- 1)创建索引(使用6.0.0的方式创建)
pom.xml
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!-- http://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>6.0.0</version>
</dependency>
<!-- http://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>6.0.0</version>
</dependency>
<!-- http://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>6.0.0</version>
</dependency>
<!-- http://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.5</version>
</dependency>
</dependencies>IndexRepository.java
import java.io.File;
import java.io.IOException;
import java.nio.file.Path;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* 索引存储
*/
public class IndexRepository {
// 注意:此处使用的是Lucene6.0.0最新版本与4.X版本有一些区别,可以查看源码或者API进行了解
public static void main(String[] args) throws IOException {
// 指定索引库的存放路径,需要在系统中首先进行索引库的创建
// 指定索引库存放路径
File indexrepository_file = new File("此处是索引存放地址");
Path path = indexrepository_file.toPath();
Directory directory = FSDirectory.open(path);
// 读取原始文档内容
File files = new File("此处是源文件地址");
// 创建一个分析器对象
// 使用标准分析器
Analyzer analyzer = new StandardAnalyzer();
// 创建一个IndexwriterConfig对象
// 分析器
IndexWriterConfig config = new IndexWriterConfig(analyzer);
// 创建一个IndexWriter对象,对于索引库进行写操作
IndexWriter indexWriter = new IndexWriter(directory, config);
// 遍历一个文件
for (File f : files.listFiles()) {
