一、快手大数据开发工程师面经
一面(40min)
1、自我介绍?
2、Spark任务调度(源码)?
1)DAGScheduler:根据RDD的宽窄依赖关系将DAG有向无环图切割成一个个的stage,将stage封装给另一个对象taskSet,taskSet=stage,然后将一个个的taskSet给taskScheduler。
2)taskScheduler:taskSeheduler拿倒taskSet之后,会遍历这个taskSet,拿到每一个task,然后去调用HDFS上的方法,获取数据的位置,根据获得的数据位置分发task到响应的Worker节点的Executor进程中的线程池中执行。
3)taskSchedule:taskSchedule节点会跟踪每一个task的执行情况,若执行失败,TaskSche会尝试重新提交,默认会重试提交三次,如果重试三次依然失败,那么这个task所在的stage失败,此时TaskSchedule向DAGSchedule做汇报。
4)DAGScheduler:接收到stage失败的请求后,此时DAGSheduler会重新提交这个失败的stage,已经成功的stage不会重复提交,只会重试这个失败的stage。(注:如果DAGScheduler重试了四次依然失败,那么这个job就失败了,job不会重试)
3、Kafka基本原理说一下(生产消费模型,存储,Leader选举,ISR…)
Apache Kafka是由Apache开发的一种发布订阅消息系统,它是一个分布式的、分区的和重复的日志服务。具有高性能、高可靠和高容错性的特点。
4、Consumer Group中Consumer和Partition的对应关系?
Partition:
分区,为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
Consumer:
消息消费者,向kafka broker取消息的客户端。
Consumer Group:
消费者组,这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;

5、Kafka支持什么语义(三种语义),怎么实现Exactly Once?
Kafka支持三种消息投递语义:
① At most once(最多投递一次) 消息可能会丢,但绝不会重复传递
② At least one(最少投递一次) 消息绝不会丢,但可能会重复传递
③ Exactly once*(仅一次) 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户想要的
Kafka默认保证At least once,并且允许通过设置producer异步提交来实现At most once,而Exactly once要求与目标存储系统协作;
读完消息先commit再处理消息,这就对应于At most once。
读完消息先处理再commit消费状态,并保存offset,这就对应于At least once。
如果要实现Exactly once,就需要协调offset和实际操作的输出,可以将offset和操作输入存在同一个地方。比如,consumer拿到数据后可能把数据放到HDFS,如果把最新的offset和数据本身一起写到HDFS,那就可以保证数据的输出和offset的更新要么都完成,要么都不完成,间接实现Exactly once。
6、Spark Streaming和Flink的区别?
7、Scala的模式匹配和Java有什么区别?
8、用Kafka的过程中有过什么问题,怎么解决?
9、实习做了什么?
10、撕代码: 有序链表合并,n*m的带有数字的矩阵,从左上角走到右下角,问最短的路径上经过的数字的和是多少?(dp)
二面(1h20min)
1、自我介绍?
2、Java多线程了解吗?写个生产者消费者模型吧?
3、线程池熟悉是吧?写个线程池?
写完问怎么改进让它支持切换到SHUTDOWN状态?因为我只是参考了源码实现了一个能提交任务的简单线程池,没考虑别的,要改进的话有点麻烦,就大概说了下思路,也不知道对不对。
4、Java线程同步啥的,不太记得了。
5、Flink了解吗,基本的概念说一下?
6、撕算法:给一个不带分隔符的IP字符串,要给出所有的可能的IP地址,返回一个List(懵逼,用回溯写了个大概)。
三面(40min)
1、自我介绍
2、实习做了什么?
3、Kafka基本原理说一下,和其他的MQ相比的优势?
4、Kafka 消费者怎么从Kafka取数据的?
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
对于Kafka而言,pull模式更合适,它可简化broker的设计,consumer可自主控制消费消息的速率,同时consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直等待数据到达。为了避免这种情况,我们在我们的拉请求中有参数,允许消费者请求在等待数据到达的“长轮询”中进行阻塞。
5、消费者怎么保证ExactlyOnce?
6、Kafka消费者怎么保证有序性?
Kafka对于消息的重复、丢失、错误以及顺序没有严格的要求,Kafka只能保证一个partition中的消息被某个consumer消费时是顺序的,事实上,从Topic角度来说,当有多个partition时,消息仍然不是全局有序的。
7、Kafka生产者怎么保证不丢不重复(幂等)?
acks=all : 所有副本都写入成功并确认。
8、Kafka生产者写入怎么保证有序?
9、撕算法:两字符串最长公共子串?
差不多就这样结束,三面面试官赶着开会,就匆匆结束了。
二、字节大数据一面面经
1.你知道哪些设计模式,为什么有这些设计模式?
2.浏览器输入地址后都发生了什么?

