对抗性鲁棒性与模型压缩:ICCV2019论文解析
Adversarial Robustness vs. Model
Compression, or Both?

论文链接:
http://openaccess.thecvf.com/content_ICCV_2019/papers/Ye_Adversarial_Robustness_vs._Model_Compression_or_Both_ICCV_2019_paper.pdf
Code is available at
https://github.com/yeshaokai/ Robustness-Aware-Pruning-ADMM.
摘要
众所周知,深度神经网络(DNNs)容易受到敌方攻击,这种攻击是通过在良性示例中添加精心设计的扰动来实现的。基于最小-最大鲁棒优化的对抗性训练可以提供对抗性攻击的安全性概念。然而,对抗性稳健性要求网络的容量比只有良性例子的自然训练的容量要大得多。本文提出了一种并行对抗训练和权值剪枝的框架,在保持对抗鲁棒性的前提下实现模型压缩,从本质上解决了对抗训练的难题。此外,本文还研究了两个关于传统环境下权值剪枝的假设,发现权值剪枝对于减少对抗环境下的网络模型规模是至关重要的;从无到有地训练一个小模型,即使是从大模型中继承初始化,也不能达到对抗鲁棒性和高性能标准精度。
- Introduction
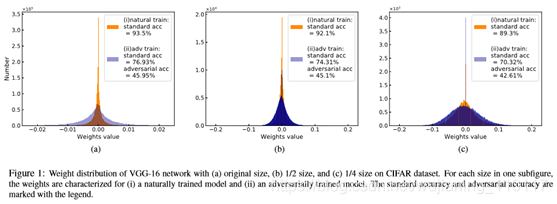
本文的动机是研究是否以及如何通过减轻网络容量需求来促进主动防御技术,即对抗性训练。图1描述了CIFAR数据集上VGG-16网络的权重分布。本文测试了VGG-16网络的原始尺寸、1/2尺寸和1/4尺寸的标准精度和对抗精度。本文有以下观察:(i)较小的模型尺寸(网络容量)表明,对抗训练模型的标准精度和对抗精度都较低。(ii)对手方训练的模型比自然训练的模型稀疏(零权重更少)。因此,在对抗训练之前进行预剪枝并不是一个可行的解决方案,而且似乎更难剪枝一个对抗训练的模型。本文试图回答这样一个问题:本文是否可以同时享受对抗鲁棒性和模型压缩。基本上,本文将权值剪枝和对抗训练结合起来,使安全关键应用在资源受限的系统中。
本文的贡献
本文建立了一个框架,通过实施并行的权值剪枝和对抗训练来实现对抗性稳健性和模型压缩。
具体来说,本文在本文的框架中使用基于ADMM(乘法器交替方向法)的剪枝[50,51],因为它与对抗训练兼容。
更重要的是,基于ADMM的剪枝具有普遍性,它支持不规则剪枝和不同类型的规则剪枝,这样本文可以很容易地在不同的剪枝方案之间切换为了公平比较。
最终,本文的框架解决了对抗训练的困境。
本文还研究了针对传统模型压缩设置提出的两个关于权重剪枝的假设,并通过实验验证了它们对于对抗性训练设置的有效性。
研究发现,权值剪枝对于在对抗环境下减小网络模型的规模是至关重要的,从无到有地训练小模型,即使从大模型继承初始化,也不能同时达到对抗鲁棒性和高标准精度。
利用提出的并行对抗训练和权值剪枝框架,系统地研究了不同剪枝方案对对抗鲁棒性和模型压缩的影响。结果表明,在对DNN模型进行剪枝时,不规则剪枝方案在保持标准精度和对抗性稳健性方面是最好的。
- Related Work
2.1. Adversarial Training
对抗性训练的一个主要缺点是,它需要一个显著的更大的网络容量来实现强大的对抗性健壮性,而不是仅对良性例子进行正确分类[33]。此外,对抗性训练比自然训练有更重要的过度训练问题[36]。在本文的后面,本文将展示与上述观察相关的一些有趣的发现。
2.2. Weight Pruning
权值剪枝作为一种模型压缩技术,被提出用来促进DNN在资源受限的应用系统中的实现,因为它探索了权值稀疏性来剪枝突触和神经元而不会显著降低精度。一般来说,规则剪枝方案在某种意义上可以保持模型的结构,而不规则剪枝方案则可以保持模型的结构。常规剪枝可以进一步分为filter剪枝方案和column剪枝方案。按名称修剪过滤器从一个层修剪整个过滤器。列修剪修剪在同一位置为层中的所有过滤器修剪权重。
