神经网络模型
- 数据量越来越大、数据维度越来越高(文本、图像)、多源数据越来越多
- 其他模型很难处理这种多源、高维数据,目前的人工智能产品中大部分都用的是神经网络模型
神经网络原理
- 输入层:自变量
- 隐藏层:中间状态(特征提取)
- 输出层:因变量
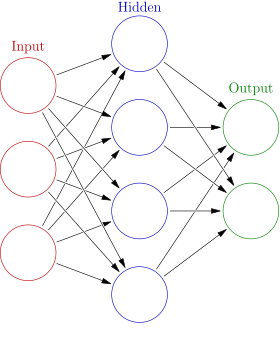
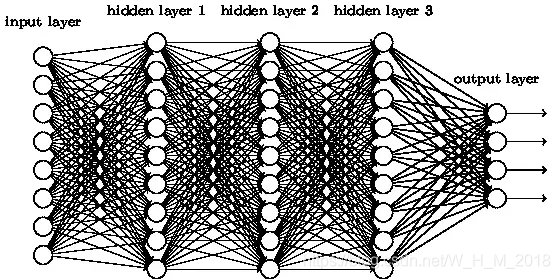
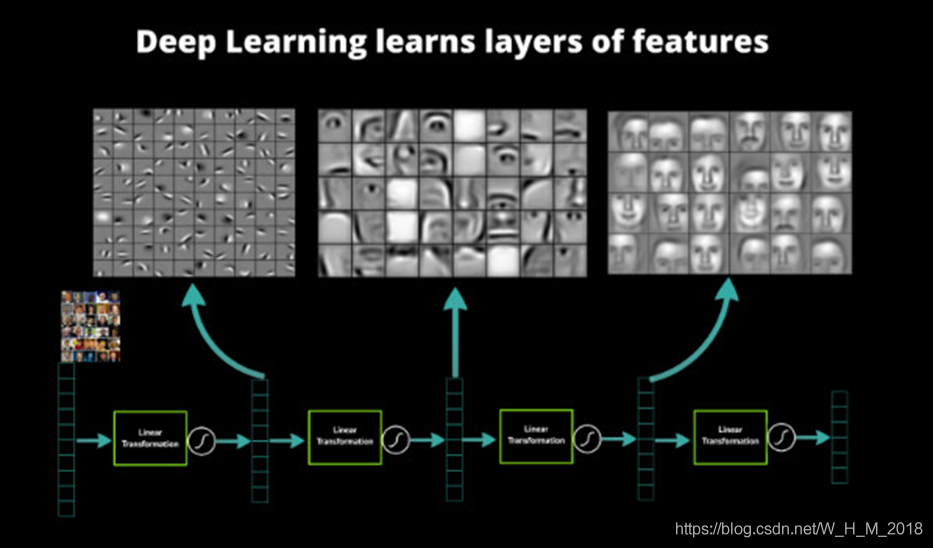
卷积神经网络中隐藏层的特征提取作用
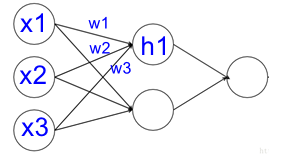
神经网络如何产生输出
线性计算方式
![]()
线性模型存在问题

引入非线性
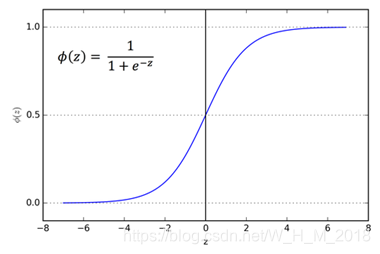
激活函数sigmoid ![]()
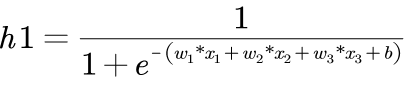
- sigmoid函数的输出介于0和1
- 可以理解为它把 (−∞,+∞)
- 范围内的数压缩到 (0, 1)以内。
神经网络如何实现自我修正
误差函数
均方误差:
![]()
MSE 求导:
![]()
损失函数
实际上是包含多个权重、偏置的多元函数
![]()
神经网络的自我调整:
如何是误差MSE变小:调整参数,
如何调整参数?
