近年来随着大数据不断升温,并行数据分析变得越来越流行,各种分布式计算框架应运而生。Spark最早起源于加州大学伯克利分校AMP实验室的一个研究项目,实验室的研究人员曾经使用过Hadoop MapReduce,他们发现MapReduce在迭代计算和交互计算的任务上效率表现不佳,因此Spark从一开始就是为交互式查询和迭代算法设计的,同时还支持内存式储存和高效的容错机制。 Spark作为下一代大数据处理引擎,在非常短的时间里崭露头角,并且以燎原之势席卷业界。本篇主要介绍了如何使用IDEA在本地打包Spark应用程序(以K-Means为例),并提交到集群执行。
1、 安装JDK与Scala SDK
JDK和Scala SDK的安装在这里不再赘述,需要注意的是:要设置好环境变量,这样新建项目时就能自动检测到对应的版本,同时版本最好不要太高,以避免版本不兼容的问题,本篇采用的是JDK 8.0与Scala 2.10.6。
JDK下载地址:http://www.oracle.com/technetwork/java/javase/downloads/
Scala下载地址:http://www.scala-lang.org/download/
2、 安装IDEA
IDEA 全称 IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一, IDEA每个版本提供Community(社区版)和Ultimate(商业版)两个edition,其中Community是完全免费的,Ultimate版本可以试用30天,下载地址:http://www.jetbrains.com/idea/download/
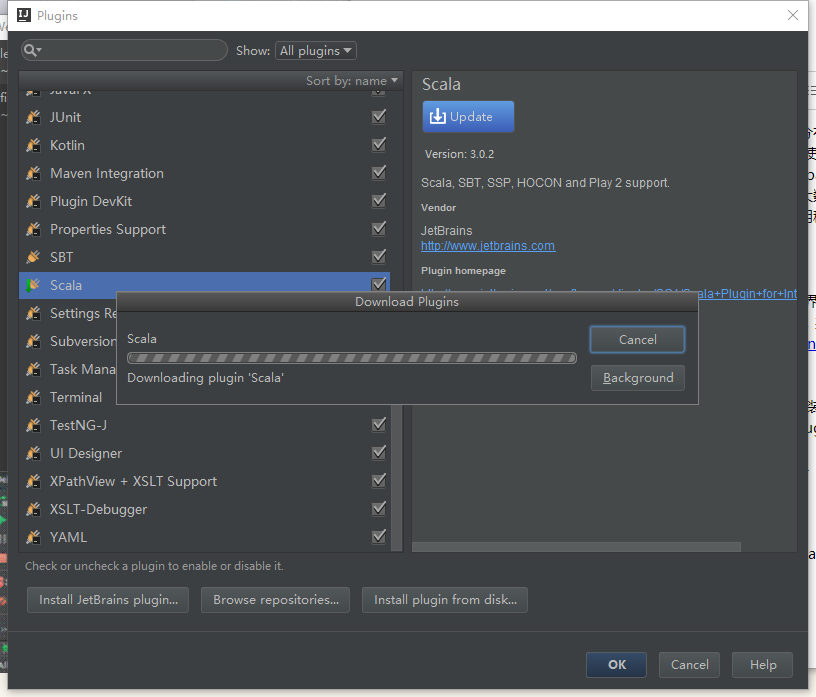
2.1 安装Scala插件
根据安装向导安装好IDEA后,需要安装scala插件,有两种途径可以安装scala插件(本篇已经安装好了scala插件,故在这一步作更新):
