导语
时间飞梭而过,眼看这2018新年伊始,转眼间128大促已经落下帷幕,回顾过去的两周,协助大促监控和业务分析捞数竟然暂用了我大量的工作时间,期间不断的在用Hive SQL进行捞数分析,本着对工作认真负责的态度,对使用的语言做到知其然而知其所以然,最近好好的研究了一把Hive SQL的执行原理,以便写出性能更好的Hive SQL语句。
什么是Hive SQL?
地球人都知道,我就不说了,直接跳过。。。
Hive SQL就是今天的主题,以下主要分为两部分来阐述:
- Hive SQL执行原理
- Hive SQL优化技巧
1. 针对Hive SQL的执行原理主要可以分为三部分
HIve SQL执行一般会经几个步骤:
1.1 普通select语句的执行原理
背景:先来一个普通的Hive SQL的select语句,假设有个orders的订单明细表,我们希望获得iphone7的销售明细,那么Hive SQL只要一个简单的查询语句:
select * from orders where cate_name='iphone7';
其执行流程如下所示
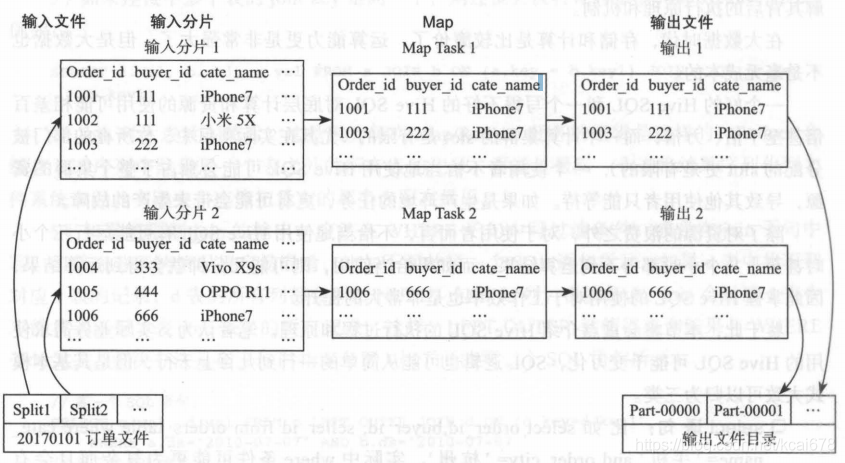
1.1.1 输入分片
根据输入数据的大小进行分片
1.1.2 Map阶段
Map任务的个数有输入的分片结算的个数决定;在Map阶段对分片文件中的每行进行检查过滤,并按指定的列保存到bending文件。
1.1.3 Shuffle&Reduce阶段
由于此Hive SQL是一个简单的过滤语句,不需要启动Shuffle&Reduce阶段,所以直接跳过
1.1.4 输出文件
Hadoop直接合并Map任务的输出文件到输出目录。像以上这个例子,只需要简单的合并并输出的最终目录即可。
[注:截图来自书籍《离线和实时大数据开发实战》]
1.2 group by语句的执行原理
背景:如果需要继续统计每个城市的iphone7销售数目,就必须使用group by,Hive SQL可以如下所示:
select city, count(1) city_cnt from orders where cate_name='iphone7'
group by city;
[注:截图来自书籍《离线和实时大数据开发实战》]
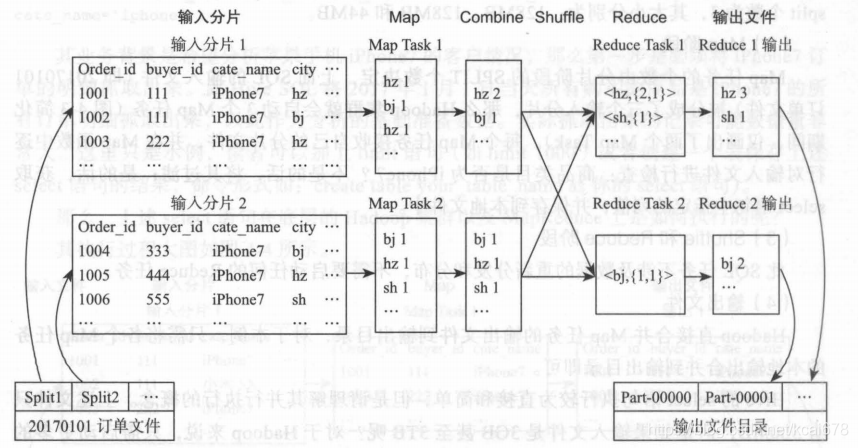
Hive SQL group by的执行过程,相对于普通的select SQL操作,中间插入了几个环节:
1.2.1 Combine阶段
将Map阶段的输出文件进行一定程度的合并。
1.2.2 Shuffle阶段
Map任务的输出必须进过一个名叫Shuffle的阶段才能交给Reduce任务去处理。Shuffle过程是MapReduce的核心。包含了分区、排序、分隔、复制和合并等过程,而一般分区的算法主要使用hash的来完成。这里值得一提的是Shuffle包含了Map端的Shuffle和Reduce端的shuffle,接下来这个概念我们在优化的时候会用到。
1.2.3 Reduce阶段
对于group by句,这里需要调用reduce函数逻辑将数据按照group by的字段进行汇总,并保留文件到bending中。
1.3 join语句的执行原理
背景:假设还有一个是购买用户信息表,我们希望了解购买iphone7的年龄情况,那么我们就得用到join表,具体Hive SQL大概如下所示:
select t1.*, t2.*
(
select * from orders where cate_name='iphone7'
) t1
join
(
select * from buyer where 1=1
) t2
on t1.buyer_id=t2.buyer_id
1.3.1 Hive SQL join的执行过程其实可以分解为3个MapReduce
- 获得t1的MapReduce
- 获得t2的MapReduce
- 获得最终结果的MapReduce
1.3.2 获得最终结果的MapReduce
最终的一次MapReduce是在t1&t2的基础上而来,根据关联的buyer_id进行Shuffle和Reduce操作,从而完成整个join的操作。此过程和group by类似,这里就不展开了。详细执行可以查看下图:
[注:截图来自书籍《离线和实时大数据开发实战》]

2. 数据倾斜
不过在说具体调优方法之前,我们先来看Hive SQL中调优的一个挑战:数据倾斜。什么是数据倾斜呢?所谓数据倾斜简单的理解就是在Hive SQL执行过程中的任何一个分片动作是如果数据分布式不均的情况。如果数据分布不均,那MapReduce分片并发处理的优势就无法体现,数据严重倾斜的分片就成为整个Hive SQL执行过程当中的关键路径;关键路径的性能低下就代表了整个Hive SQL执行效率的低下。所以基本上而已优化Hive SQL的思路就是在理解Hive SQL原理的情况下,尽量的避开数据倾斜从而提高并发,加快计算效率。
3. 具体优化方式
看过了执行原理之后,我们就可以对症下药说下如何调优了。而所谓的优化方法大致的可以分为几类:
- 关联(join)无关的优化
- 关联(join)相关的优化
3.1 关联(join)无关的优化
- group by的优化
背景:还是说回之前的订单明细表orders,假设我们需要通过供应商id进行group by来统计订单量。那这里就面临了一个问题,有的大供应商可能一天可以卖几百万单(夸张点哈哈哈),有些可能就可怜巴巴的就一两个订单,也就是说按照供应商id,势必会造成“数据倾斜”,那么整个Hive SQL的执行时间就有大供应商的执行时间所决定。