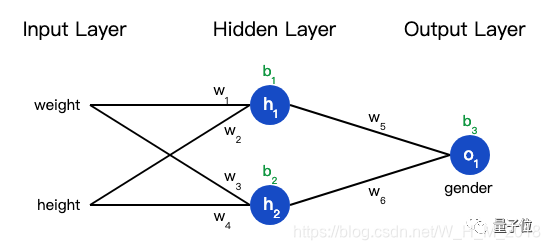
如何调整参数?
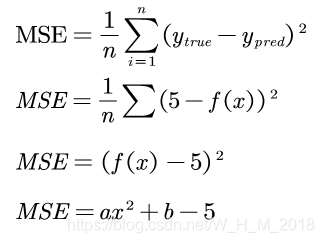
如何求此函数的最小值
w在右侧:w应该减小,判断依据:偏导数为正
w在左侧:w应该增大,判断依据:偏导数为负
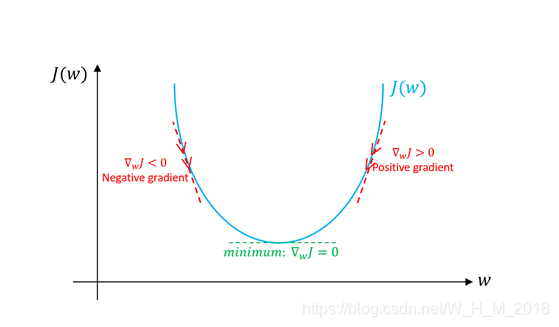
方法:偏导数 ∂L/∂w
![]()
对参数求偏导数,实现MSE最小化
更加复杂的函数是: 不能确定全局最小值 我们只能找到局部最小值
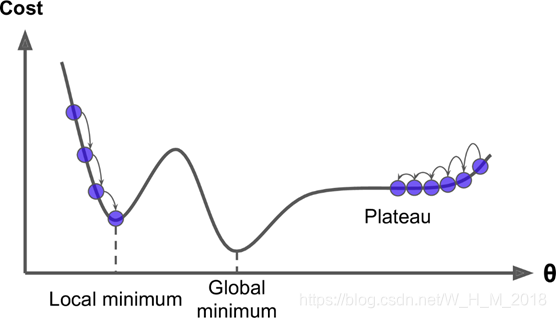
参数优化全过程
如何求所有权值的梯度
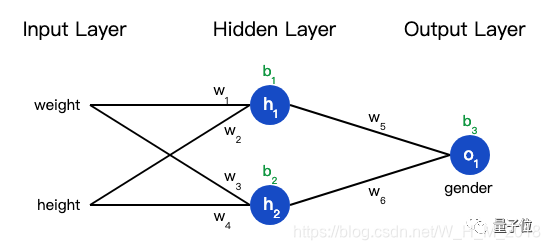
根据链式求导法则
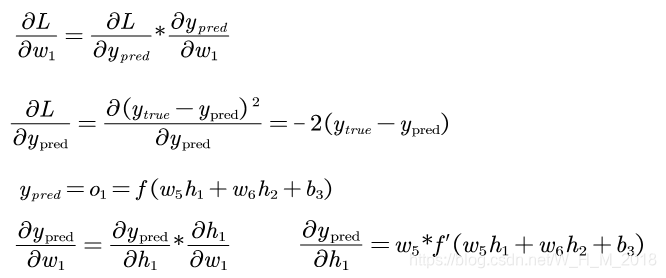
然后求∂h1/∂w1
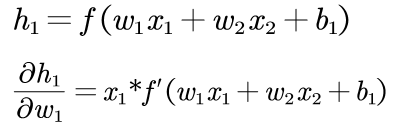
sigmoid函数(激活函数)的导数:
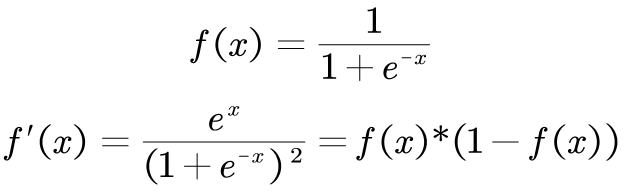
链式求导过程
![]()
参数更新策略
随机梯度下降(SGD)
![]()
η是一个常数,称为学习率(learning rate),它决定了训练网络速率的快慢。
将w1减去η·∂L/∂w1,就等到了新的权重w1。
当∂L/∂w1是正数时,w1会变小;当∂L/∂w1是负数 时,w1会变大。
模型训练流程
- 从数据集中选择一个样本;
- 计算损失函数对所有权重和偏置的偏导数;
- 使用更新公式更新每个权重和偏置;
- 回到第1步
全部推导公式
前向传导
![]()
![]()
![]()
![]()
![]()
后向传导
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
参数更新
![]()
![]()
神经网络的程序实现
- 从数据集中选择一个样本;
- 计算损失函数对所有权重和偏置的偏导数;
- 使用更新公式更新每个权重和偏置;
- 回到第1步
代码如下:
import numpy as np
def sigmoid(x):
# Sigmoid 激活函数: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
def deriv_sigmoid(x):
# sigmoid的倒数: f'(x) = f(x) * (1 - f(x))
fx = sigmoid(x)
return fx * (1 - fx)
def mse_loss(y_true, y_pred):
# MSE损失函数
return ((y_true - y_pred) ** 2).mean()
class OurNeuralNetwork:
def __init__(self):
# 权值矩阵
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
self.w5 = np.random.normal()
self.w6 = np.random.normal()
# 偏置
self.b1 = np.random.normal()
self.b2 = np.random.normal()
self.b3 = np.random.normal()
def feedforward(self, x):
# sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1
# h1 = sigmoid(sum_h1)
#
# sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
# h2 = sigmoid(sum_h2)
#
# sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
# o1 = sigmoid(sum_o1)
# y_pred = o1
# return y_pred
h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)
h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)
o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
return o1
# x是输入数据,这里输入只有两个属性.
def train(self, data, all_y_trues):
learn_rate = 0.1
epochs = 1000 # 迭代次数
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
# feed forward
sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
h2 = sigmoid(sum_h2)
sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
