。
例子,以下代码片段使用 limit 方法保理4个元素:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream().limit(4).forEach(System.out::println);
//1,2,3,43.8 sorted方法
sorted 方法用于对流进行排序。
例子,以下代码片段使用 sorted 方法进行排序:
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
numbers.stream().sorted().forEach(System.out::println);
//2,2,3,3,3,5,73.9 distinct方法
distinct主要用来去重。
例子,以下代码片段使用 distinct 对元素进行去重:
List<Integer> numbers = Arrays.asList(3, 3, 7, 3, 5);
numbers.stream().distinct().forEach(System.out::println);
//3,7,53.10 一个小汇总实例
List<String> strings = Arrays.asList("", "lucas", "Hello", "HelloWorld", "武汉加油");
Stream<Integer> distinct = strings.stream()
.filter(string -> string.length() <= 6) //过滤掉了"HelloWorld"
.map(String::length) //将Stream从原来元数据的String类型变成了int
.sorted() //int从小到大
.limit(2) //只选前两个
.distinct(); //去重
distinct.forEach( System.out::println);运行结果:
0
4四 Stream最终操作
最终操作(terminal operation)解释:终止操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer等。而Stream的中间操作得到的结果还是一个Stream,那么如何把一个Stream转换成我们需要的类型呢?这就需要最终操作(terminal operation)
最终操作会消耗流,产生一个最终结果。也就是说,在最终操作之后,不能再次使用流,也不能在使用任何中间操作,否则将抛出异常:
java.lang.IllegalStateException: stream has already been operated upon or closed
复制代码常用的最终操作如下:
| 方法 | 描述 |
| allMatch(Predicate p) | 检查是否匹配所有元素 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素 |
| findAny() | 返回当前流中的任意元素 |
| count() | 返回流中元素总数 |
| max(Comparator c) | 返回流中最大值 |
| min(Comparator c) | 返回流中最小值 |
| forEach(Consumer c) | 内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代。相反,Stream API 使用内部 迭代——它帮你把迭代做了) |
4.1 forEach方法
Stream 提供了方法 'forEach' 来迭代流中的每个数据。注意forEach方法的参数是Cousumer。
以下代码片段使用 forEach 输出了10个随机数:
Random random = new Random();
random.ints().limit(10).forEach(System.out::println);4.2 count方法
count用来统计流中的元素个数。
List<String> strings = Arrays.asList("", "lucas", "Hello", "HelloWorld", "武汉加油");
long count = strings.stream()
.filter(string -> string.length() <= 6)
.map(String::length)
.sorted()
.limit(2)
.distinct()
.count();
System.out.println(count);
//24.3 collect方法
collect中有很多的静态方法,灵活运用会起到四两拨千斤的作用。
collect是一个归约操作,可以接受各种做法作为参数,将流中的元素累积成一个汇总结果:
List<String> strings = Arrays.asList("", "lucas", "Hello", "HelloWorld", "武汉加油");
List<Integer> collect = strings
.stream()
.filter(string -> string.length() <= 6)
.map(String::length)
.sorted()
.limit(2)
.distinct()
.collect(Collectors.toList());
collect.forEach(System.out::println);
//运行结果
0
4
如上,最终得到一个List 数组,也就是流最终的归宿。
以上只属于collect一个简单生成List例子,Collect有更多便捷的操作供开发者选择使用,我们可以利用Collectors类中提供的各种静态方法,组合实现很多多样化的需求。
Collectors类中提供的一些常用静态方法:
| 方法 | 返回类型 | 作用 | 实例 |
| toList | List<T> | 把流中元素收集到List | List<Employee> emps= list.stream().collect(Collectors.toList()); |
| toSet | Set<T> | 把流中元素收集到Set | Set<Employee> emps= list.stream().collect(Collectors.toSet()); |
| toCollection | Collection<T> | 把流中元素收集到创建的集合 | Collection<Employee>emps=list.stream().collect(Collectors.toCollection(ArrayList::new)); |
| counting | Long | 计算流中元素的个数 | long count = list.stream().collect(Collectors.counting()); |
| summingInt | Integer | 对流中元素的整数属性求和 | inttotal=list.stream().collect(Collectors.summingInt(Employee::getSalary)); |
| joining | String | 连接流中每个字符串 | String str= list.stream().map(Employee::getName).collect(Collectors.joining()); |
| groupingBy | Map<K, List<T>> | 根据某属性值对流分组,属 性为K,结果为V | Map<Emp.Status, List<Emp>> map= list.stream() .collect(Collectors.groupingBy(Employee::getStatus)); |
| partitioningBy | Map<Boolean, List<T>> | 根据true或false进行分区 | Map<Boolean,List<Emp>>vd= list.stream().collect(Collectors.partitioningBy(Employee::getManage)); |
| reducing | 归约产生的类型 | 从一个作为累加器的初始值 开始,利用BinaryOperator与 流中元素逐个结合,从而归约成单个值 | inttotal=list.stream().collect(Collectors.reducing(0, Employee::getSalar, Integer::sum)); |
| averagingInt | Double | 计算流中元素Integer属性的平均值 | doubleavg= list.stream().collect(Collectors.averagingInt(Employee::getSalary)); |
| maxBy | Optional<T> | 根据比较器选择最大值 | Optional<Emp>max= list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary))); |