3.算法,扔鸡蛋问题?
4.算法,字符串S1的全排列是否为S2的字串?
三、【爱奇艺】春招大数据开发工程师面经
一面(20min)
1、自我介绍?
2、Spark join的分类,实现过程,得到的结果?
1.inner 通过左dataset的每一行和右dataset的行进行比较,匹配的行 并且都没有null值, 结合在一起。
2.cross 通过左dataset的每一行和右 dataset的每一行生成一个笛卡尔积运算结果 。

3.outer、full、full outer 左、右dataset所有的行形成 一个dataset,若新的dataset的行只包含左或右的dataset的数据时,则补充数据为null。

4.left anti 结果dataset只包含存在于左dataset,而不包含于右dataset的数据。

5.left、left outer 结果dataset包含左dataset的所有的加上右dataset的common rows,像inner join一样,不包含于右dataset的填充为null。

6.left semi 结果dataset包含左、右数据集common rows,但仅仅包含左dataset的数据。

7.right、right outer 结果dataset包含右dataset的所有行加上右、左common rows,右dataset的行不存在于左dataset是,填充数据为null。
3、Spark map join的实现原理?
在Hadoop MapReduce中, map-side join是借助DistributedCache实现的。DistributedCache可以帮我们将小文件分发到各个节点的Task工作目录下,这样,我们只需在程序中将文件加载到内存中(比如保存到Map数据结构中),然后借助Mapper的迭代机制,遍历另一个大表中的每一条记录,并查找是否在小表中,如果在则输出,否则跳过。
在Apache Spark中,同样存在类似于DistributedCache的功能,称为“广播变量”(Broadcast variable)。其实现原理与DistributedCache非常类似,但提供了更多的数据/文件广播算法,包括高效的P2P算法,该算法在节点数目非常多的场景下,效率远远好于DistributedCache这种基于HDFS共享存储的方式。使用MapReduce DistributedCache时,用户需要显示地使用File API编写程序从本地读取小表数据,而Spark则不用,它借助Scala语言强大的函数闭包特性,可以隐藏数据/文件广播过程,让用户编写程序更加简单。
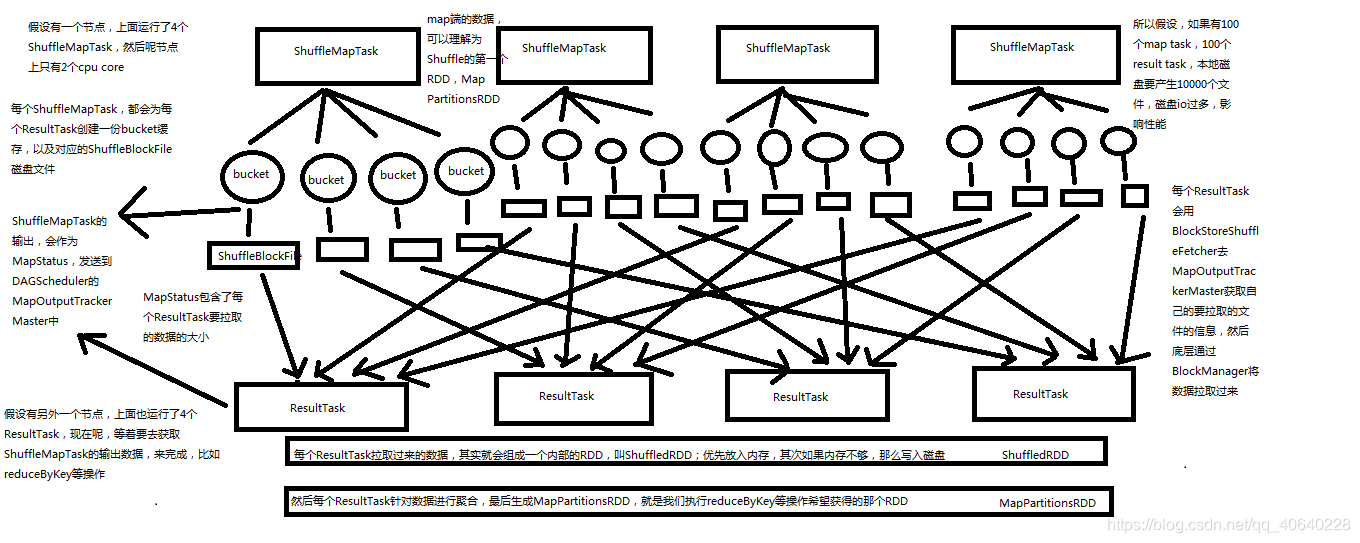
4、Spark Shuffle过程?
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。该ShuffleManager而HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能。因此在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。SortShuffleManager相较于HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
普通的Shuffle操作原理剖析图解:
优化后的Shuffle原理剖析图解(只对HashShuffle有用)