- 启动IDEA -> Welcome to IntelliJ IDEA -> Configure -> Plugins -> Install JetBrains plugin… -> 找到scala后安装。
- 启动IDEA -> Welcome to IntelliJ IDEA -> Open Project -> File -> Settings -> plugins -> Install JetBrains plugin… -> 找到scala后安装。
2.2 设置IDEA风格
如果想使用那种酷酷的黑底界面,可以在File -> Settings -> Appearance -> Theme选择Darcula,保存后重新进入即可。
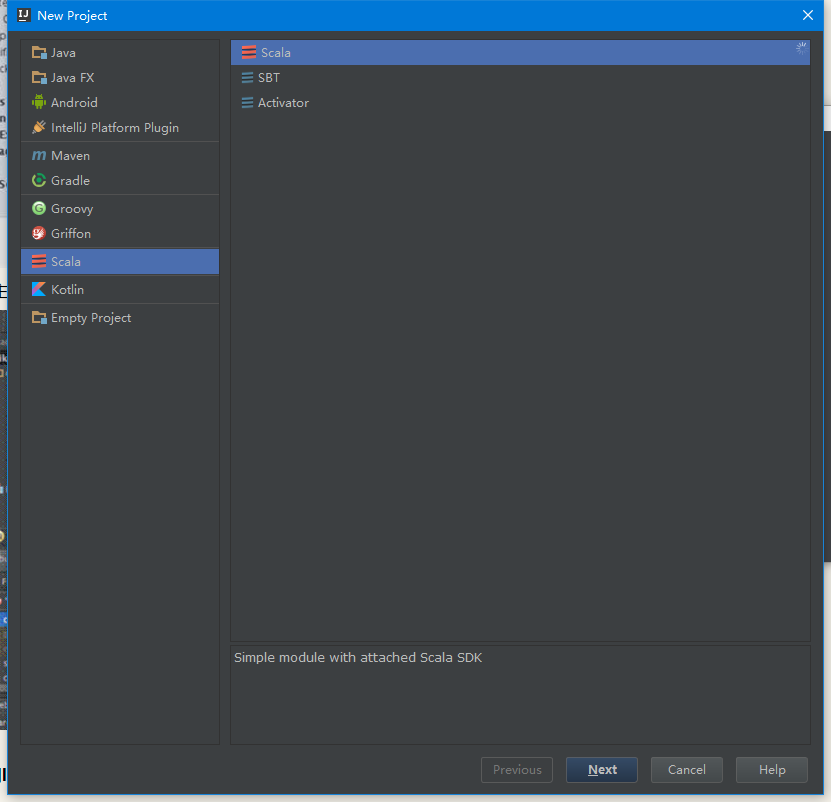
3、 新建Scala项目
3.1 单击file->new project,选择Scala,如果没有安装scala插件就没有这个选项,在项目的基本信息中填写项目名称、项目所在位置以及对应的Project SDK和Scala SDK(环境变量配置好了会自动匹配)。
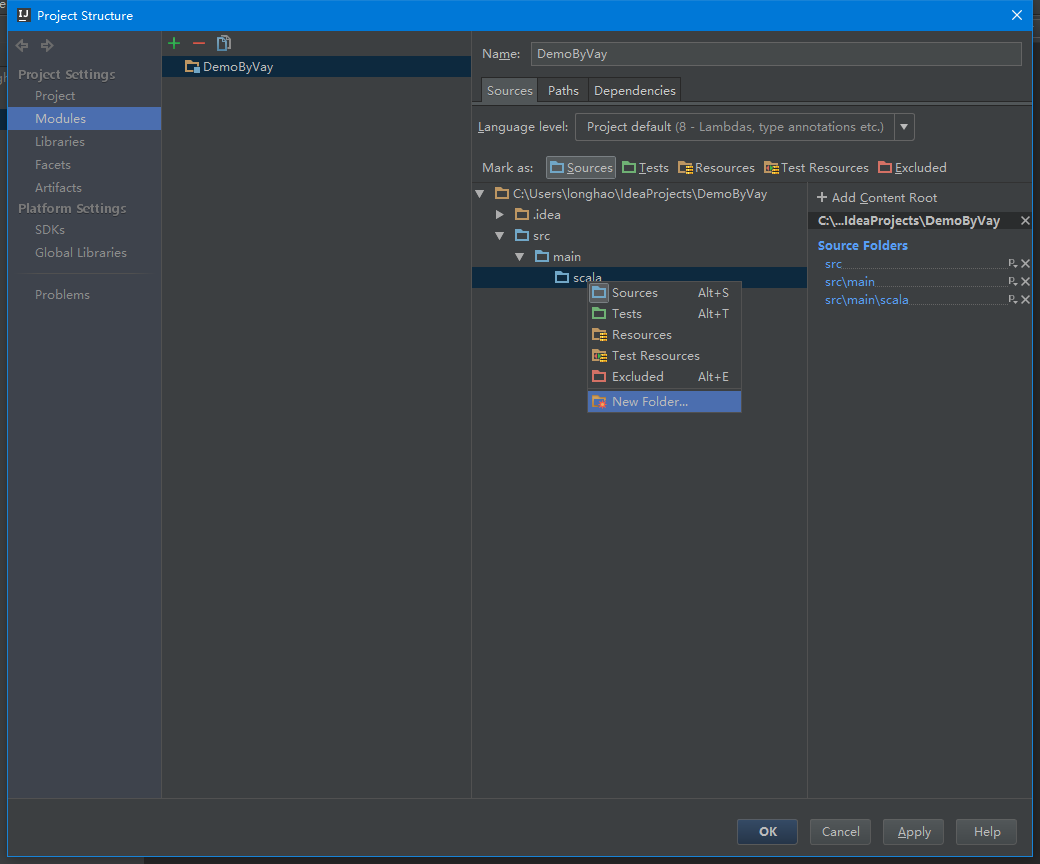
3.2 设置项目structure
创建好项目后,可以看到现在还没有源文件,只有一个存放源文件的目录src以及存放工程其他信息的杂项。通过双击src目录或者点击菜单上的项目结构图标可以打开项目配置界面,src单击右键选择“new folder”添加src->main->scala,并设置为Sources类型,如下图所示:
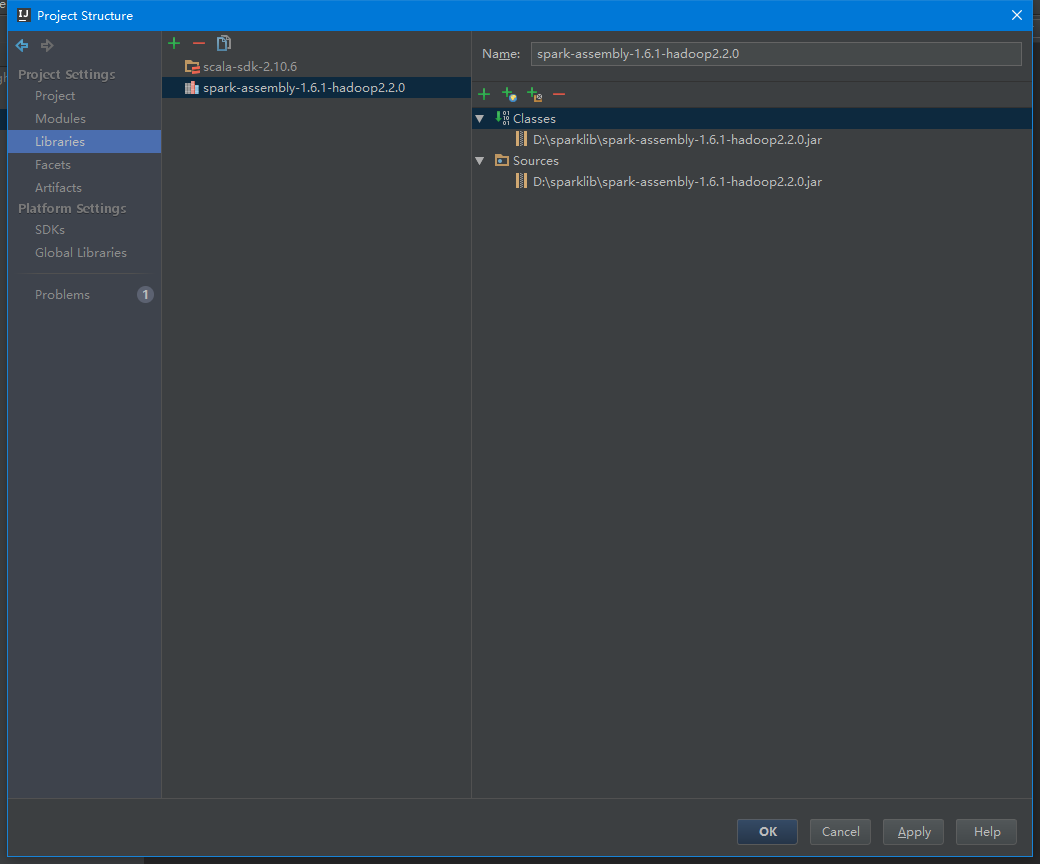
3.3 配置Library
- 选择Libraries目录,添加Scala SDK Library,这里选择scala-2.10.6版本。
- 添加Java Library,选择spark-assembly-1.6.1-hadoop2.2.0.jar(在spark的lib中可以找到),本篇将一些常用的JAR包放到了一个文件夹,故在此添加的是sparklib。