| minBy | Optional<T> | 根据比较器选择最小值 | Optional<Emp> min = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary))); |
| summarizingInt | IntSummaryStatistics | 收集流中Integer属性的统计值。 如:平均值 | IntSummaryStatisticsiss= list.stream().collect(Collectors.summarizingInt(Employee::getSalary)); |
| collectingAndThen | 转换函数返回的类型 | 包裹另一个收集器,对其结 果转换函数 | inthow= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size)); |
下面举一个分组和多级分组(其实就是嵌套使用groupingBy)的例子:
List<Person> person_list = Arrays.asList(
new Person("lucas", 26),
new Person("lucas", 25),
new Person("lucas", 60),
new Person( "chris", 27),
new Person( "chris", 20),
new Person("theo", 52)
);
System.out.println("-------- 利用Collectors的静态方法一级分组---------");
Map<String, List<Person>> group = person_list.stream()
.collect(Collectors.groupingBy(Person::getName));
System.out.println(group);
System.out.println("-------- 利用Collectors的静态方法二级分组---------");
Map<String, Map<String, List<Person>>> group2 = person_list.stream()
.collect(Collectors.groupingBy(Person::getName, Collectors.groupingBy((people) -> {
if (people.getAge() < 30) return "青年";
else if (people.getAge() < 50) return "中年";
else return "老年";
})));
System.out.println(group);运行结果:
-------- 利用Collectors的静态方法一级分组---------
{
chris=[cn.lucas.Person@52cc8049, cn.lucas.Person@5b6f7412],
lucas=[cn.lucas.Person@27973e9b, cn.lucas.Person@312b1dae, cn.lucas.Person@7530d0a],
theo=[cn.lucas.Person@27bc2616]
}
-------- 利用Collectors的静态方法二级分组---------
{
chris={
青年=[cn.lucas.Person@52cc8049, cn.lucas.Person@5b6f7412]
},
lucas={
青年=[cn.lucas.Person@27973e9b, cn.lucas.Person@312b1dae],
老年=[cn.lucas.Person@7530d0a]
},
theo={
老年=[cn.lucas.Person@27bc2616]
}
}
可以看到,巧妙地利用Collect里的方法,对于一些“脏活儿累活儿干死了又没有太大价值的活儿”而言,实现起来是多么的方便优雅(上述逻辑直接可以用到一堆数据二级列表展示时的List数据处理过程中)!我们主需要把关注点,并且主要的代码量也都在代码的业务逻辑上了。
再来一个Collectors.partitioningBy分割数据块的例子,会让你感到简单又优雅:
public static void main(String[] args) {
Map<Boolean, List<Integer>> collectParti = Stream.of(1, 2, 3, 4)
.collect(Collectors.partitioningBy(it -> it % 2 == 0));
System.out.println("分割数据块 : " + collectParti);
}
//分割数据块 : {false=[1, 3], true=[2, 4]}4.4 findFirst/anyMatch/max/min等其他方法
List<Person> person_list = Arrays.asList(
new Person("lucas", 26),
new Person("maggie", 25),
new Person("queen", 23),
new Person( "chris", 27),
new Person( "max", 29),
new Person("theo", 30)
);
System.out.println("-------- allMatch() 检查是否匹配所有元素---------");
boolean allMatch = person_list.stream()
.allMatch((person -> person.getName().equals("lucas")));
System.out.println(allMatch);
System.out.println("-------- anyMatch() 检查是否至少匹配一个元素---------");
boolean anyMatch = person_list.stream()
.anyMatch(person -> person.getName().equals("lucas"));
System.out.println(anyMatch);
System.out.println("-------- noneMatch 检查是否没有匹配所有元素---------");
boolean noneMatch = person_list.stream()
.noneMatch(person -> person.getName().equals("lucas"));
System.out.println(noneMatch);
System.out.println("-------- findFirst() 返回第一个元素---------");
Optional<String> first = person_list.stream()
.map(Person::getName)
.findFirst(); // 获取第一个元素
System.out.println(first.get());
System.out.println("-------- findAny() 返回当前流中的任意元素---------");
boolean anyMatch1 = person_list.stream()
.anyMatch(person -> person.getName().equals("lucas"));
System.out.println(anyMatch1);
System.out.println("-------- max() 返回流中最大值---------");
Optional<Integer> intOptional = person_list.stream()
.map(Person::getAge)
.max(Integer::compare); //最大值
System.out.println(intOptional.get());
运行结果:
-------- allMatch() 检查是否匹配所有元素---------
false
-------- anyMatch() 检查是否至少匹配一个元素---------
true
-------- noneMatch 检查是否没有匹配所有元素---------
false
-------- findFirst() 返回第一个元素---------
lucas
-------- findAny() 返回当前流中的任意元素---------
true
-------- max() 返回流中最大值---------
30参考
https://juejin.im/post/5df4a93e51882512454b37fa
https://www.jianshu.com/p/2b40fd0765c3
https://blog.csdn.net/liudongdong0909/article/details/77429875
https://www.jianshu.com/p/e6cdc48bb355
https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html
https://www.jianshu.com/p/71bee9a620b5
