java中集合框架其实就是数据结构的实现的封装;
参考资料:任小龙教学视频
1,什么是数据结构?
数据结构是计算机存储,组织数据的方式;
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合;
通常情况下,精心选择的数据结构可带来更高的运行或者存储效率,
数据结构往往同高效的检索算法和索引技术有关;
2,数据结构的基本功能
增(Create) 删(Delete) 改(Update) 查(Read)
3,常见的数据结构

3.1,数组Array;
数组是最简单的数据结构;是用来存放同一种数据类型的集合.
从增删改查分析数组的性能:
增:在数组的最后一个位置添加元素是很方便的,但是要是想在第一个位置添加元素就很麻烦了,后面的所有元素都要整体后移,容量不够还要进行扩容;
删:把数组的最后一个元素删除是很方便的,但是要删除第一个位置的元素就很麻烦,后面的所有元素都要整体前移;
改:修改指定下标的元素只要操作一次即可;
查:如果查询指定下标的元素只要操作一次即可,如果查询指定元素的下标,此时需要使用线性搜索(挨个找),
综上:数组的改查性能比较高,增删性能比较低;
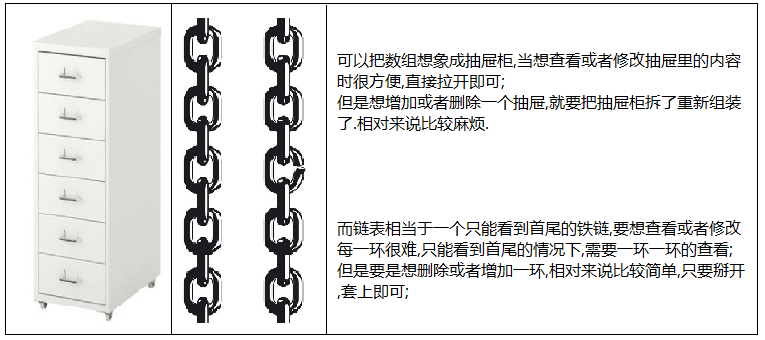
3.2链表Linked List;
链表是通过引用来表示上一个节点和下一个节点的关系;
1》单点链表// 只能从头遍历到尾/只能从尾遍历到头

通过next存储下一个节点,Node next表示的就是下一个节点;
2》双向列表// 既可以从头遍历到尾,也能从尾遍历到头
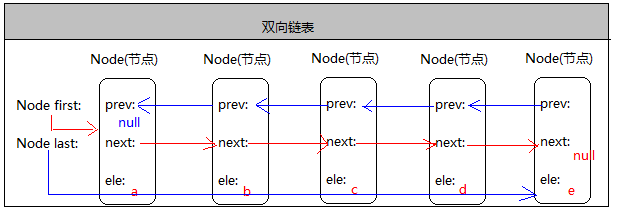
通过prev表示上一个节点,Node prev表示的是上一个节点;
从增删改查分析链表的性能:
增:双向链表可以直接获取第一个节点和最后一个节点.如果新增的元素在第一个位置或者最后一个位置,则操作只有一次;
删:把第一个元素或者最后一个元素删除只要操作一次;
改:不存在下标的概念,需要进行遍历;
查:不存在下标的概念,需要进行遍历;
综上:链表的增删性能较高,改查性能较低;
3.3栈Stack;
是一种运算受限的线性表,后进先出(LIFO);
仅允许在列表的一端添加和删除元素,这一端被称为栈顶,相对的把另一端称为栈底
向一个栈中添加元素,又称为压栈或者进栈或者入栈,他是把新元素放在栈顶元素的上面,使之成为新的栈顶元素;
从一个栈删除元素,又称之为出栈,他是把栈顶元素删掉,使之相邻的元素成为栈顶元素;
栈是基于数组实现的,下标为0的元素就是栈底元素,最后一个元素就是栈顶元素;
3.4队列Queue;
队列是一种特殊的线性表,特殊之处在于,只允许表的前端进行删除操作,表的后端进行添加操作
和栈一样,队列是一种受限的线性表
进行插入操作的端称为队尾,进行删除操作的端称为队头;
单向队列:先进先出(FIFO)只能从队列尾插入数据,只能从队列头删除数据;
双向队列:既可以从队列尾/头插入数据,也可以从队列头/尾删除数据;
3.5哈希表Hash
在一般的数组中,元素在数组中的下标位置是随机的,元素的取值和元素的位置之间存在不确定的关系;
因此数组在查找值时,需要把查找值和一系列的元素进行比较;此时的查询效率依赖于查找过程中所进行的比较次数;
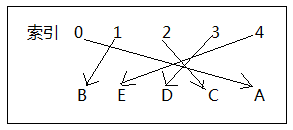
如果元素的值(value)和数组中的下标(index)有一个确定的对应关系(hash),
公式:index = hash(value);
这样的数组就称之为哈希表,哈希表最大的用处就是提供查找数据的效率;
一般情况不会把哈希码(hashCode)作为数组元素的下标,因为哈希码较大,容易越界;可以在哈希码和下标之间做映射关系,
数组会记录元素的添加顺序,并且允许元素重复;
哈希表不会记录元素的添加顺序(哈希算法进行排序使之一一对应),不允许重复,原因是:如果元素重复,导致哈希码值相等,导致下标相等