5、SQL会写吗,写一个统计每个学科的前三名?
6、实习主要做了什么,用什么技术栈?
7、Python 方法的参数带两个*是什么意思?
8、Java反射生成对象?
9、Java对象的生命周期?

对象创建-》初始化-》被使用-》不可达-》被收集
二面(20min)
1、自我介绍?
2、问了下实习做什么?
3、问了下在校项目?
4、数仓分层,每层做什么?
ods 原始数据层 存放原始数据,保持原貌不做处理
dwd 明细数据层 对ods层数据清洗(去除空值,脏数据,超过极限范围的数据)
dws 服务数据层 轻度聚合
ads 应用数据层 具体需求
5、Spark Streaming和Flink的区别?
6、MapReduce熟吗?
7、Java GC说一下,我从内存模型开始说的?
8、写了几个题:
给了两个表三个SQL,把每个结果写出来,其实主要是join,不同join的结果
从一个String列表中移除大于某个String的元素(其实不知道为什么要出这个题)
图,最小代价生成树,什么算法,什么思想。
三面(20min)
1、主管面,自我介绍
2、Spark任务调度?
3、Spark Task失败要从头开始重试吗?
4、遇到过什么困难,怎么解决的?
5、HBase特点,应用场景?
6、实习做什么(每次都问)?
总结
感觉不同公司的侧重点不太一样,有些可能会偏向基础,有些可能会偏向工程,感觉还是面向简历复习效果比较好,把简历上写的熟悉的东西基本掌握了也差不多了,此外Java的基础也要比较熟,像ConcurrentHashMap,线程池,AQS的源码最好心里有点数,之后就是自己熟悉的技术栈的源码,常问到的技术点可以去看看,问到就是赚到。
四、陌陌二面面经—大数据开发实习岗
一面: 3.23 68min
1.CAS的底层实现
在计算机科学中,比较和交换(Conmpare And Swap)是用于实现多线程同步的原子指令。 它将内存位置的内容与给定值进行比较,只有在相同的情况下,将该内存位置的内容修改为新的给定值。JAVA中的CAS操作都是通过sun包下Unsafe类实现,而Unsafe类中的方法都是native方法,由JVM本地实现。
CAS可以有效的提升并发的效率,但同时也会引入ABA问题。如线程1从内存X中取出A,这时候另一个线程2也从内存X中取出A,并且线程2进行了一些操作将内存X中的值变成了B,然后线程2又将内存X中的数据变成A,这时候线程1进行CAS操作发现内存X中仍然是A,然后线程1操作成功。虽然线程1的CAS操作成功,但是整个过程就是有问题的。比如链表的头在变化了两次后恢复了原值,但是不代表链表就没有变化。 所以JAVA中提供了AtomicStampedReference/AtomicMarkableReference来处理会发生ABA问题的场景,主要是在对象中额外再增加一个标记来标识对象是否有过变更。
2.CMS
CMS是Content Management System的缩写,意为"内容管理系统"。内容管理系统(content management system,CMS)是一种位于WEB 前端(Web 服务器)和后端办公系统或流程(内容创作、编辑)之间的软件系统。内容的创作人员、编辑人员、发布人员使用内容管理系统来提交、修改、审批、发布内容。
3.虚拟内存
Java虚拟机管理的内存包括几个运行时数据内存:方法区、虚拟机栈、堆、本地方法栈、程序计数器。
4.Hbase的二级索引的流程
HBase里面只有rowkey作为一级索引, 如果要对库里的非rowkey字段进行数据检索和查询, 往往要通过MapReduce/Spark等分布式计算框架进行,硬件资源消耗和时间延迟都会比较高。为了HBase的数据查询更高效、适应更多的场景, 诸如使用非rowkey字段检索也能做到秒级响应,或者支持各个字段进行模糊查询和多字段组合查询等, 因此需要在HBase上面构建二级索引, 以满足现实中更复杂多样的业务需求。