请注意,有些参考文献提到了通道修剪,它的名字是完全从过滤器中修剪一些通道。但实际上,通道剪枝等同于滤波器剪枝,因为如果在一个层中剪枝某些滤波器,则会使下一层的对应通道无效[20]。在这项工作中,本文实施并研究了在对抗性训练环境中的过滤器修剪、列修剪和不规则修剪方案。而且,对于每一个剪枝方案,本文都以相同的剪枝率均匀地剪枝每一层。例如,当本文将模型大小(网络容量)删减一半时,这意味着每层的大小减少一半。
现有不规则修剪工作[17、15、49、50]和常规修剪工作[20、43、51、26、30]。此外,几乎所有的常规修剪工作实际上都是过滤器修剪,除了第一个提出列修剪的工作[43]和能够实现col通过基于ADMM的方法进行umn修剪。在这项工作中,本文使用ADMM方法,因为它对所有修剪方案都有潜力,并且它与对抗性训练兼容,这将在后面的章节中演示。
研究人员也开始反思并提出一些关于减重的假设。彩票假说[12]推测,在大网络中,子网络及其初始化使得剪枝特别有效,它们一起被称为“中奖彩票”。在这个假设中,子网络的初始值(在大网络剪枝之前)是它在孤立训练时获得竞争性能所必需的。
此外,该工作[31]得出结论,从头开始训练预先定义的目标模型并不比对同一目标模型体系结构的大型过参数化模型应用结构化(常规)修剪更糟糕,甚至更好。然而,这些假设和结论是针对一般的权重剪枝提出的。在这篇文章中,本文提出了一些有趣的观察,关于在对抗环境下的权重削减,这些都是在现有的假设下无法充分解释的[12,31]。
-
Concurrent Adversarial Training and Weight Pruning




-
Weight Pruning in the Adversarial Setting
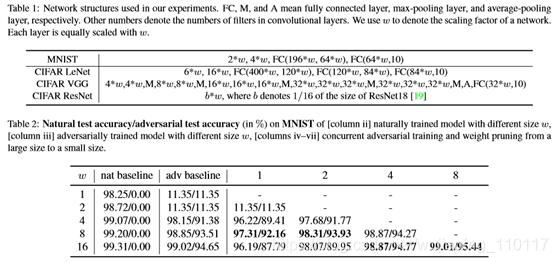
在本节中,本文将研究在对抗环境中权重修剪的性能。本文得到了与传统模型压缩设置中的[12,31]相反的有趣结果。在这里,本文提出了一个并行对抗训练和权重剪枝的框架,这是一种常用的剪枝方法,有助于稀疏神经网络在硬件上的实现。其他修剪方案将在实验部分进行研究。在表1中,本文总结了本文中测试的所有网络及其由宽度比例因子w指定的模型架构。
4.1. Weight Pruning vs Training from Scratch
尽管[31]中的结论可能适用于自然训练的背景,但在对抗性训练的背景下,情况就不同了。表2、表3和表4展示了不同数据集和网络的自然训练、对抗训练、并发对抗训练和权重修剪的自然测试精度/对抗测试精度。本文以表2为例。当本文自然地训练一个w=1的网络时,本文有98.25%的自然测试精度和0%的对抗测试精度。当本文对w=1的网络进行对抗性训练时,自然测试精度和对抗性测试精度均达到11.35%,仍然很低。结果表明,w=1的网络没有足够的能力进行强大的对抗鲁棒性。
为了提高网络的对抗鲁棒性,至少需要对w=4的网络进行对抗训练。令人惊讶的是,通过在w=4的网络上利用本文的并行对抗训练和权重剪枝,本文可以获得目标大小为w=1的更小的剪枝模型,但与w=4的对抗训练模型相比,本文可以获得竞争性的自然测试精度/对抗性测试精度(96.22%/89.41%)。为了获得具有最高自然和对抗性测试精度的w=1网络,本文应该将所提出的框架应用于w=8网络。表3和表4也有类似的意见。
总之,在对抗性训练环境中,权重剪枝的价值是至关重要的:通过权重剪枝可以获得一个既具有高自然测试精度又具有对抗性测试精度的小型模型网络。相比之下,如果将对抗训练直接应用于一个小规模的网络,而不是从重量修剪中获得,则可能会降低自然测试和对抗测试的准确性。