3.4 编写程序
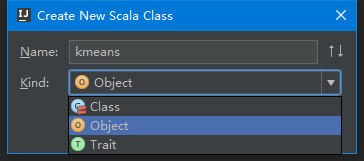
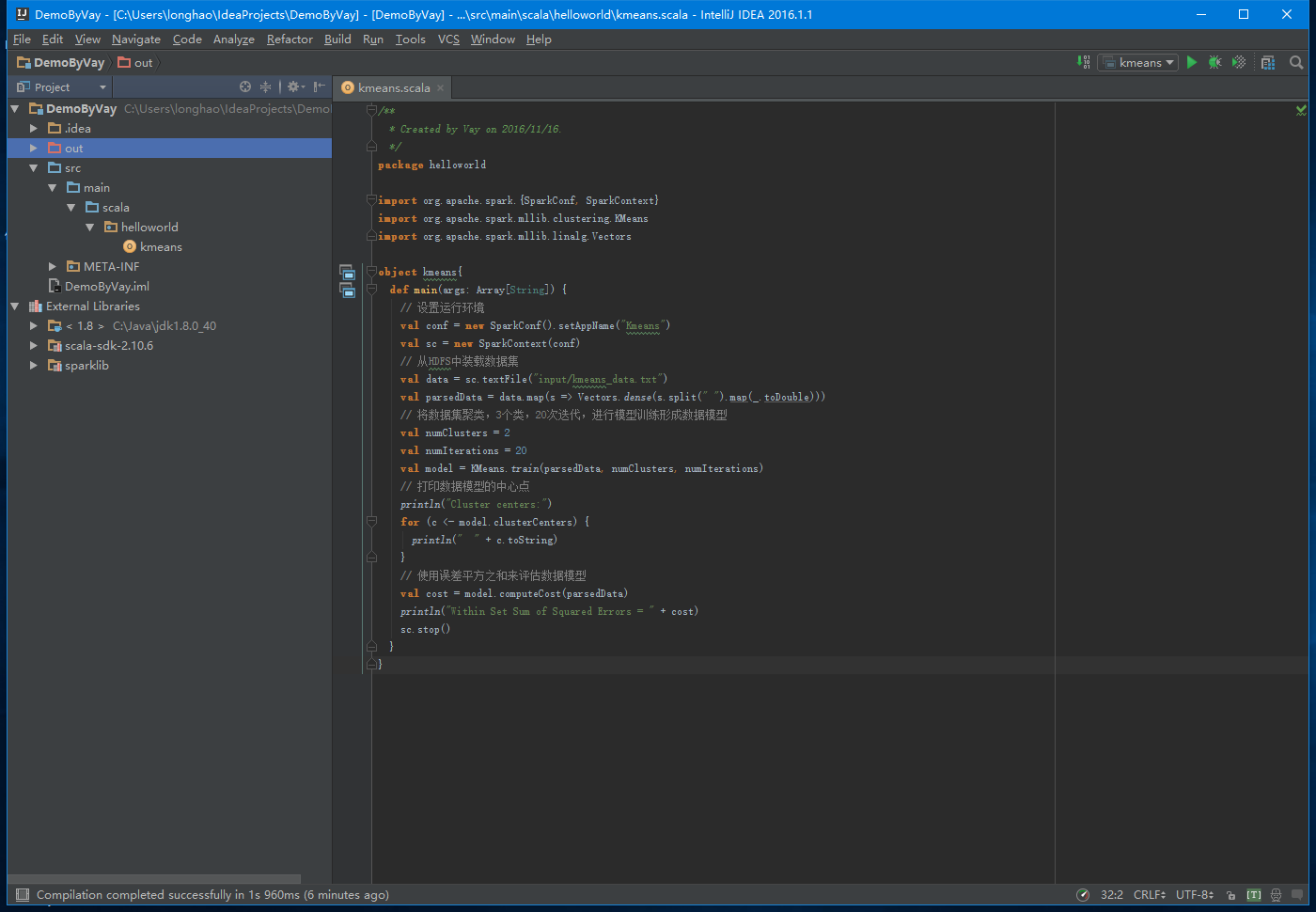
在src->main->scala下创建helloword包,在该包中添加kmeans对象文件(新建scala类,在弹出的框中kind选择Object),具体代码如下所示,完成之后的整体结构如下图所示:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
object kmeans{
def main(args: Array[String]) {
// 设置运行环境
val conf = new SparkConf().setAppName("Kmeans")
val sc = new SparkContext(conf)
// 从HDFS中装载数据集
val data = sc.textFile("input/kmeans_data.txt")
val parsedData = data.map(s => Vectors.dense(s.split(" ").map(_.toDouble)))
// 将数据集聚类,3个类,20次迭代,进行模型训练形成数据模型
val numClusters = 2
val numIterations = 20
val model = KMeans.train(parsedData, numClusters, numIterations)
// 打印数据模型的中心点
println("Cluster centers:")
for (c <- model.clusterCenters) {
println(" " + c.toString)
}
// 使用误差平方之和来评估数据模型
