目录
背景
最近一段时间我们负责的一组大数据定时任务因数据量太大加之资源紧张,导致执行时间超过4个小时,并触发延迟告警。由于该项目属于关键任务(p0级)阻塞了很多后续重要任务的执行,需要尽快进行优化处理。
这组任务由3个Spark Sql + 1个 Hive Sql 任务组成,这次我们除了需要优化3个Spark Sql任务外还需将Hive Sql转换为Spark Sql。
通过Spark UI 定位问题
通过查看一个比较慢的任务,我们发现以下问题
问题一:并行度设置不足
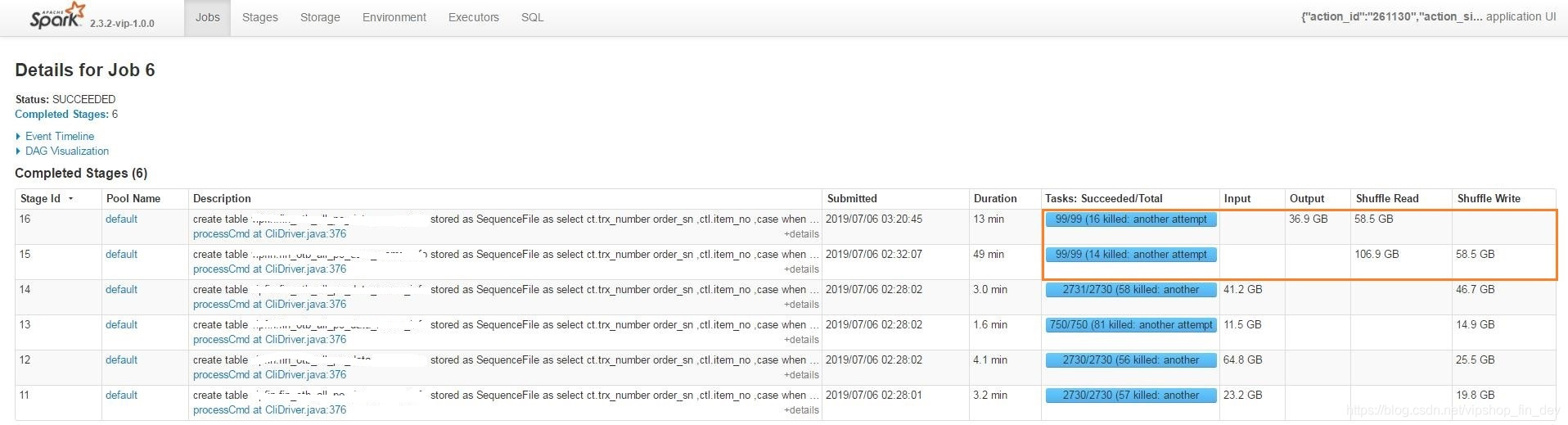
由上图可以看到有2个shuffle任务,分别耗时13min和49min,它们处理的数据量巨大,但只有99Tasks在执行,意味着每个Task要操作1G左右数据,而且如果有数据倾斜将可能操作更多数据。
问题二:数据倾斜,重复导入
通过SQL标签进入,找到耗时最长的那个进入
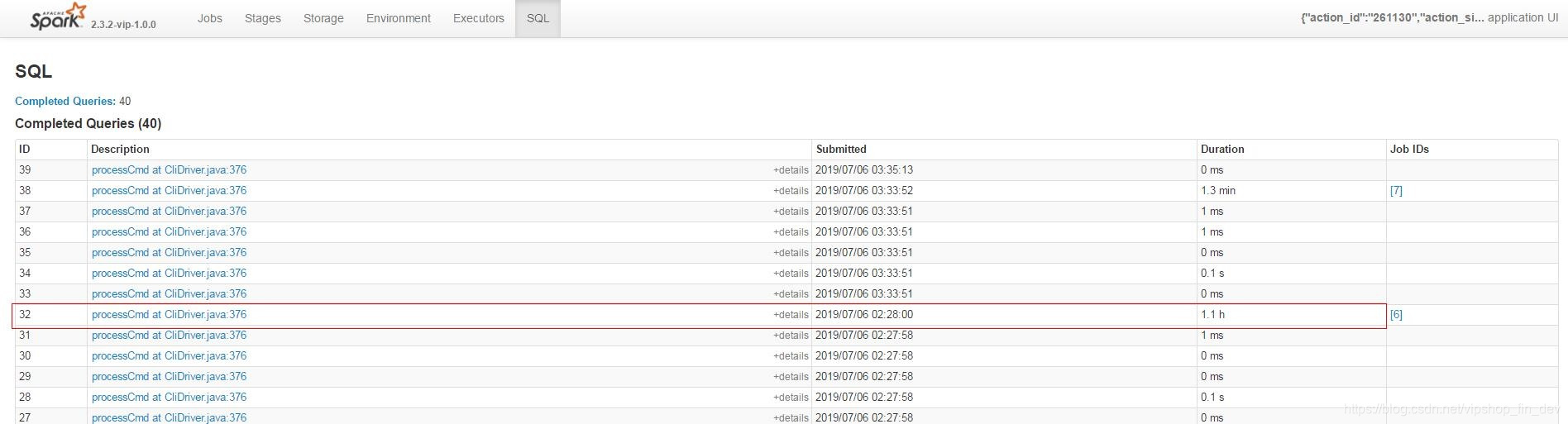
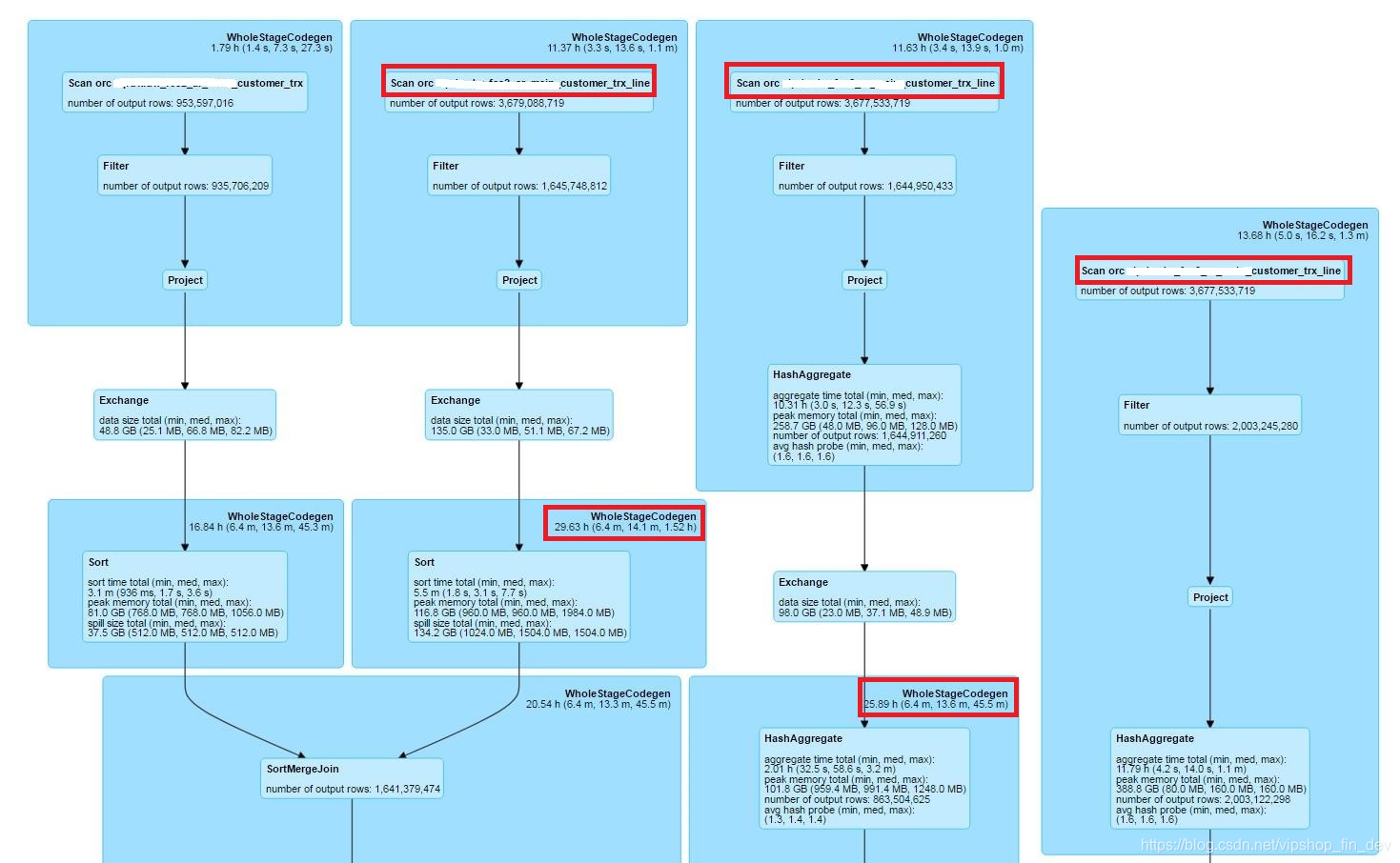
找到耗时最长的步骤,可以看到对应有三处用到customer_trx_line,说明这个表被join了3次,而且在join的过程中耗时非常长(38亿数据,估算最慢的要1个多小时),找到对应SQL后发现这个join都是基于trx_id字段的。
使用 Distribute By、Cluster By 进行优化
优化思路
对于以上发现的两个问题,解决方式如下:
一,需要增加并行度,即Spark里的repartition方法。
二,需要重分区时按trx_id维度分布,对应repartition方法的参数中也可以体现。
以上是代码级别方式,换成SQL就需要使用到我们说的 Distribute By,Cluster By了。
Distribute By、Cluster By 原理
在Spark中,从1.6.1版本开始就已经支持Distribute By、Cluster By了,它们都是源于Hive SQL,定义也与之一样。
我们先看看它们是怎么定义的:
Distribute By —— It ensures each of N reducers gets non-overlapping ranges of column, but doesn’t sort the output of each reducer. You end up with N or more unsorted files with non-overlapping ranges.
Cluster By —— Cluster By is a short-cut for both Distribute By and Sort By。
翻译过来大概就是说 Distribute By 可以根据给定栏位(column)将数据分为不重叠的N个部分,对应了N个reducer,但并不执行排序操作,即里面的数据是乱序的。而 Cluster By = Distribute By + Sort By(排序关键字),即分割后的数据是经过排序的。可以简单理解Distribute By实际就是repartition方法了,只是它的参数设置方式不同而已。

重分区个数(也等同于执行的并行度)可以通过如下语句进行设置:
SET spark.sql.shuffle.partitions = $num
Distribute By 操作结果如下图(num=2),其中按第一个数值栏位进行分区,1、3分在一起,2分在另一个区。
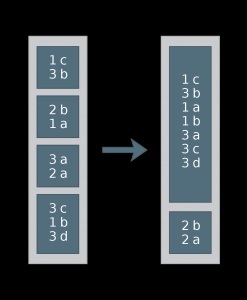
Cluster By 的操作结果如下图,不仅1、3与2分在不同区,而且还各自排了序。
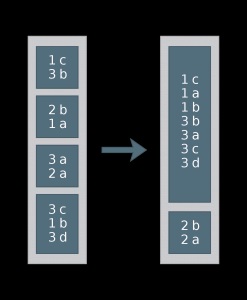
那这样分割后有什么好处呢?我们知道Spark在执行Join操作时是需要Shuffle的,而优化Spark执行速度的最重要方式就是避免Shuffle或减少每个Shuffle的数量。
在未使用 Distribute By 时,Spark是随机将数据分配到各个executor上,但这种随机很可能会造成某些executor上的数据量远远大于其他executor的,从而引起数据倾斜。当我们结合业务了解到按个字段或规则可以让数据较为平均的分配到executor上时,就可以依靠Distribute By实现,从而最大限度使用计算资源。