4.2. Pruning to Inherit Winning Ticket or Else?
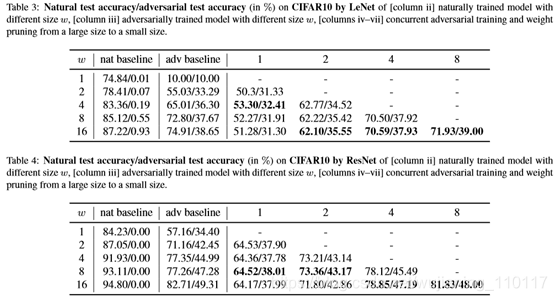
为了检验彩票假设在对抗环境下是否有效,本文在类似于[12]的实验环境下进行对抗训练。表5总结了自然/对抗性测试精度结果,其中单元格w1-w2(w1>w2)中的结果表示使用从w1大小的对抗性训练模型继承的初始化的w2大小的对抗性训练模型的精度。表5中不使用修剪。例如,表5中的单元格4-2的精度仅为11.35%/11.35%。从表2中回想,如果本文使用本文提出的并行对抗性训练和权值剪枝框架,从4号模型剪枝到2号小模型,本文可以在表2的单元格4-2中获得高精度的97.68%/91.77%。本文的结果表明,在对抗环境中的权重剪枝不在彩票假设的范围内。
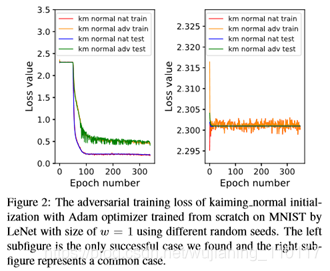
此外,为了进一步探讨对抗性训练中初始化与模型能力之间的关系,本文进行了附加实验。比较了七种不同的初始化方法,利用Adam、SGD和cosineanaling[32]在MNIST上训练300个周期的最小LeNet模型(w=1)。本文用不同的随机种子重复这个实验10次,平均准确度见表B1。如表2所示,对抗训练失败,w=1,2。
在所有研究的场景中,本文只发现两个例外:a)具有统一初始化的Adam和b)具有kaiming normal的Adam,其中10个试验中有1个成功(损失如图2所示)。即使在这些例外情况下,相应的测试精度也远低于表2中同时进行对抗性训练和权值剪枝得到的最小模型。本文还发现,在大多数情况下,11.35%的准确率对应于对抗性训练遇到的鞍点。本文在表B1中的结果表明,如果不同时进行对抗性训练和权重剪枝,即使使用不同的初始化方案和优化器,从零开始对抗性地训练一个小模型也变得极其困难。
可以清楚地看出,在对抗环境中,从大型模型中剪枝是有用的,这在自然测试精度和对抗稳健性方面都有好处。相比之下,这些优势并不是由对手从头开始训练一个小模型所提供的。这些有趣的结果可以从过度参数化的好处来解释[54,1,2],这表明当参数的数量大于训练数据所需的统计数据时,训练神经网络可能达到全局解。同样,在对抗性训练环境中,较大的、过参数化的模型会导致很好的收敛,而经过对抗性训练的小模型则经常卡在鞍点上。这两个观察结果促使本文提出一个框架,该框架可以在对抗性训练中从更大的模型中获益,同时减少模型的大小。结果,剩余的权重保持了对抗性稳健性。

5. Pruning Schemes and Transfer Attacks
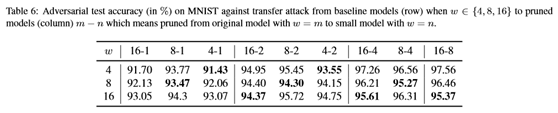
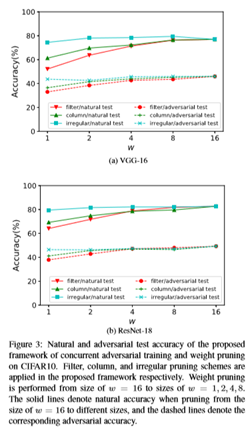
在本节中,本文研究了在不同剪枝方案(即过滤器/列/不规则剪枝)和转移攻击下,所提出的并行对抗训练和权重剪枝的性能。使用VGG-16和ResNet-18网络在CIFAR10上测试了该框架,如图3所示。如本文所见,自然测试和对抗测试的准确度随着修剪尺寸的减小而减小。