val cost = model.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + cost)
sc.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3.5 编译打包
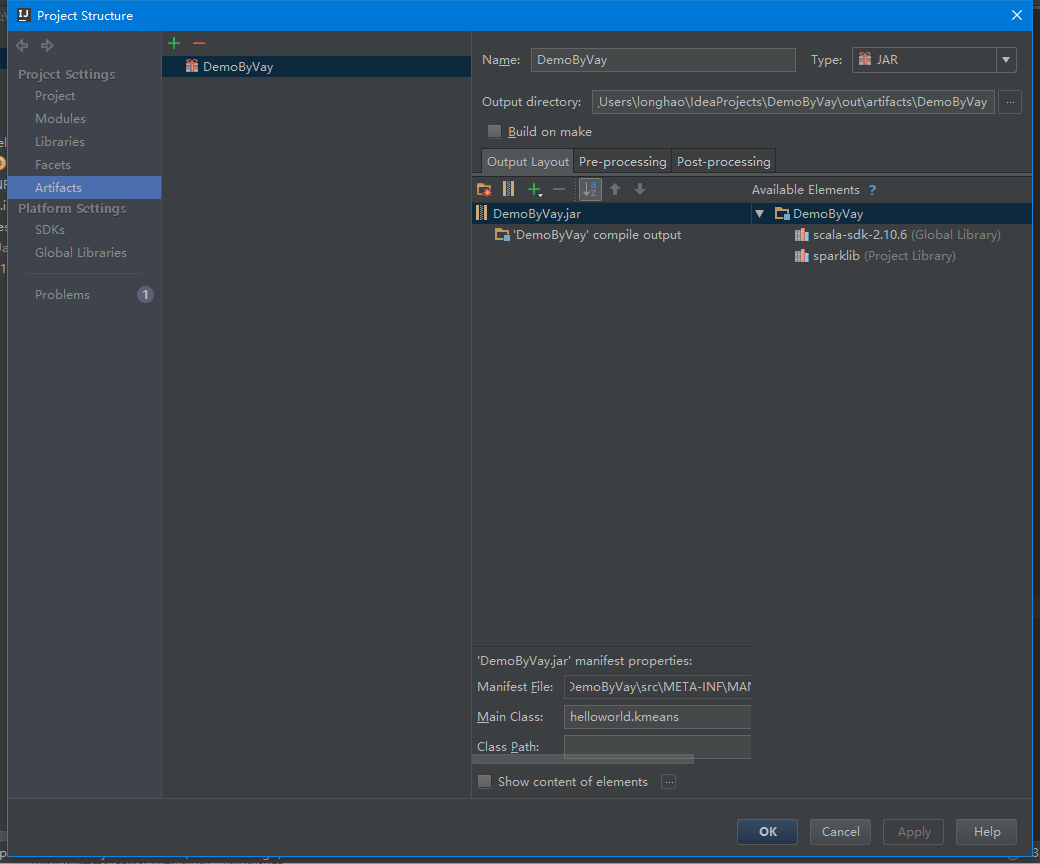
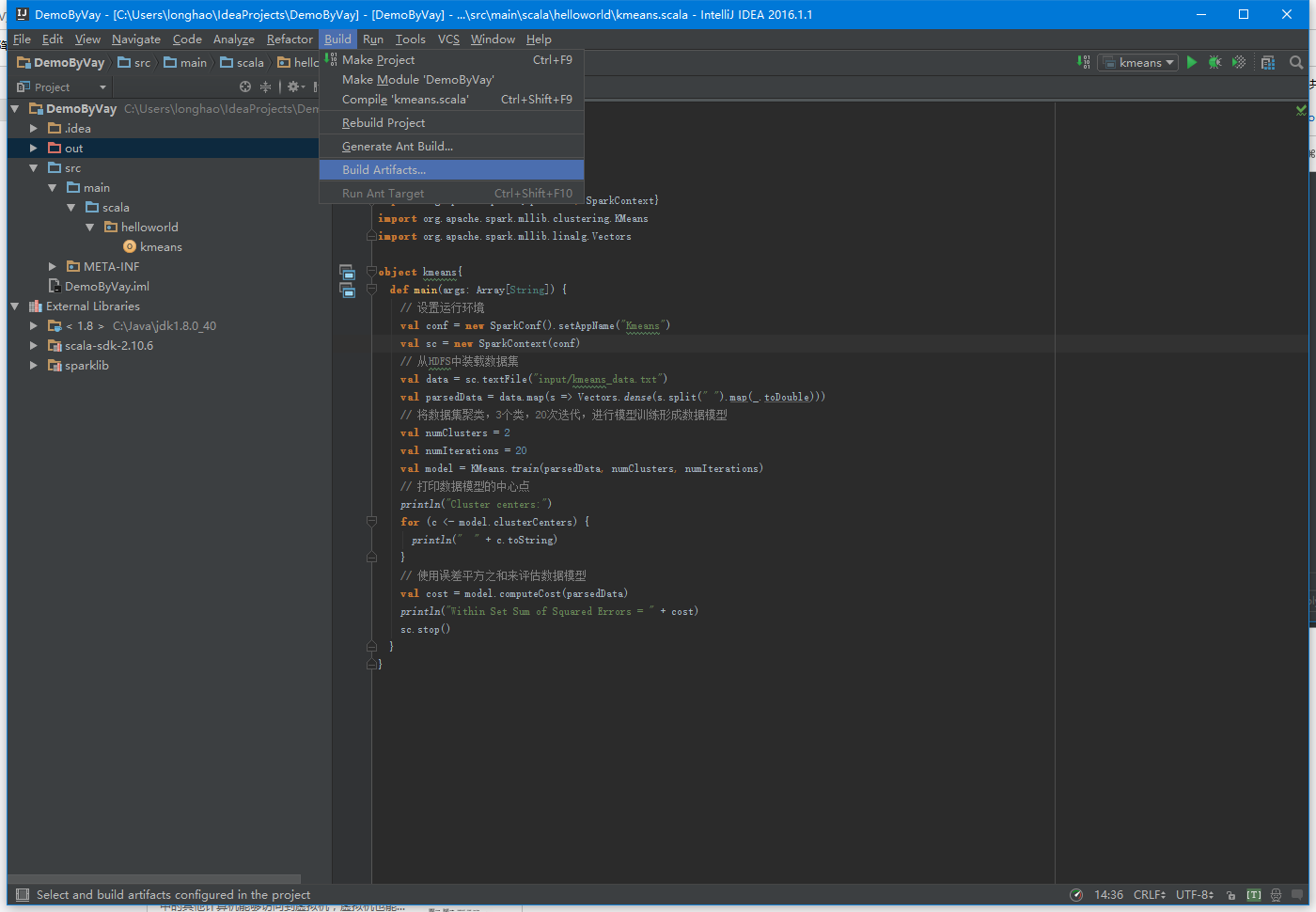
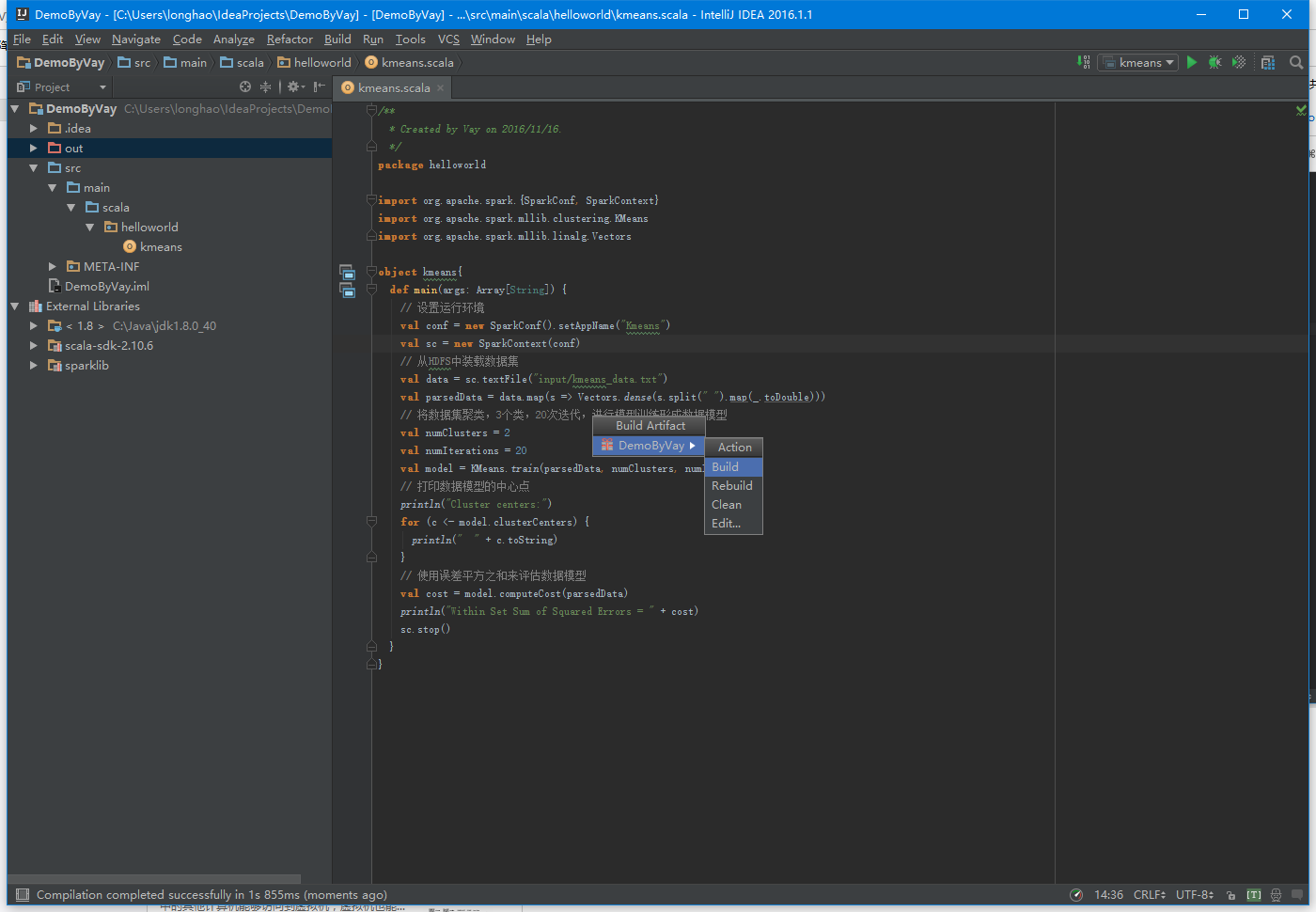
首先配置打包信息,在项目结构界面中选择“Artifacts”,在右边操作界面选择绿色”+”号,选择添加JAR包的”From modules with dependencies”方式,出现如下界面,在该界面中选择主函数入口为kmeans,接着填写该JAR包名称和调整输出内容。由于运行环境已经有Scala相关类包,所以在这里去除这些包只保留项目的输出内容。
4、 提交到Spark集群执行
4.1 传输JAR包
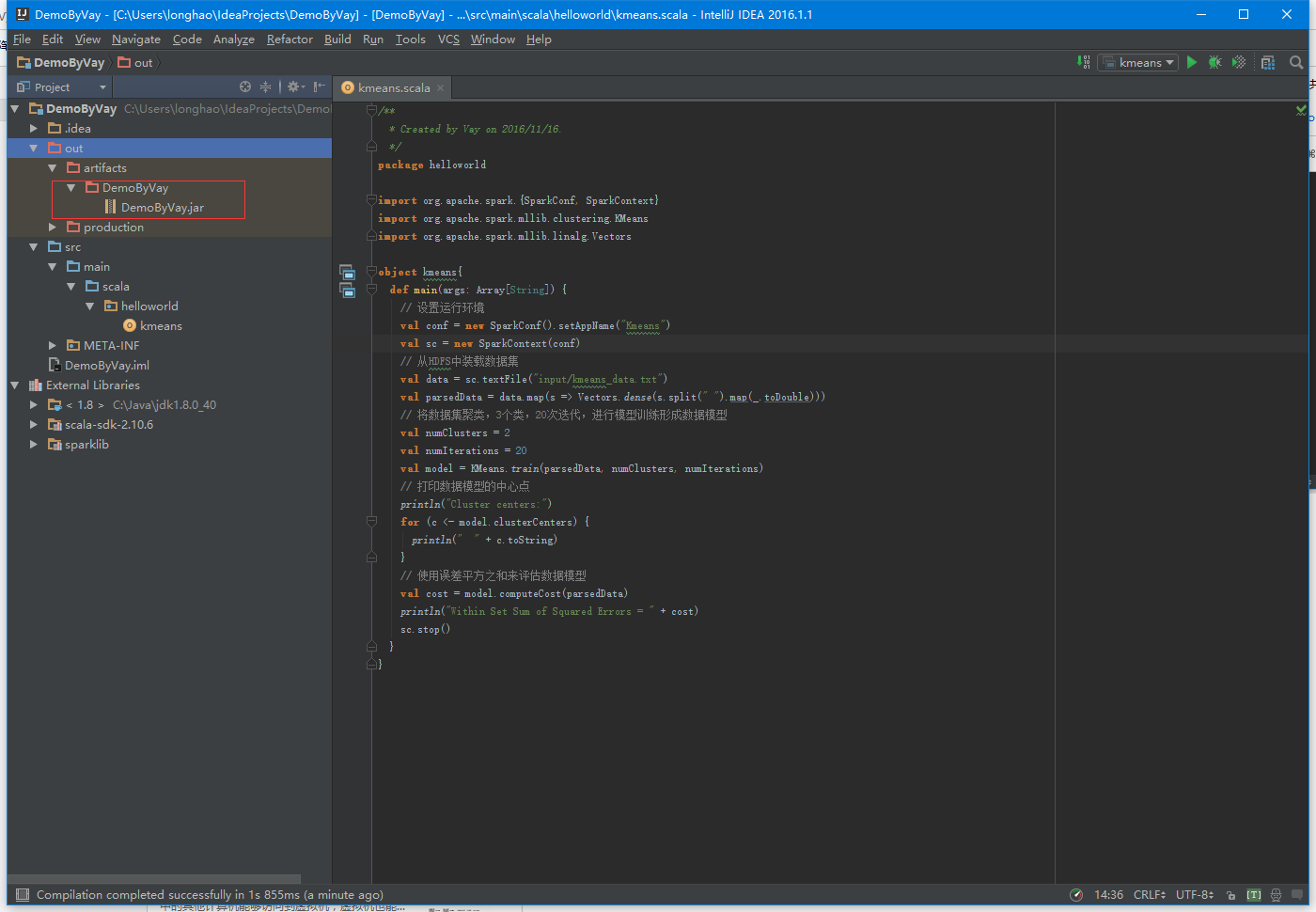
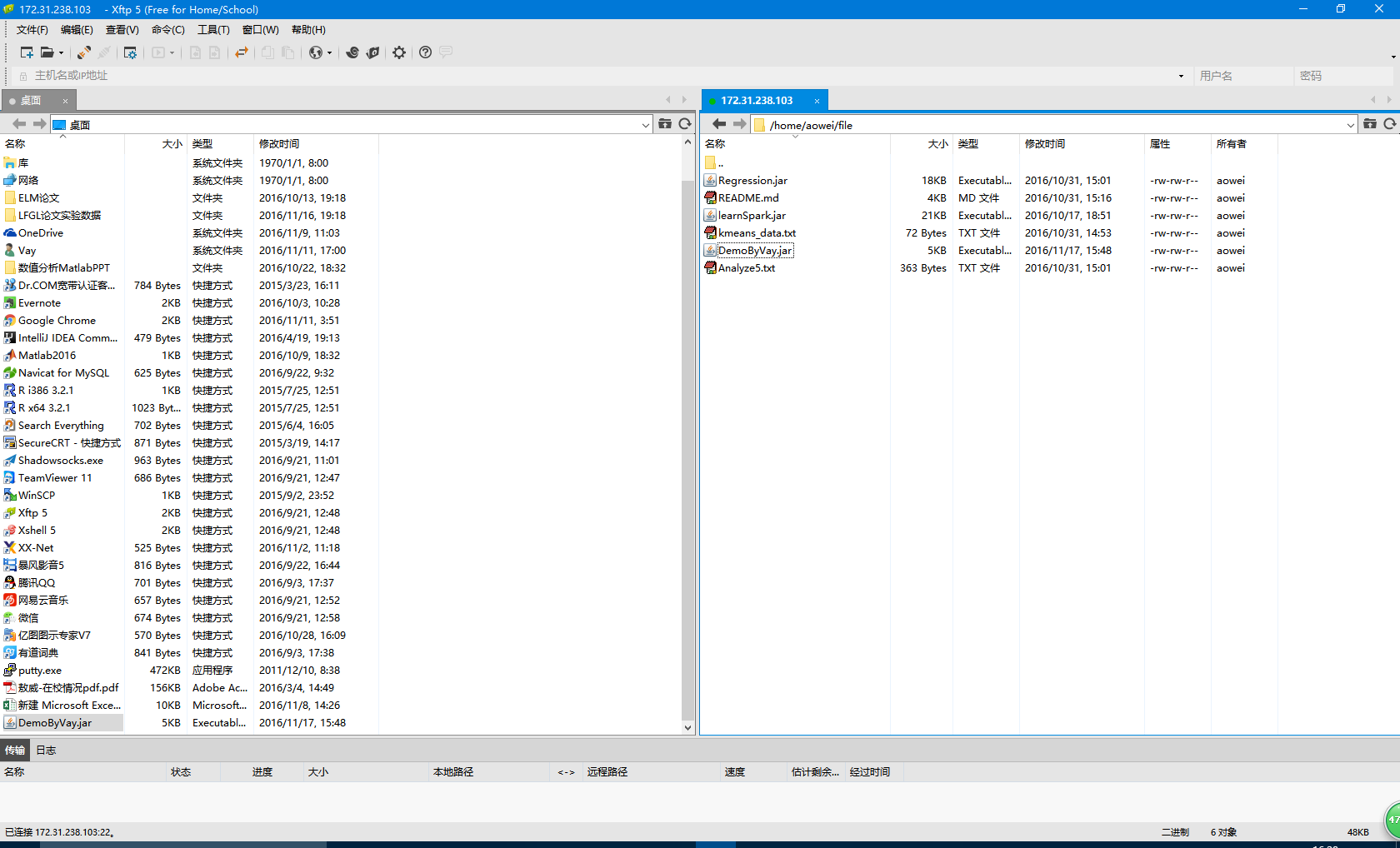
编译打包完成后,下方会提示…successfully…,生成好的JAR包就出现在了project目录中的out/artifacts文件夹中,直接ctrl+c拷贝出来,并使用ftp工具将数据文件kmeans_data.txt与JAR包传输到我们的集群主节点中,同时将 kmeans_data.txt存储到HDFS中,这样就可保证每个节点都有一份数据,不然需要使用parallelize进行分发,具体我们这里不详细描述,可以参考OREILLY图书《Learning Spark》。
4.2 提交执行
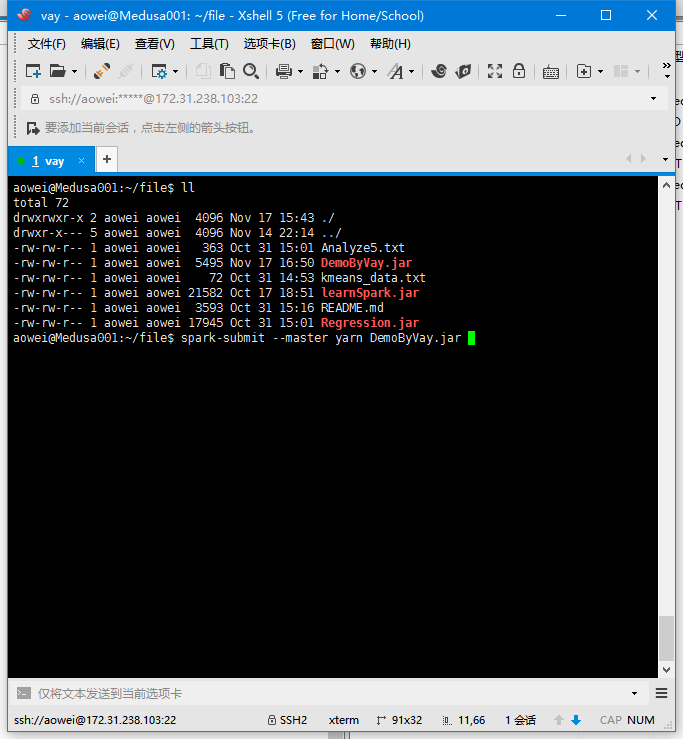
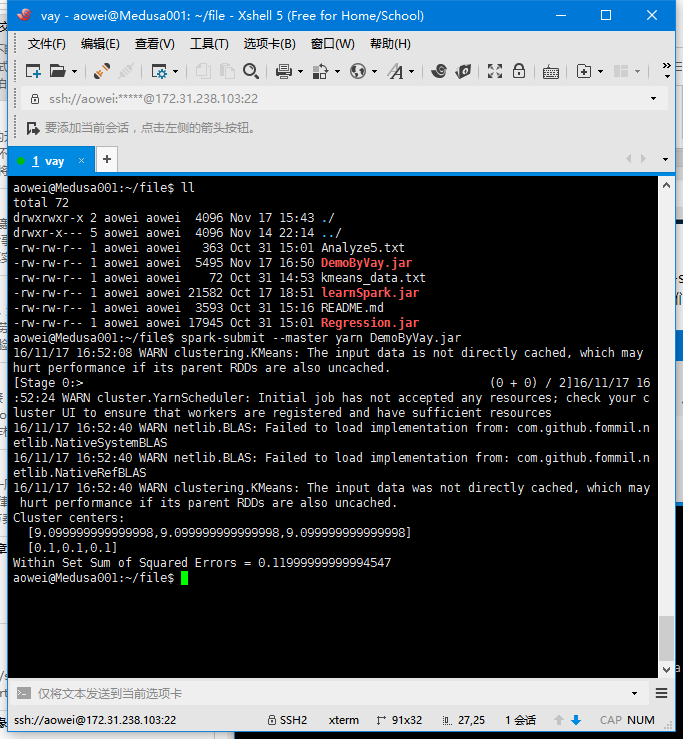