o1 = sigmoid(sum_o1)
y_pred = o1
# 计算偏导数.
# 对目标函数求导
d_L_d_ypred = -2*(y_true - y_pred)
# # Neuron o1
# d_ypred_d_w5 = h1 * deriv_sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
# d_ypred_d_w6 = h2 * deriv_sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
# d_ypred_d_b3 = deriv_sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
#
# d_ypred_d_h1 = self.w5 * deriv_sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
# d_ypred_d_h2 = self.w6 * deriv_sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
#
# # Neuron h1
# d_h1_d_w1 = x[0]*deriv_sigmoid(self.w1*x[0] + self.w2*x[1] + self.b1)
# d_h1_d_w2 = x[1]*deriv_sigmoid(self.w1*x[0] + self.w2*x[1] + self.b1)
# d_h1_d_b1 = deriv_sigmoid(self.w1*x[0] + self.w2*x[1] + self.b1)
#
# # Neuron h2
# d_h2_d_w3 = x[0]*deriv_sigmoid(self.w3*x[0] + self.w4*x[1] + self.b2)
# d_h2_d_w4 = x[1]*deriv_sigmoid(self.w3*x[0] + self.w4*x[1] + self.b2)
# d_h2_d_b2 = deriv_sigmoid(self.w3*x[0] + self.w4*x[1] + self.b2)
# Neuron o1
d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)
d_ypred_d_b3 = deriv_sigmoid(sum_o1)
d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)
d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)
# Neuron h1
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# Neuron h2
d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# 更新权值和偏置
# Neuron h1
self.w1 -= learn_rate*d_L_d_ypred*d_ypred_d_h1*d_h1_d_w1
self.w2 -= learn_rate*d_L_d_ypred*d_ypred_d_h1*d_h1_d_w2
self.b1 -= learn_rate*d_L_d_ypred*d_ypred_d_h1*d_h1_d_b1
# Neuron h2
self.w3 -= learn_rate*d_L_d_ypred*d_ypred_d_h2*d_h2_d_w3
self.w4 -= learn_rate*d_L_d_ypred*d_ypred_d_h2*d_h2_d_w4
self.b2 -= learn_rate*d_L_d_ypred*d_ypred_d_h2*d_h2_d_b2
# Neuron o1
self.w5 -= learn_rate*d_L_d_ypred*d_ypred_d_w5
self.w6 -= learn_rate*d_L_d_ypred*d_ypred_d_w6
self.b3 -= learn_rate*d_L_d_ypred*d_ypred_d_b3
# 计算误差
if epoch % 10 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
# 数据集定义
data = np.array([
[-2, -1], # Alice
[25, 6], # Bob
[17, 4], # Charlie
[-15, -6], # Diana
])
all_y_trues = np.array([
1, # Alice
0, # Bob
0, # Charlie
1, # Diana
])
# 模型训练
network = OurNeuralNetwork()
