不用登陆可以直接爬取,数据好找,主要在于分析页面
参考于:https://blog.csdn.net/weixin_44835732/article/details/103350174
请求:requests 解析:xpath
看界面图片,看到下面要下载客户端,先不用慌,分析url,上边是1-8888,推测可能一共有8888页,但是总共500首歌曲,肯定不对,我们更改url试试看

果然,经过测试,只有前23页有数据,往后都没有数据


代码很简单,如下
from lxml import etree
import requests
base_url = "https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank"
data_lst = []
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36",
"Referer": "https://www.kugou.com/"
}
def get_information(url):
response = requests.get(url,headers=headers).content
html = etree.HTML(response)
song_lst = html.xpath(".//div[@class='pc_temp_songlist ']//li/@title")
for song in song_lst:
data_lst.append(song)
if __name__ == "__main__":
for i in range(1,24):
page = str(i)
url = base_url.format(page)
get_information(url)
print(data_lst)
数据如下:

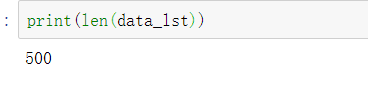
确实是500个,没有遗漏