在Spark中,使用spark-submit指令进行提交,一般格式为:spark-submit [options] (app jar | python file) [app options],本篇使用的是基于yarn调度器的Spark集群,提交指令与运行结果如下所示,我们可以看到执行后输出了聚类后的中心值以及方差和,因为k-means采用的是随机选择初始中心,因此每次运行的方差和不尽相同,故我们可以多次运行选择方差和最小的结果。
在此,我们就可以在Spark的星辉斑斓里自由地歌唱了~~
-
').addClass('pre-numbering').hide();
近年来随着大数据不断升温,并行数据分析变得越来越流行,各种分布式计算框架应运而生。Spark最早起源于加州大学伯克利分校AMP实验室的一个研究项目,实验室的研究人员曾经使用过Hadoop MapReduce,他们发现MapReduce在迭代计算和交互计算的任务上效率表现不佳,因此Spark从一开始就是为交互式查询和迭代算法设计的,同时还支持内存式储存和高效的容错机制。 Spark作为下一代大数据处理引擎,在非常短的时间里崭露头角,并且以燎原之势席卷业界。本篇主要介绍了如何使用IDEA在本地打包Spark应用程序(以K-Means为例),并提交到集群执行。
1、 安装JDK与Scala SDK
JDK和Scala SDK的安装在这里不再赘述,需要注意的是:要设置好环境变量,这样新建项目时就能自动检测到对应的版本,同时版本最好不要太高,以避免版本不兼容的问题,本篇采用的是JDK 8.0与Scala 2.10.6。
JDK下载地址:http://www.oracle.com/technetwork/java/javase/downloads/
Scala下载地址:http://www.scala-lang.org/download/
2、 安装IDEA