办法:针对这种case,比较好进行优化,只需要设置如下参数便可:
set hive.map.aggr=true
set hive.groupby.skewindata=true
-
count distinct的优化
背景:如果我要从订单明细表中统计有过少个供应商,那一般简单直接的办法是如下Hive SQL:select count(distinct vendor_id) from orders
这个SQL由于distinct需要去重,在Map阶段之后会把说有分片数据分布到一个Reduce上面,这样如果数据量一多很容易造成问题,经过改良的办法应该如下所示,利用group by去重,再统计group by的行数:
select count(*) from
(
select vendor_id from orders group by vendor_id
) t
关联(join)相关的优化
大小表关联查询优化
背景:继续上面的例子,假设每个供应商都有销售平台,比方说vip主站,MP,京东店铺等等,我们想要统计每个平台的订单数(假设有个表用来记录供应商对应的销售平台vendors),一般简单直接的SQL如下所示:
select b.platform, count(order_id) as order_cnt
from
(
select order_id, vendor_id from orders
) a
left outer join
(
select vendor_id, platform from vendors
) b
on a.verdor_id=b.verdor_id
group by b.platform
以上SQL按照vip销售的占比不同,极有可能造成数据倾斜。此种情况,如果在供应商数量不会太大的情况下,可以采用mapjoin语法进行优化,具体SQL如下所示:
select /\*+mapjoin(b)\*/
b.platform, count(order_id) as order_cnt
from
(
select order_id, vendor_id from orders
) a
left outer join
(
select vendor_id, platform from vendors
) b
on a.verdor_id=b.verdor_id
group by b.platform
上面的情况就是典型的大表关小表,orders明细是大表,而供应商信息表是典型的小表。此种方法加上mapjoin(b),是调整了执行过程,让Hive SQL在Map阶段进行job,而不是像上面所说在Reduce阶段才进行join列的操作。极端情况下,Hive能够将小表的数据copy到各个分片,直接进行lookup,速度更快。这样,在后期的Shufle&Reduce阶段就可以大大较少shuffle带来的IO网络开销,只是做一些简单的Redule,大大提高性能。
大大表关联查询优化
背景:还是同样orders,vendors表,我们现在要统计每个用户在各种平台的订单数,一般正常的sql应该如下:
select
a.user_id,
sum(1) as order_cnt
sum(case when b.platform='vip' then 1 end) as vip_order_cnt,
sum(case when b.platform='jingdong' then 1 end) as jingdong_order_cnt,
sum(case when b.platform='marketplace' then 1 end) as marketplace_order_cnt
from
(
select user_id, order_id, vendor_id from orders
) a
left outer join
(
select vendor_id, platform from vendors
) b
on a.verdor_id=b.verdor_id
group by user_id
同样的道理,大的供应商会造成数据倾斜;而假设现在的情况还复杂一点,供应商的数据表也有上千万的数据,那么数据都有可能超过了几个G,就无法沿用上面大表join小表的通过mapjoin的方式进行优化,那该这么办呢?没事接着往下走
转化为大小表关联查询
一个正常优化的思路是,由于b表无法通过mapjoin优化,那我们就将b表优化成能够使用mapjoin的方式。优化的办法自然就是通过是用减少数据行或者数据列的方式实现。
- 减少数据行的方式:
比方说我们可以通过orders表中是否最近成过单的方式来过滤数据,SQL如下:
select /*+mapjoin(b)*/
a.user_id,
sum(1) as order_cnt
sum(case when b.platform='vip' then 1 end) as vip_order_cnt,
sum(case when b.platform='jingdong' then 1 end) as jingdong_order_cnt,
sum(case when b.platform='marketplace' then 1 end) as marketplace_order_cnt
from
(
select user_id, order_id, vendor_id from orders
) a
left outer join
(
select vendor_id, platform from vendors b0
join