// 文件名
String fileName = f.getName();
// 文件内容
@SuppressWarnings("deprecation")
String fileContent = FileUtils.readFileToString(f);
// 文件路径
String filePath = f.getPath();
// 文件大小
long fileSize = FileUtils.sizeOf(f);
// 创建一个Document对象
Document document = new Document();
// 向Document对象中添加域信息
// 参数:1、域的名称;2、域的值;3、是否存储;
Field nameField = new TextField("name", fileName, Store.YES);
Field contentField = new TextField("content", fileContent , Store.YES);
// storedFiled默认存储
Field pathField = new StoredField("path", filePath);
Field sizeField = new StoredField("size", fileSize);
// 将域添加到document对象中
document.add(nameField);
document.add(contentField);
document.add(pathField);
document.add(sizeField);
// 将信息写入到索引库中
indexWriter.addDocument(document);
}
// 关闭indexWriter
indexWriter.close();
}
}运行结果:
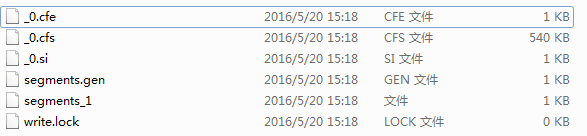
- 2)创建索引(使用4.10.3的方式创建)
pom.xml
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!-- http://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.5</version>
</dependency>
<!-- http://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.3</version>
</dependency>
<!-- http://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.10.3</version>
</dependency>
<!-- http://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.10.3</version>
</dependency>