另外,在Join的过程中,未使用Distribute By 的两个表,将各自的数据随机分配到executor上,当join的时候就会出现,跨executor的数据需要互相迁移进行匹配的情况,从而引起更大量的Shuffle。但如果我们将join的链接字段通过Distribute By 重分区,神奇的一幕将发生:需要互相匹配的数据都会在相同的executor上,从而避免跨executor的数据迁移,所有的匹配都在统一个executor上进行,这样就大大减少了Shuffle。
解决方案
综上,正确的重分区操作对于Join 表可以有效减少Shuffle操作。在前面查看Spark UI 与代码时,就发现 trx_id 是几个大表join的链接字段,所以最简单的方式就是使用 Distribute By trx_id 的方式建立好各个要Join的 temp view,最后在统一Join起来。整个代码逻辑如下:
# 设置并行度
set spark.sql.shuffle.partitions=800;
# 创建表1 view
create temporary view v1 as select .... DISTRIBUTE BY trx_id;
# 创建表2 view
create temporary view v2 as select .... DISTRIBUTE BY trx_id_2;
# 整合整个任务
insert overwirte table as
select ....
from v1
left join (select ... from v2 where ....) t2 on (v1.trx_id=t2.trx_id_2)
left join (select ... from v2 where ....) t3 on (v1.trx_id=t3.trx_id_2)
left join (select ... from v2 where ....) t4 on (v1.trx_id=t4.trx_id_2)
where ...