(select verndor_id from verdors group by vendor_id) a0
on b0.vendor_id=a0.vendor_id
) b
on a.verdor_id=b.verdor_id
group by user_id
需要注意的是,以上方法能否奏效可能更数据分布有关,如果大大小小的供应商都成过单了,过滤效果就不好,这时我们就得通过另外一种通用方式了,各位客官,请接着看。。。
削峰数据倾斜,放大维度再取模关联
- 通用方案
我们接着优化,如上文中提到,所谓的Hive SQL优化归根结底就是要消灭数据倾斜,这里提供了一种思路,如果我们针对数据倾斜的数据我们通过取模的方式将其数据平分到10,100,或者1000个分片中,那不就是相当于削峰操作了,那就消灭了数据不均的问题了。Hive SQL大致应该如下:
select
a.user_id,
sum(1) as order_cnt
sum(case when b.platform='vip' then 1 end) as vip_order_cnt,
sum(case when b.platform='jingdong' then 1 end) as jingdong_order_cnt,
sum(case when b.platform='marketplace' then 1 end) as marketplace_order_cnt
from
(
select user_id, order_id, vendor_id from orders
) a
left outer join
(
select /*+mapjoin(n0)*/
b0.vendor_id, b0.platform, n0.number from vendors b0
join tmp_numbers n0
) b
on a.verdor_id=b.verdor_id
and mod(a.order_id)=b.number
group by user_id
说明一下,这个tmp_numbers的表是一个临时表,只有10行记录,一个列number,对应的值依次为1,2,3,4…10.
- 继续微调优化
上面的通用方式已经接近完美的将数据倾斜给削平了,但你想想那些小供应商订单量的数据也被平分为10,100或者1000个了,其实没必要。这里如果有有个供应商订单量近似的统计表,那我们就可以分开处理,通过case when等方式判断只有大供应商的数据才进行削峰操作,其它的保持不变,那性能就进一步提升了,由于实现思路已经明了,这里就不展开了。
动态一分为二
和上面的微调优化方式有异曲同工之妙的优化方式,我们打供应商和小供应商区别对待,用完整的两种方式来处理,而最终将结果union all起来就是,大致Hive SQL如下:
select
user_id,
sum(1) as order_cnt
sum(case when platform='vip' then 1 end) as vip_order_cnt,
sum(case when platform='jingdong' then 1 end) as jingdong_order_cnt,
sum(case when platform='marketplace' then 1 end) as marketplace_order_cnt
from
(
select a.user_id, a.order_id, a.vendor_id, b.platform
(
select user_id, order_id, vendor_id from orders
) a
left outer join
(
select vendor_id, platform from vendors v0
left outer join
tmp_vendor_gt_1w w0
on v0.vendor_id=w0.vendor_id
where w0.vendor_id is null
) b
on a.verdor_id=b.verdor_id
union all
select /*+mapjoin(b)*/
a.user_id, a.order_id, a.vendor_id, b.platform
(
select user_id, order_id, vendor_id from orders
) a
left outer join
(
select vendor_id, platform from vendors v0
join
tmp_vendor_gt_1w w0
on v0.vendor_id=w0.vendor_id
) b
on a.verdor_id=b.verdor_id
)
group by user_id
- 说明一下,假设我们将超过1w单的供应商统计出来并保存在一个中间表tmp_vendor_gt_1w。这里一分为二,如果不在中间1w表的可以直接join表生成;如果在1w表的会造成数据倾斜的用mapjoin加速性能,这样就达到了优化的效果了。
结语,Hive SQL的优化就是发现数据倾斜,然后通过各种方式避免数据倾斜,高效的利用Hadoon的MapReduce并发特性,提高性能。
参考文章及书记如下:
- https://www.cnblogs.com/liuwei6/p/6706415.html
- https://www.2cto.com/net/201701/585250.html
- https://blog.csdn.net/u010738184/article/details/70893161
- 《离线和实时大数据开发实战》- 机械工业出版社
作者:蔡恒旋