network.train(data, all_y_trues)Epoch 0 loss: 0.383 Epoch 10 loss: 0.213 Epoch 20 loss: 0.125 Epoch 30 loss: 0.095 Epoch 40 loss: 0.077 Epoch 50 loss: 0.064 Epoch 60 loss: 0.054 Epoch 70 loss: 0.046 Epoch 80 loss: 0.041 Epoch 90 loss: 0.036 Epoch 100 loss: 0.032 Epoch 110 loss: 0.029 Epoch 120 loss: 0.026 Epoch 130 loss: 0.024 Epoch 140 loss: 0.022 Epoch 150 loss: 0.020 Epoch 160 loss: 0.019 Epoch 170 loss: 0.017 Epoch 180 loss: 0.016 Epoch 190 loss: 0.015 Epoch 200 loss: 0.014 Epoch 210 loss: 0.014 Epoch 220 loss: 0.013 Epoch 230 loss: 0.012 Epoch 240 loss: 0.012 Epoch 250 loss: 0.011 Epoch 260 loss: 0.011 Epoch 270 loss: 0.010 Epoch 280 loss: 0.010 Epoch 290 loss: 0.009 Epoch 300 loss: 0.009 Epoch 310 loss: 0.009 Epoch 320 loss: 0.008 Epoch 330 loss: 0.008 Epoch 340 loss: 0.008 Epoch 350 loss: 0.008 Epoch 360 loss: 0.007 Epoch 370 loss: 0.007 Epoch 380 loss: 0.007 Epoch 390 loss: 0.007 Epoch 400 loss: 0.006 Epoch 410 loss: 0.006 Epoch 420 loss: 0.006 Epoch 430 loss: 0.006 Epoch 440 loss: 0.006 Epoch 450 loss: 0.006 Epoch 460 loss: 0.006 Epoch 470 loss: 0.005 Epoch 480 loss: 0.005 Epoch 490 loss: 0.005 Epoch 500 loss: 0.005 Epoch 510 loss: 0.005 Epoch 520 loss: 0.005 Epoch 530 loss: 0.005 Epoch 540 loss: 0.005 Epoch 550 loss: 0.005 Epoch 560 loss: 0.004 Epoch 570 loss: 0.004 Epoch 580 loss: 0.004 Epoch 590 loss: 0.004 Epoch 600 loss: 0.004 Epoch 610 loss: 0.004 Epoch 620 loss: 0.004 Epoch 630 loss: 0.004 Epoch 640 loss: 0.004 Epoch 650 loss: 0.004 Epoch 660 loss: 0.004 Epoch 670 loss: 0.004 Epoch 680 loss: 0.004 Epoch 690 loss: 0.003 Epoch 700 loss: 0.003 Epoch 710 loss: 0.003 Epoch 720 loss: 0.003 Epoch 730 loss: 0.003 Epoch 740 loss: 0.003 Epoch 750 loss: 0.003 Epoch 760 loss: 0.003 Epoch 770 loss: 0.003 Epoch 780 loss: 0.003 Epoch 790 loss: 0.003 Epoch 800 loss: 0.003 Epoch 810 loss: 0.003 Epoch 820 loss: 0.003 Epoch 830 loss: 0.003 Epoch 840 loss: 0.003 Epoch 850 loss: 0.003 Epoch 860 loss: 0.003 Epoch 870 loss: 0.003 Epoch 880 loss: 0.003 Epoch 890 loss: 0.003 Epoch 900 loss: 0.003 Epoch 910 loss: 0.003 Epoch 920 loss: 0.003 Epoch 930 loss: 0.003 Epoch 940 loss: 0.002 Epoch 950 loss: 0.002 Epoch 960 loss: 0.002 Epoch 970 loss: 0.002 Epoch 980 loss: 0.002 Epoch 990 loss: 0.002
network.feedforward([-25,-6])0.9660953631431157
