哈希表的介绍
数组和链表在保存数据的时候,一般不会对数据的性质来决定数据存放的顺序,所以他们在查询数据的时候,只能够通过从前往后遍历,从而查找到想应的数据;
例如在一个int数组[12,34,56,324,24387]里查询是否存在关键字324时,我们只能够从第0位往后查询,然后查询到324,他的效率是o(n);链表也和数组类似。
对于二叉搜索树和红黑树,他们是根据数据的大小来保存数据的,利用了数据的性质,所以他们在查找的效率上远高于数组和链表;
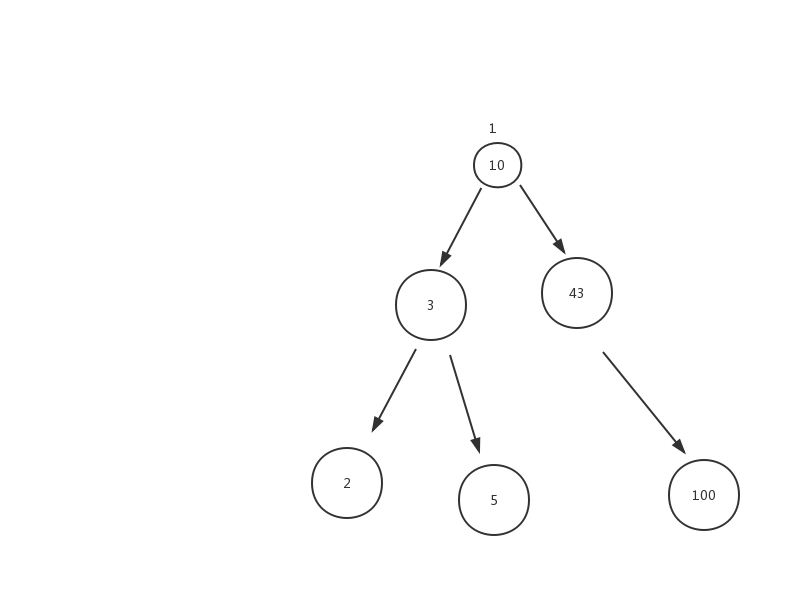
例如对如图的二叉树,在查找数组5的时候,先和10比较,然后和3比较,最终找到5,他的查询效率是o(h),其中h是二叉树的高度,而二叉树高度期望位ln(n),红黑树为ln(n),所以他们的查询效率远高于数组和链表。
然而二叉搜索树和红黑树只利用了数据之间的大小关系。如果我们直接根据数据的性质,将其放在指定位置,那样查询效率才是最高的。
先考虑最简单的情况,我们要保存0-99的数据,那么我们使用一个长度为100的数组来保存,然后将0保存在第0位,1保存在第1位,99保存在最后一位,那么理论上我们的查找性能就是o(1),因为我们只需要关注对应的位数是否存在数据就好。
public interface Entry<K,V> {
K getKey();
V getValue();
}
public class SimpleEntry implements Entry<Integer,String> {
private Integer key;
private String value;
public SimpleEntry() {
}
public SimpleEntry(Integer key, String value) {
this.key = key;
this.value = value;
}
@Override
public Integer getKey() {
return key;
}
@Override
public String getValue() {
return value;
}
@Override
public String toString() {
return "SimpleEntry{" +
"key=" + key +
", value='" + value + '\'' +
'}';
}
}
public class SimpleMap {
private Entry<Integer, String>[] data;
public SimpleMap() {
this.data = new SimpleEntry[100];
}
public void put(Integer key, String value) {
data[key] = new SimpleEntry(key, value);
}
public String get(Integer key) {
Entry<Integer, String> entry = data[key];
if (entry != null) {
return entry.getValue();
}
return null;
}
}
public class Test {
public static void main(String[] args) {
SimpleMap simpleMap = new SimpleMap();
simpleMap.put(10,"adj");
simpleMap.put(13,"dfh45");
simpleMap.put(23,"453vete");
simpleMap.put(67,"459vrj");
simpleMap.put(49,"547843vnrmd");
System.out.println(simpleMap.get(13));
System.out.println(simpleMap.get(67));
System.out.println(simpleMap.get(1));
}
}
//输出
dfh45
459vrj
null
如上代码就是实现了一个极其简单的hash表保存数据。
但是我们通常保存的数据key一般远不止100个,我们不可能创建一个那么大的数组,而且通常保存的数据量也远小于key的可能取值,创建那么大的数组浪费空间。