</dependencies>IndexRepository.java
import java.io.File;
import java.io.IOException;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* 索引的创建
*/
public class IndexRepository {
public static void main(String[] args) throws IOException {
Directory directory = FSDirectory.open(new File("此处是索引文件存放地址"));
File files = new File("此处是源文件地址");
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(directory,config);
for (File f : files.listFiles()) {
// 文件名
String fileName = f.getName();
// 文件内容
@SuppressWarnings("deprecation")
String fileContent = FileUtils.readFileToString(f);
// 文件路径
String filePath = f.getPath();
// 文件大小
long fileSize = FileUtils.sizeOf(f);
// 创建一个Document对象
Document document = new Document();
// 向Document对象中添加域信息
// 参数:1、域的名称;2、域的值;3、是否存储;
Field nameField = new TextField("name", fileName, Store.YES);
Field contentField = new TextField("content", fileContent , Store.YES);
// storedFiled默认存储
Field pathField = new StoredField("path", filePath);
Field sizeField = new LongField("size", fileSize, Store.YES);
// 将域添加到document对象中
document.add(nameField);
document.add(contentField);
document.add(pathField);
document.add(sizeField);
// 将信息写入到索引库中
indexWriter.addDocument(document);
}
indexWriter.close();
}
} 3)查询索引库
import java.io.File;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* 文档搜索
* 通过关键词搜索文档