IDEA 全称 IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一, IDEA每个版本提供Community(社区版)和Ultimate(商业版)两个edition,其中Community是完全免费的,Ultimate版本可以试用30天,下载地址:http://www.jetbrains.com/idea/download/
2.1 安装Scala插件
根据安装向导安装好IDEA后,需要安装scala插件,有两种途径可以安装scala插件(本篇已经安装好了scala插件,故在这一步作更新):
- 启动IDEA -> Welcome to IntelliJ IDEA -> Configure -> Plugins -> Install JetBrains plugin… -> 找到scala后安装。
- 启动IDEA -> Welcome to IntelliJ IDEA -> Open Project -> File -> Settings -> plugins -> Install JetBrains plugin… -> 找到scala后安装。
2.2 设置IDEA风格
如果想使用那种酷酷的黑底界面,可以在File -> Settings -> Appearance -> Theme选择Darcula,保存后重新进入即可。
3、 新建Scala项目
3.1 单击file->new project,选择Scala,如果没有安装scala插件就没有这个选项,在项目的基本信息中填写项目名称、项目所在位置以及对应的Project SDK和Scala SDK(环境变量配置好了会自动匹配)。
3.2 设置项目structure
创建好项目后,可以看到现在还没有源文件,只有一个存放源文件的目录src以及存放工程其他信息的杂项。通过双击src目录或者点击菜单上的项目结构图标可以打开项目配置界面,src单击右键选择“new folder”添加src->main->scala,并设置为Sources类型,如下图所示:
3.3 配置Library
