Hadoop
- Hadoop是一个开源的大数据框架
- Hadoop是一个分布式计算的解决方案
- Hadoop=HDFS(分布式文件系统)+ MapReduce(分布式计算)
Hadoop核心
- HDFS分布式文件系统:存储是大数据技术的基础
- MapReduce编程模型:分布式计算时大数据应用的解决方案
HDFS
- 普通的成百上千的机器
- 按TB甚至PB为单位的大量的数据
- 简单便捷的文件获取
Hadoop基础架构
HDFS概念
- 数据块
- NameNode
- DataNode
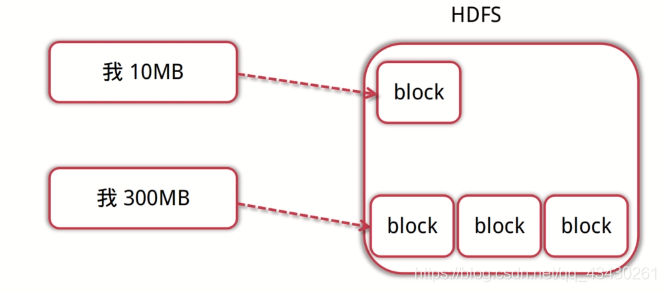
数据块
数据块是抽象块而非整个文件作为存储单元,默认大学为64MB,一般设置为128M,备份*3
NameNode
- 管理文件系统的命名空间,存放文件元数据
- 维护着文件系统的所有文件和目录,文件与数据块的映射
- 记录每个文件中各个块所在数据节点的信息
DataNode
- 存储并检索数据块
- 向NameNode更新所存储块的列表
HDFS优点
- 适合大文件存储,支持TB,PB级的数据存储,并有副本策略
- 可以构建在廉价的机器上,并有一定的容错和恢复机制
- 支持流失数据访问,一次写入,多次读取最高效
HDFS缺点
- 不适合大量小文件存储
- 不适合并发写入,不支持文件随机修改
- 不支持随机读等低延时的访问方式
两个问题 - 数据块的大小设置为多少是合适,为什么?
- NameNode有哪些容错的机制,如果挂掉了怎么办?