*
*/
public class DocSearch {
public static void main(String[] args) throws IOException {
// 打开索引库
// 找到索引库的位置
Directory directory = FSDirectory.open(new File("此处是索引文件存放地址"));
IndexReader indexReader = DirectoryReader.open(directory);
// 创建一个IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 创建一个查询对象
TermQuery query = new TermQuery(new Term("name","apache"));
// 执行查询
// 返回的最大值,在分页的时候使用
TopDocs topDocs = indexSearcher.search(query, 5);
// 取查询结果总数量
System.out.println("总共的查询结果:" + topDocs.totalHits);
// 查询结果,就是documentID列表
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 取对象document的对象id
int docID = scoreDoc.doc;
// 相关度得分
float score = scoreDoc.score;
// 根据ID去document对象
Document document = indexSearcher.doc(docID);
System.out.println("相关度得分:" + score);
System.out.println("");
System.out.println(document.get("name"));
System.out.println("");
// 另外的一种使用方法
System.out.println(document.getField("content").stringValue());
System.out.println(document.get("path"));
System.out.println();
System.out.println("=======================");
}
indexReader.close();
}
}运行结果:
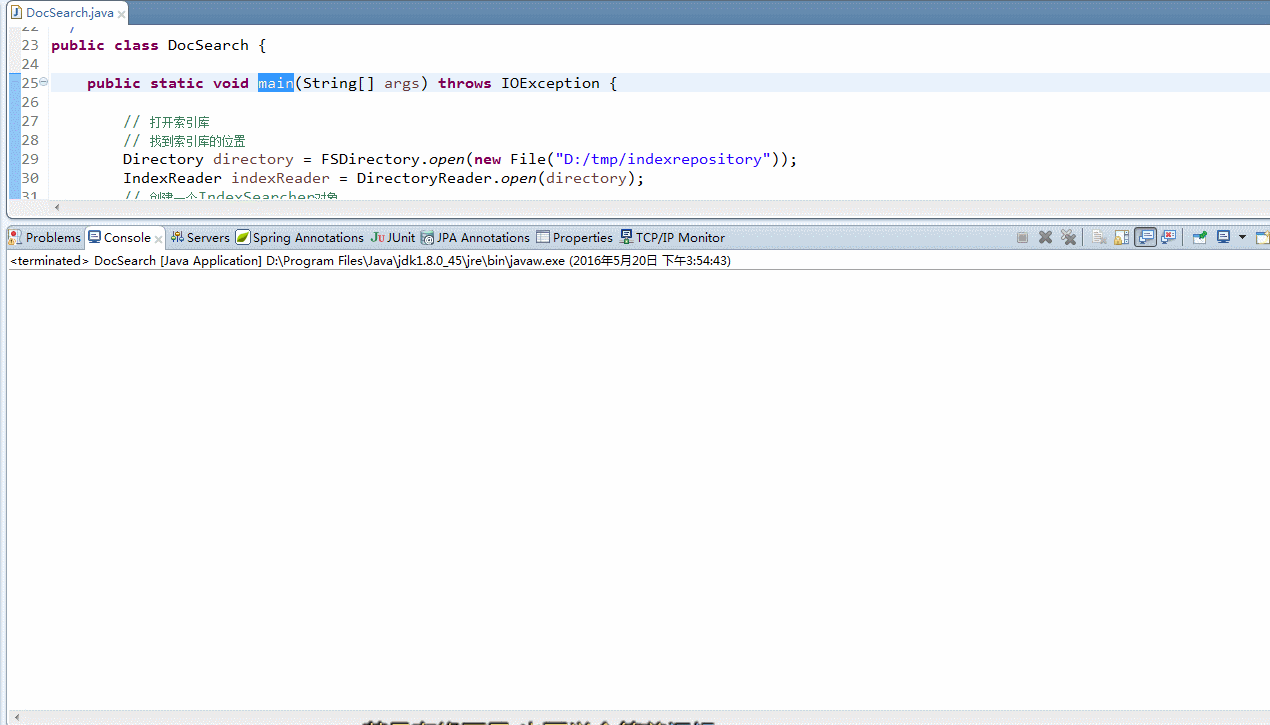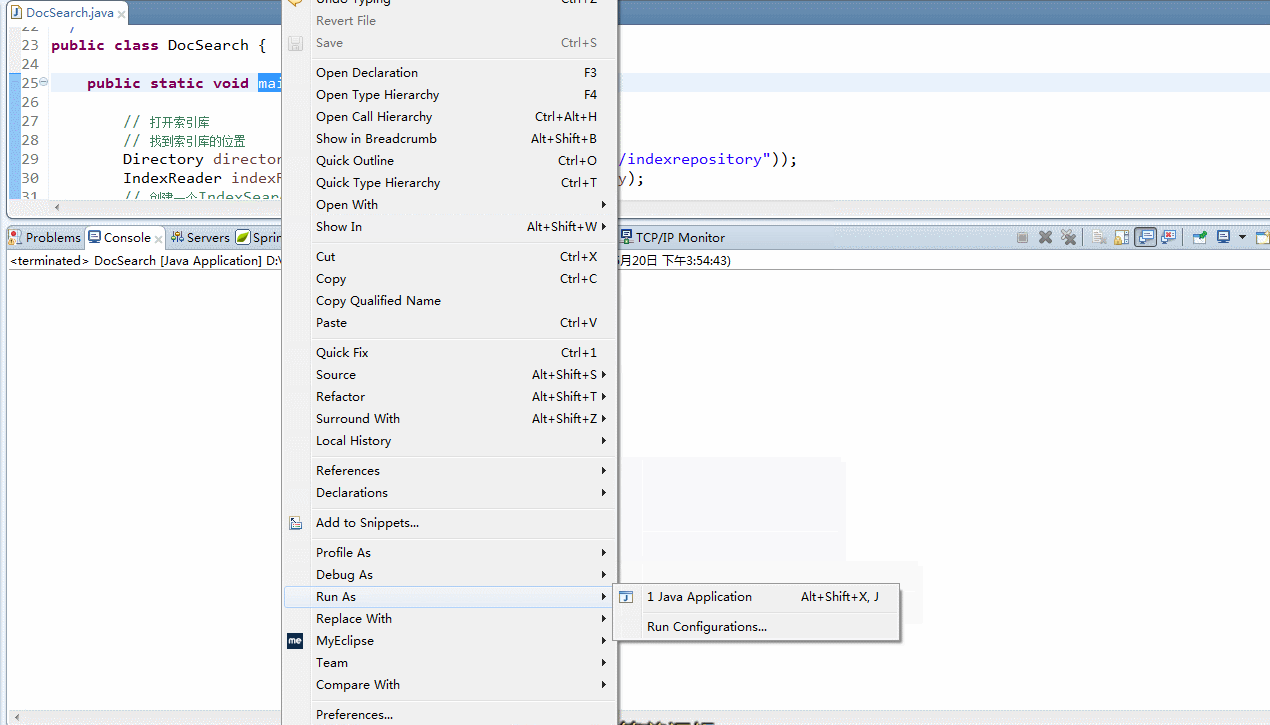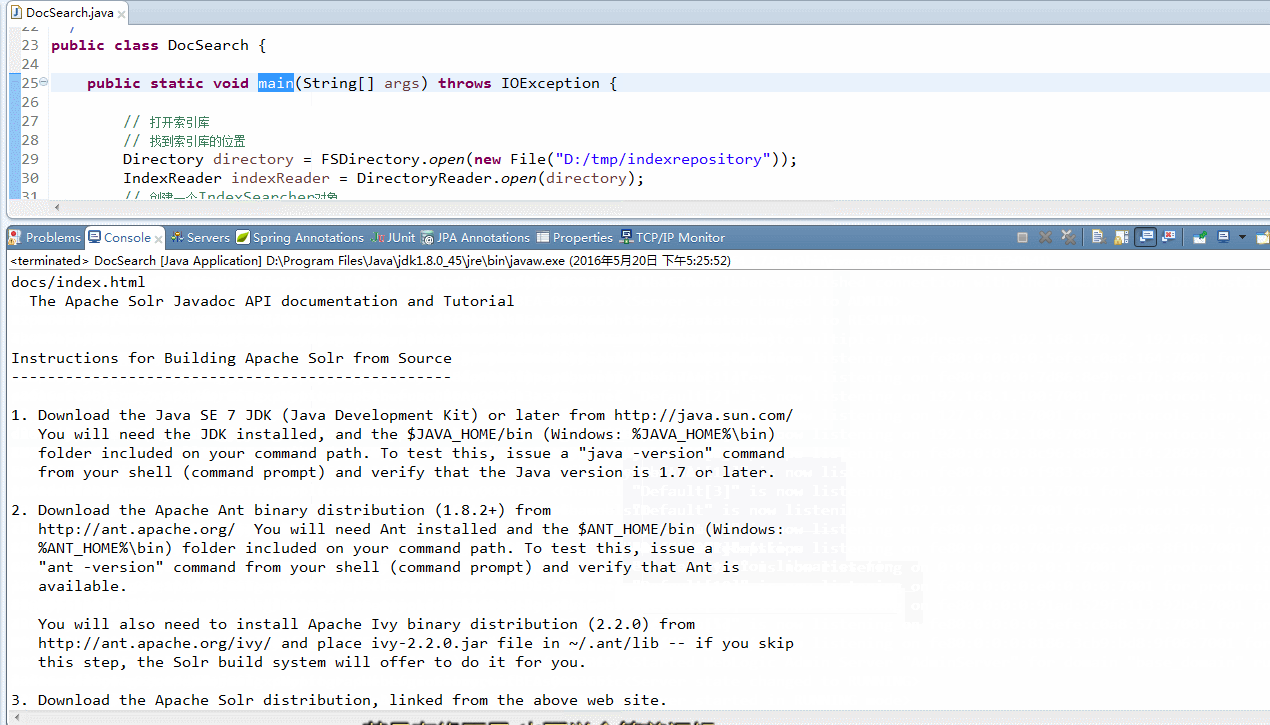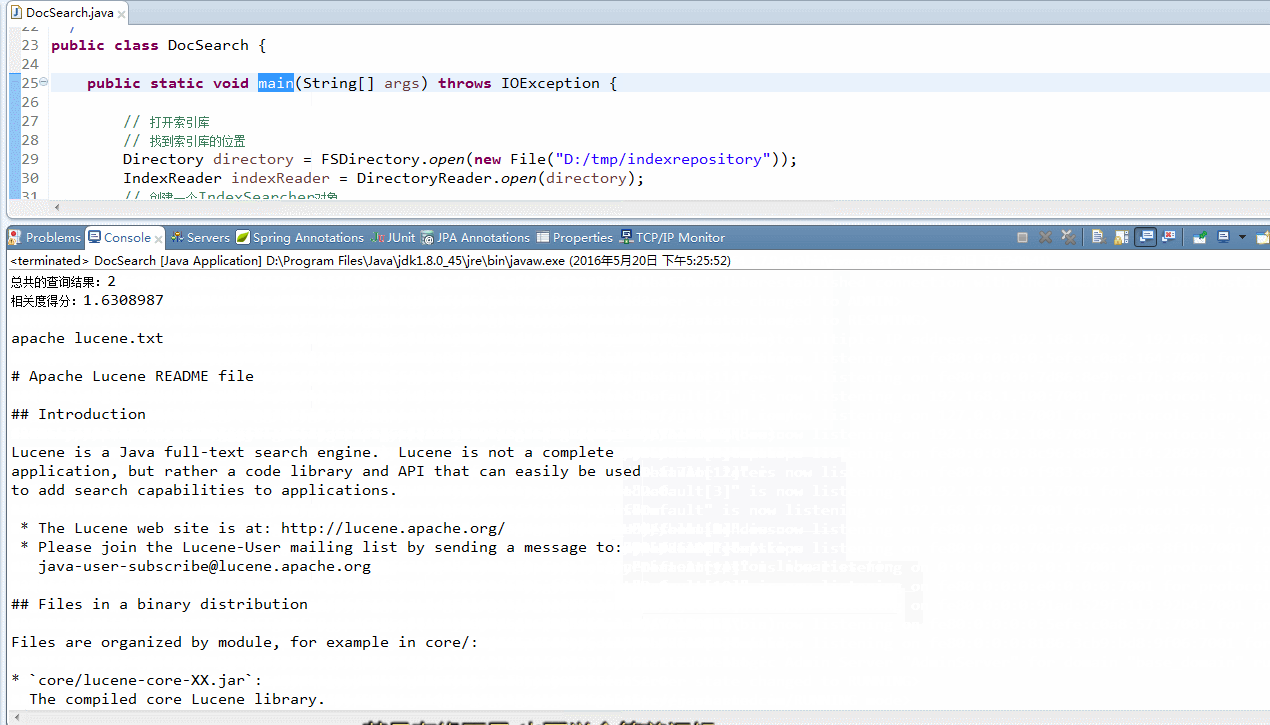
本文截取自:https://blog.csdn.net/yangqian201175/article/details/51462413