- 选择Libraries目录,添加Scala SDK Library,这里选择scala-2.10.6版本。
- 添加Java Library,选择spark-assembly-1.6.1-hadoop2.2.0.jar(在spark的lib中可以找到),本篇将一些常用的JAR包放到了一个文件夹,故在此添加的是sparklib。
3.4 编写程序
在src->main->scala下创建helloword包,在该包中添加kmeans对象文件(新建scala类,在弹出的框中kind选择Object),具体代码如下所示,完成之后的整体结构如下图所示:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
object kmeans{
def main(args: Array[String]) {
// 设置运行环境
val conf = new SparkConf().setAppName("Kmeans")
val sc = new SparkContext(conf)
// 从HDFS中装载数据集
val data = sc.textFile("input/kmeans_data.txt")
val parsedData = data.map(s => Vectors.dense(s.split(" ").map(_.toDouble)))
// 将数据集聚类,3个类,20次迭代,进行模型训练形成数据模型
val numClusters = 2
val numIterations = 20
val model = KMeans.train(parsedData, numClusters, numIterations)
// 打印数据模型的中心点
println("Cluster centers:")
for (c <- model.clusterCenters) {
println(" " + c.toString)
}
// 使用误差平方之和来评估数据模型
val cost = model.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + cost)
sc.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3.5 编译打包
首先配置打包信息,在项目结构界面中选择“Artifacts”,在右边操作界面选择绿色”+”号,选择添加JAR包的”From modules with dependencies”方式,出现如下界面,在该界面中选择主函数入口为kmeans,接着填写该JAR包名称和调整输出内容。由于运行环境已经有Scala相关类包,所以在这里去除这些包只保留项目的输出内容。
4、 提交到Spark集群执行
4.1 传输JAR包
编译打包完成后,下方会提示…successfully…,生成好的JAR包就出现在了project目录中的out/artifacts文件夹中,直接ctrl+c拷贝出来,并使用ftp工具将数据文件kmeans_data.txt与JAR包传输到我们的集群主节点中,同时将 kmeans_data.txt存储到HDFS中,这样就可保证每个节点都有一份数据,不然需要使用parallelize进行分发,具体我们这里不详细描述,可以参考OREILLY图书《Learning Spark》。
4.2 提交执行
在Spark中,使用spark-submit指令进行提交,一般格式为:spark-submit [options] (app jar | python file) [app options],本篇使用的是基于yarn调度器的Spark集群,提交指令与运行结果如下所示,我们可以看到执行后输出了聚类后的中心值以及方差和,因为k-means采用的是随机选择初始中心,因此每次运行的方差和不尽相同,故我们可以多次运行选择方差和最小的结果。
在此,我们就可以在Spark的星辉斑斓里自由地歌唱了~~
-
').addClass('pre-numbering').hide();