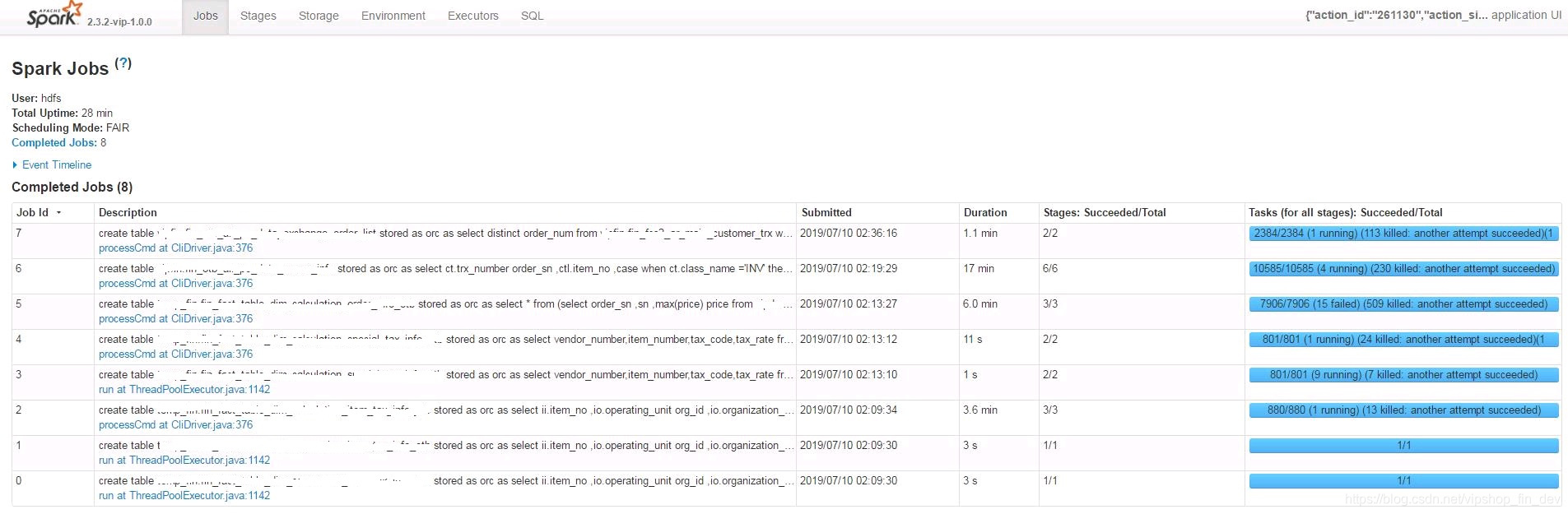
至此这个慢任务的优化完成,其效果如图,由一个多小时减少到了28分钟。
使用 BROADCAST 减少Shuffle
在另一个慢任务中,通过Spark UI 可以发现有些小表的Join操作也在读取后经过Shuffle与大表进行匹配。而这部分的优化实际可以通过Spark的 BROADCAST 方式将这些小表数据直接发到每个executor的内存中,使得在与大表Join的时候实现无Shuffle操作。进过这样的优化后,可以看到Spark UI里的图形变成如下图的方式,其中Join也变成了BroadcastHashJoin。
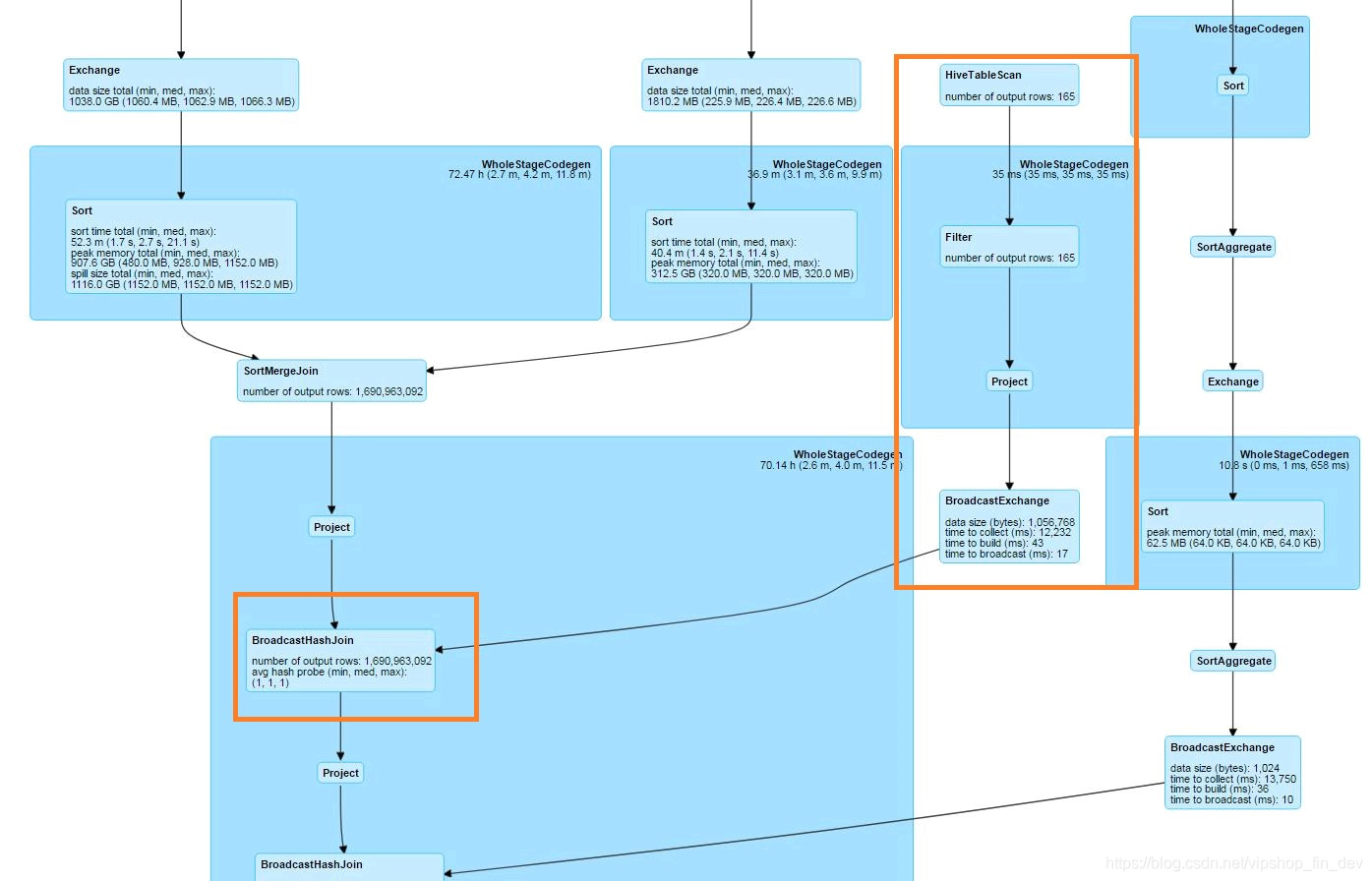
由图中,还可以看出,两个大表(非Broadcast)的Join操作都会先Sort然后进行SortMergeJoin,这时使用 Distribute By与Cluster By是没有区别的,因为Spark都会自动执行Sort操作。而且如果Join的表有一个是Broadcast的话,也是不需要Sort操作的,此时使用Distribute By能省去Sort的开销。所以大多数情况下建议使用 Distribute By。
那什么时候适合使用Cluster By呢?我想到一种情景就是当表的数据要多次按某个栏位分布后多次参与Join操作,且这个表能在重分区后固定下来才有意义,也意味着该表的数据量有一定量(比能使用Broadcast的量要大的多)且不至于过大(各executor的内存足够大能放得下),这时就可以使用 cache table 语句实现了:
cache table T1 as select ... from .... cluster by xxx
然后就可以在后续SQL中使用T1了。
后记
通过使用Distribute By、Cluster By与Broadcast方式对4个任务优化后,整体运行时间由4个多小时缩短到了1个半小时以内。
作者:侯嘉逊