在不同的剪枝方案中,不规则剪枝的效果最好,而过滤器剪枝在自然和对抗性测试精度方面表现最差。这是因为除了权重稀疏性外,filter剪枝还施加了结构约束,与不规则剪枝相比,结构约束限制了剪枝粒度。
此外,不规则修剪保留了不同修剪大小的准确性。原因是减肥有助于缓解过度训练问题[17],对抗性训练比自然训练更容易出现过度训练[36]。在表C1中,本文评估了基于PGD对手的鲁棒模型对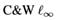 攻击的性能。
攻击的性能。
如本文所见,并行的对抗训练和权值剪枝使得剪枝模型对转移攻击具有鲁棒性。特别是,在剪枝前(基线),剪枝模型比原始模型能获得更好的对抗性测试精度。 此外,本文还设计了一个交叉转移攻击实验。考虑表2中的基线模型,当w=1,2时,模型没有得到很好的训练,因此本文从w=4,8,16的基线模型中通过PGD攻击生成对抗性例子,并应用它们来测试修剪模型。
在表6中,结果表明,即使是在每个剪枝模型的最坏情况下,对抗性测试的准确性也高于表2中剪枝模型的准确性。结果表明,无论模型的大小如何,该模型都最容易受到自身生成的对抗性例子的攻击。
- Supplementary Details of Experiment Setup
本文使用LeNet作为MNIST,使用LeNet、VGG-16和ResNet-18作为CIFAR10。这里使用的LeNet模型遵循了这一工作[33]。VGG-16和ResNet-18采用了批量标准化(BN)。表1列出了有关网络结构的更多详细信息。
此外,在CIFAR的基线上存在争议,本文采取以下措施确保基线足够强大:
-
本文遵循[31]的建议,以更大的学习率0.1作为初始学习率来训练本文的模型。
-
本文在CIFAR中训练了300个阶段的所有模型,并在[33]之后的第80和150阶段将学习率除以10倍。
-
Liu等人[31]建议从头开始训练的模型需要公平的训练时间来与修剪模型进行比较。因此,如果在训练结束时损失仍在下降,本文的训练时间将增加一倍。
-
由于自然准确度和对抗准确度之间总是存在权衡,因此当模型在测试数据集上的自然图像和对抗图像的平均损失达到最低时,本文报告准确度。
因此,本文相信,在本文的环境中,本文有公平的基线从头开始训练。
5. Conclusion
基于最小-最大鲁棒优化的对抗性训练可以提供对抗性攻击的安全性概念。然而,对抗性稳健性要求网络的容量比只有良性例子的自然训练的容量要大得多。本文提出了一种并行对抗训练和权值剪枝的框架,在保持对抗鲁棒性的前提下实现模型压缩,从本质上解决了对抗训练的难题。
此外,本文还研究了两个关于传统环境下权值剪枝的假设,发现权值剪枝对于在对抗环境下减小网络模型大小至关重要,从零开始训练小模型,即使是从大模型继承初始化,也不能同时达到对抗性的鲁棒性和高标准的精度。本文还系统地研究了不同剪枝方案对对抗鲁棒性和模型压缩的影响。