1)官方特性:基于Coprocessor方案
其实从0.94版本开始,HBase官方文档已经提出了hbase上面实现二级索引的一种路径:基于Coprocessor(0.92版本开始引入,达到支持类似传统RDBMS的触发器的行为)开发自定义数据处理逻辑,采用数据“双写”(dual-write)策略,在有数据写入同时同步到二级索引表。
2)开源方案:
华为的hindex : 基于0.94版本,当年刚出来的时候比较火,但是版本较旧,看GitHub项目地址最近这几年就没更新过。
Apache Phoenix: 功能围绕着SQL on hbase,支持和兼容多个hbase版本, 二级索引只是其中一块功能。 二级索引的创建和管理直接有SQL语法支持,使用起来很简便, 该项目目前社区活跃度和版本更新迭代情况都比较好。
5.shell : 对数据排序
6.NIO
详解链接直达:https://blog.csdn.net/qq_40640228/article/details/105005111
7.外部排序
8.TCP和UDP
1. TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接。
2. TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。TCP通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
3. UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
4. 每一条TCP连接只能是点到点的;UDP支持一对一、一对多、多对一和多对多的交互通信。
5. TCP对系统资源要求较多,UDP对系统资源要求较少。
9.TCP如何实现可靠?
1、确认和重传:接收方收到报文就会确认,发送方发送一段时间后没有收到确认就重传。
2、数据校验
3、数据合理分片和排序
4、流量控制:当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失
5、拥塞控制:当网络拥塞时,减少数据的发送
10.编程

random()随机产生[0, 正无穷)范围的随机数,利用该方法产生生成[m,n]范围的随机数。
11.Spark的stage划分
Spark的宽依赖和窄依赖是DAGScheduler将job划分为多个Stage的重要因素,每一个宽依赖都会划分一个Stage。
12.Spark的shuffle机制
13.为什么要根据宽依赖划分stage?
当执行算子有shffle操作的时候,就划分一个Stage。(即宽依赖来划分Stage),窄依赖会被划分到同一个Stage中,这样它们就能以管道的方式迭代执行。宽依赖由于依赖的上游RDD不止一个,所以往往需要跨节点传输数据。从容灾角度讲,它们恢复计算结果的方式不同。窄依赖只需要重新执行父RDD的丢失分区的计算即可恢复。而宽依赖则需要考虑恢复所有父RDD的丢失分区,并且同一RDD下的其他分区数据也重新计算了一次。
14.HashMap的底层结构?HashMap进行put操作会涉及哪些操作(扩容和链表转红黑树) ?ConcurrentHashMap如何实现线程安全的? 分段锁和CAS的比较?
详解链接:https://blog.csdn.net/qq_40640228/article/details/105010244
15.JVM有哪些关键字实现了可见性(volatile,Synchronized,final)
链接:https://www.nowcoder.com/discuss/experience?tagId=733
来源:牛客网