为了解决这种状况,先贤们就想出了用哈希函数来解决这个问题,具体而言,就是将无穷的key的集合映射到一个槽k里,之后保存具体的数据时,先计算出其的hash值,然后保存到hash值对应的槽位里。
那么这就存在一个问题了,就是如果两个可以的hash值相同,我们该如何解决。
最理想的方法是避免冲突,但这是不可能的,所以要让hash值尽可能随机,降低冲突的概率,然后当冲突了的时候,也有办法去解决。
解决冲突有两种办法链接法和开放寻址法,下面我们来分别介绍这两种解决冲突的办法。
开放寻址法
开放寻址法解决冲突的思路很简单,当插入一条数据的时候,如果计算出的hash值对应的槽位已经被其他key占用了,那么按照一定的规则去寻找另一个槽位,知道找到相应的位置即可。
这里介绍一种最简单的开放寻址法,就是如果槽位被占用,就去寻找相邻的下一个槽位,且hash值也直接选用除以100后的余数:
public class SimpleMap2 {
private Entry<Integer, String>[] data;
public SimpleMap2() {
this.data = new SimpleEntry[100];
}
public void put(Integer key, String value) {
int index = hash(key);
Entry<Integer, String> entry = null;
while ((entry = data[index]) != null
&& !entry.getKey().equals(key)) {
index = getNextIndex(index);
}
//这个时候要么data[index]为空,要么data[index]保存的值key等于传入的key
data[index] = new SimpleEntry(key, value);
}
public String get(Integer key) {
int index = hash(key);
Entry<Integer, String> entry = null;
while ((entry = data[index]) != null) {
if (entry.getKey().equals(key)){
return entry.getValue();
}
index = getNextIndex(index);
}
return null;
}
private int hash(Integer key) {
return key % 100;
}
private int getNextIndex(int index) {
return index + 1;
}
}
SimpleMap2 simpleMap2 = new SimpleMap2();
simpleMap2.put(10,"adj");
simpleMap2.put(110,"dfh45");
simpleMap2.put(11,"453vete");
simpleMap2.put(4,"459vrj");
simpleMap2.put(347,"547843vnrmd");
System.out.println(simpleMap2.get(110));
System.out.println(simpleMap2.get(4));
System.out.println(simpleMap2.get(1));
//输出
dfh45
459vrj
null
可以看到寻址的规则和hash函数选取的都极为简单,且我们只考虑了key为int数的情况,然而在实际的编码中,我们能够将任何对象先转化为int值,再计算出对应的hash值,而将对象转化为int值的函数,在Java里就是hashCode函数,他的默认实现是基于对象的内存地址的。
链接法
链接法解决冲突的思路也很简单,就是在每一个槽位保存一个链表(或者其他数据结构),直接将hash相同的数据存到一个链表上就好。
具体到Java的HashMap,它就是使用链接法来解决冲突的。所以我们这里不实现这种方法,等到下一篇介绍HashMap的时候在具体的体会链接法。
不管是链接法和开放寻址法,他们都能解决冲突,但是我们要认识到,虽然他们解决了冲突,但在hash冲突的量非常大的时候,他们的性能也会显著的下降,所以一般在插入的数据量比较大的时候,会重新选取hash函数,新的hash函数有跟多的槽位,从而降低冲突的概率,这个过程称为rehash过程。这个的具体实现也等到HashMap源码解读的时候在具体介绍。
